An automated workflow for generating subtitles for Thai tech talks. It has been tested with tech talks in Thai language. The generated subtitles achieve high accuracy, with word error rate (WER) around 0.5–2.5%.
Most automatic speech recognizers that support Thai language have troubles when it comes to technical talks. Most of them don’t know any technical term. Some can’t even spell a single English word. As a result, autogenerated captions from these systems tend to be unusable.
This workflow uses a combination of models:
- Speechmatics ASR — Transcribes Thai text with lower accuracy, but with highly-precise word-level timestamps.
- Gemini 1.5 Pro — This multimodal model can listen and watch a tech talk and generate a highly accurate transcript. Being mainly a language model, it knows a lot of technical terms. It can also handle the situation where the speaker speaks less common Thai words (such as words from northern Thai region). Being multimodal, it can read the slides in the video and generate transcripts more accurately. However, the model process media input in one second chunks, so it is not possible to obtain a precise timestamp. Moreover, it often hallucinates timecode, so the timing information from this model is unusable. It also tends to ignore formatting instructions in the prompt.
- Claude 3.5 Sonnet — Used to post-process the transcript to improve its formatting and readability. It can also fix some errors in the transcript.
Putting these models together created a subtitles file that has very little errors. I can review the subtitles by playing the talk at 2x speed and fixing the errors spotted. Previously, with a less a accurate transcript, I have to stop and fix the subtitle every few seconds. But now, with this workflow, sometimes a minute of reviewing can go by without me having to fix anything.
However, using this workflow can be quite expensive — it costs about 250 THB, or 7 USD, to process one hour of video. This cost can be cut in about half by processing just the audio, but without the video the transcription becomes slightly less accurate. (On the contrary, Speechmatics costs 0.3 USD per hour of audio.)
For examples of prompts and response from the models, see Prompt engineering section.
Warning
The code in this repository is very hacky and badly written.
Prompt for generating a transcriptPrompt: Output: |
Prompts for cleaning up the transcriptPrompt: Output: |
Prompts for alignmentPrompt: Output: |
- Node.js
- Bun
- tsx
- A tool that loads
.envfile into your environment, such as mise-en-place.
.env
SPEECHMATICS_API_KEY=
ANTHROPIC_API_KEY=
GEMINI_API_KEY=
OPENAI_API_KEY=-
Create a project folder.
mkdir projects/my-project cd projects/my-project -
Add an audio file.
-
Manually: Put an audio file as
audio.mp3in the project folder. -
Download from YouTube:
../../scripts/download_audio_from_youtube 'https://www.youtube.com/watch?v=vbIWSwz8NxQ'
-
-
Start server. This will show a URL to access the web interface.
bun ../../server/index.ts
-
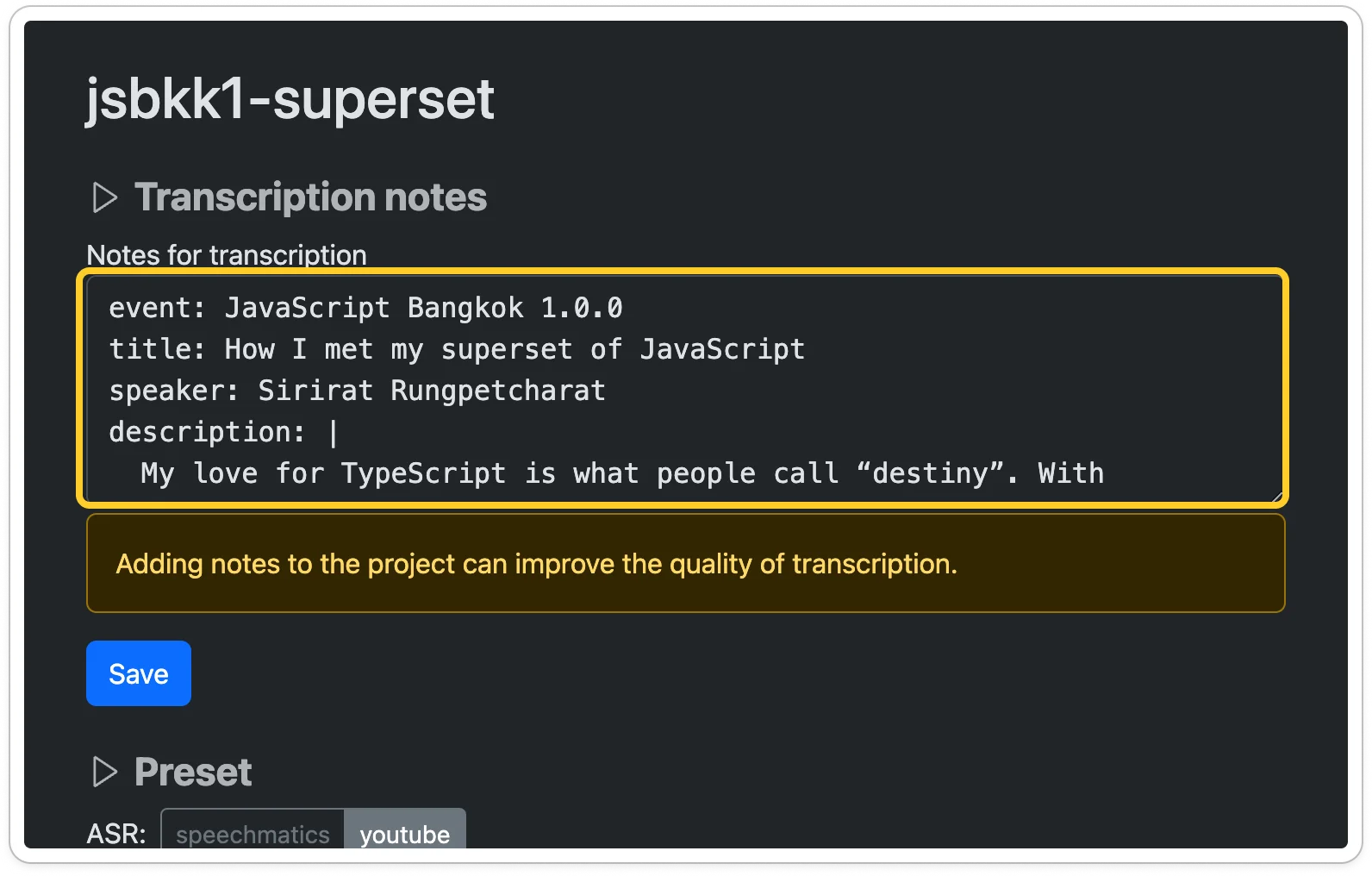
Enter transcription notes. This will help the model generate a more accurate transcript.
