Quality Assurance (QA) também conhecido como Teste de QA é uma atividade que garante a melhor qualidade possível para um produto provido pela empresa ao consumidor
O Teste de QA em um software envolve a testagem de:
Performance
Adaptabilidade
Funcionalidade
Entretanto, a garantia de qualidade de software se extende além da qualidade do software em si. A atividade também compreende a qualidade do processo de:
Desenvolvimento
Testagem
Lançamento
O QA se debruça sobre o ciclo de desenvolvimento, que inclue a administração de requerimentos de software, design, codinig, testagem e lançamento
Vamos entender os fundamentos do teste de software, e como aplicá-los em nosso dia-a-dia.
Qualidade pode ser simplesmente definida como "é própio para seu uso ou função". A idéia é atender às necessidades e expectativas de clientes no que concerne a funcionalidade, design, confiabilidade, durabilidade e preço do produto
Garantia nada mais é do que uma declaração positiva de um produto ou serviço, que transmite confiança. É a seguridade de que dispõe um produto ou serviço no sentido de que este funcionará bem.
Provém a garantia de que funcionará sem quaisquer problemas de acordo com as expectativas e requerimentos.
Quality Assurance na Testagem é definida como um procedimento para garantir a qualidade de produtos de software ou serviços providos a clientes por uma empresa.
O QA foca em melhorar o procedimento de desenvolvimento do software, tornando-o eficiente e efetivo de acordo com os parâmetros de qualidade definidos para produtos de software.
Enquanto um engenheiro de QA, seu trabalho é procurar por pontos de falha em um produto, seja este qual for, e reportá-los para que sejam concertados, de forma que o produto possua a maior qualidade.
Para fazer sua função com sucesso, é necessário possuir o tipo de pensamento correto:
Pense da forma mais destrutiva e criativa quanto o possível
Pontos importantes:
Conheça o produto que vai testar
Não tenha medo de pensar fora da caixa enquanto o testa
Não tenha medo de usá-lo da forma mais errada quanto o possível
O software é culpado até que se prove o contrário.
O QA é o responsável por provar que o software é culpado.
Em técnicas de testes temos dois tipos de testes, os tradicionais e os ágeis.
Os testes tradicionais são baseados em um modelo de ciclo de vida em cascata, onde o teste é realizado após a construção do software, e o foco é encontrar defeitos.
Já os testes ágeis são baseados em um modelo de ciclo de vida iterativo e incremental, onde o teste é realizado durante a construção do software, e o foco é prevenir defeitos.
Teste demonstra a presença de defeitos, entretando, não garante sua inexistência.
Teste exaustivo é impossível: Devemos levar em consideração os riscos e prioridades da aplicação, de forma a pegar dos valores possíveis e provar a maior cobertura de testes.
Testes devem iniciar o quanto antes, uma vez que erros encontrados tarde custam mais para serem corrigidos
Prevenção de bugs, para que sejam identificados em fases iniciais, para redução de custos e esforços.
Garante que as expectativas do clientes sejam claras.
Aceita novas ideias.
O Tester é parte de um time.
A qualidade é responsabilidade do Time.
O teste é uma atividade do processo de desenvolvimento de software.
O QA tradicional tem como foco encontrar defeitos, detectar uma forma de quebrar o software.
O QA Ágil procura previnir erros, encontrar bugs nas primeiras etapas para otimizar a construção da aplicação, evitando retrabalho e minimizando riscos.
Comunicação face-a-face: O método mais eficaz de comunicação, é de forma presencial. Diferente do modelo tradional em que o tester não tinha acesso a outras partes do time, aqui, desenvolvedores estarão lado a lado com testers.
Feedback Contínuo: O trabalho com sprints pressupõe execução constante de testes, provendo feedback imediato e progressivo ao time.
Melhoria Contínua: Tanto de processos quanto de pessoas, valores de transparência, desenvolvimento profissional.
Ter Coragem
Entregar Valor para o Cliente: O tester precisa estar proximo do cliente, entender suas necessidades e traduzí-las em cenários de testes voltado ao business.
Manter Simples: A natureza do teste é validar o máximo de aspectos, entretando, é necessária a simplificação, priorização com base nas necessidades do cliente, uso de ferramentas mais leves, etc, de forma a otimizar o processo de desenvolvimento.
Responder a Mudanças: Adaptabilidade para novos cenários e condições que possam ocorrer ao longo das sprints, aprendizado de novas habilidades e atitudes que o tornem adptável.
Auto-Organização: Times ágeis se auto-organizam para resolver um problema da melhor forma, levando em consideração as habilidades de cada membro do time, esta dinâmica emerge do próprio time, e faz-se necessária a visão de autonomia e colaboração com o propósito do time.
Foco em Pessoas: A metodologia Ágil refere-se mais a pessoas, fator humano, do que fatores metódicos e burocráticos, aplicar todos os outros princípios e manter-se próximo aos demais membros do time com o objetivo de colaboração.
Divertir-se
Aqui, o tester tem papel atuante e fundamental para o desenvolvimento do produto, desde o entendimento das regras de negócio até a entrega do produto completo.
Deve agregar valor sendo uma referência de qualidade, o tester serve ao time e ao cliente utilizando-se de suas capacidades críticas e analíticas para buscar soluções para os problemas do time.
Ferramentas de Gestão de Projetos e Controle de Versões:
Utilizada em todo o processo de desenvolvimento, desde a definição dos requisitos e seu versionamento para separação de etapas, quanto ao versionamento de projeto para implementação segura e livre de riscos severos de funcionamento.
O controle de versões é aplicado com o objetivo de criar releases estáveis para fins de entrega ao cliente, enquanto o desenvolvimento não validado restringe-se a branches de teste. Desta forma, garantimos que sempre exista uma versão estável, livre de bugs e validada para caso uma feature implementada quebre o código.
Gestão de Testes: TestLink, permite a criação dos casos de teste e gerenciamento da execução destes testes, auxiliando a identificação de testes falhos ou que obtiveram sucesso, bem como designação de testes entre membros do time e supervisão da execução.
Gestão de Defeitos:
+Permite descrever a falha encontrada e atribuição de criticidade, designação de trabalho entre membros do time e rastreio do desenvolvimento, separação por status, inclusão de evidências de teste, etc.
Ferramentas de automação de testes são utilizadas para a execução de testes repetitivos, que não necessitam de intervenção humana, como testes de interface, testes de integração, testes de performance, testes de segurança, testes de regressão, etc.
+É um conceito amplo, variando entre linguagens de programações e diferentes metodologias para automação dos testes manuais.
JMeter: ferramenta que permite a criação de scripts de teste e simulação de diversos usuários, monitorando tempo de resposta, erros no serviço e fornecendo múltiplos relatórios.
Gatling: monitora a aplicação de forma contínua e alerta ao detectar erros e lentidões.
LoadComplete: une as duas funções permitindo elaboração de scripts e monitoração de funcionamento contínua.
BlazeMeter: permite criação de scripts de teste e simulação de usuários a partir de diversos servidores em diferentes partes do mundo.
Artefatos: Tipos de subprodutos concretos produzidos durante o desenvolvimento de