-
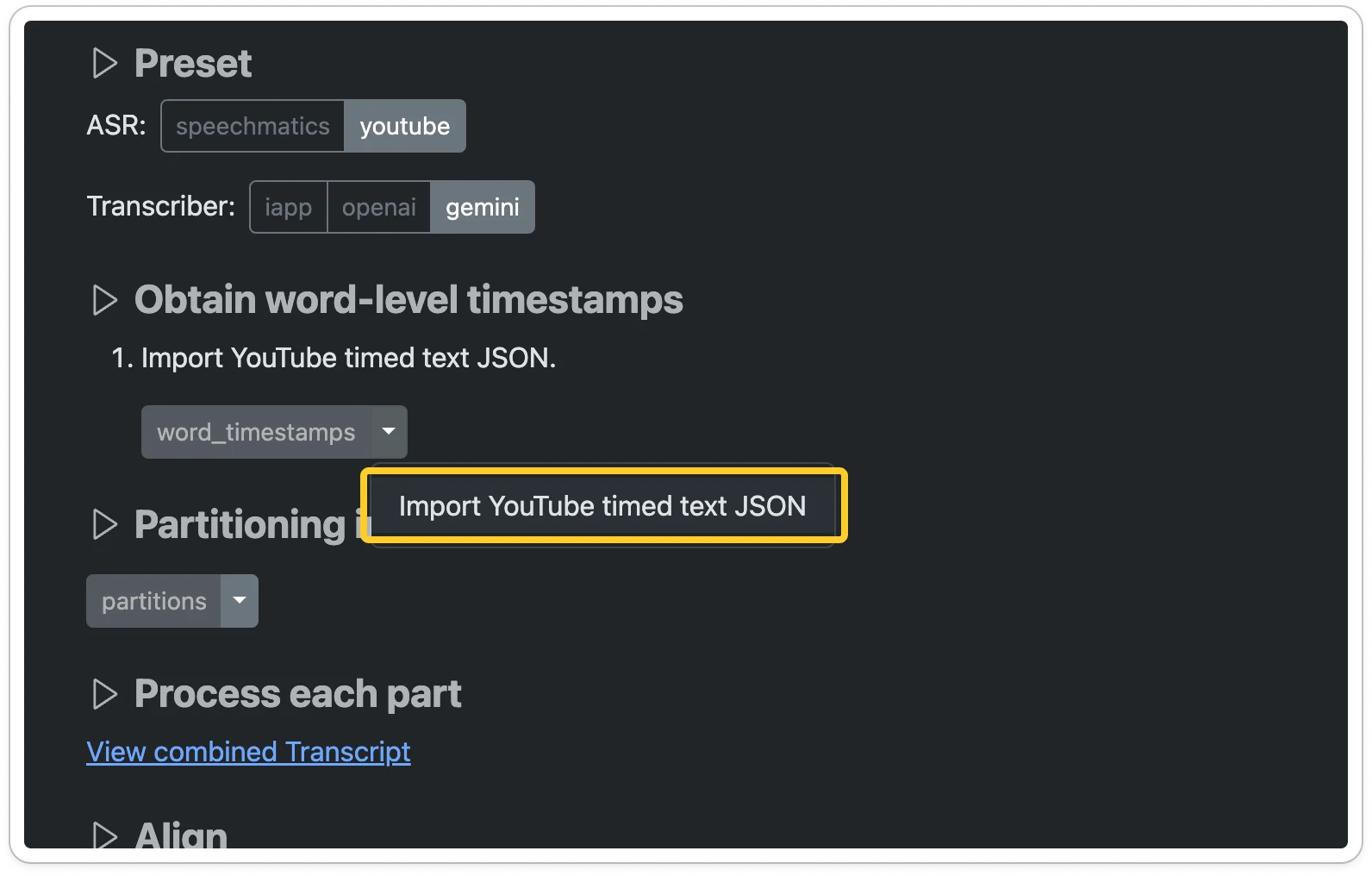
Obtain word-level timestamps. This will be used for partitioning the long audio file into smaller segments, as well as for aligning the transcript with the ASR output.
-
If the video is already on YouTube and it has already generate an automatic caption, you can import it directly.
-
Otherwise, switch the ASR preset to Speechmatics to use Speechmatics to obtain the word-level timestamps.
-
-
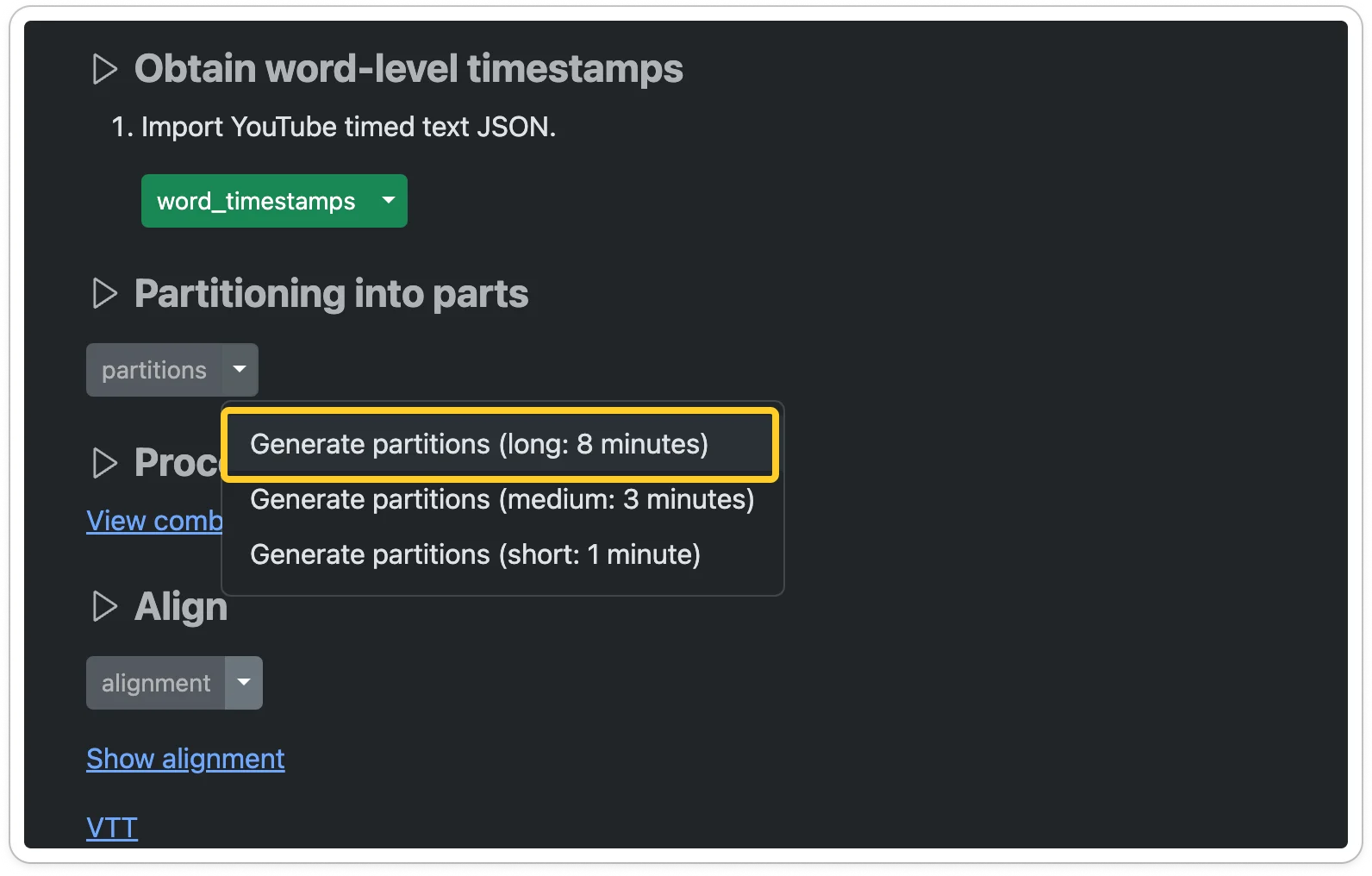
Generate partitions. This will split the audio file into smaller segments based on the gaps found in the audio, as determined by the word-level timestamps.
-
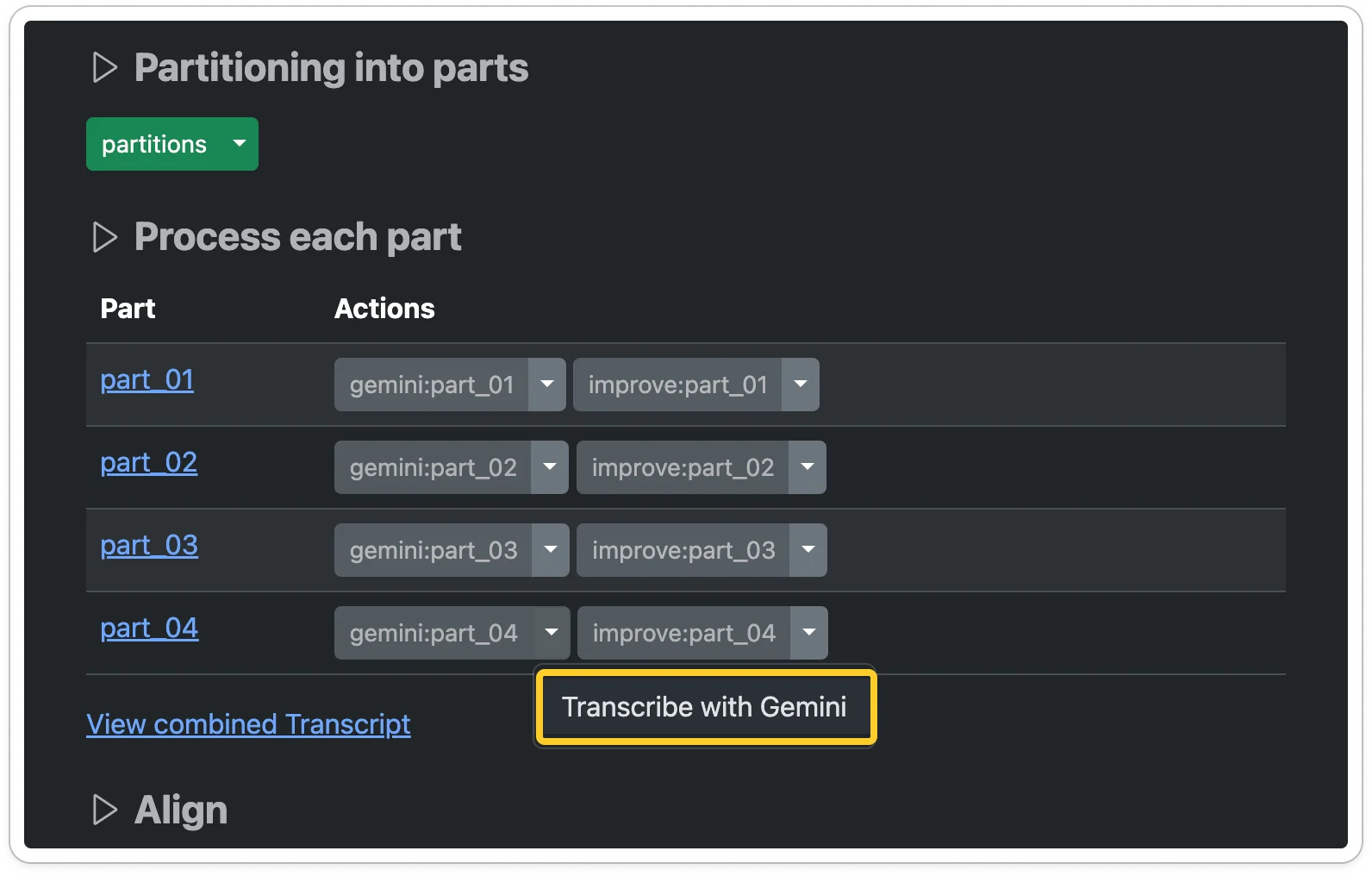
Transcribe with Gemini for each part. This will generate a transcript using the Gemini model.
[!TIP] Hold down the Alt key while clicking the menu item to perform the operation in the background. This lets you start multiple transcriptions more easily.
-
Once an initial transcript is generated, improve it with Claude.
-
Once all the parts have a transcript, align it.
-
Once the alignment process is done, you can obtain the resulting VTT file.
[!CAUTION] The generated VTT file may contain errors. Please review it before using it.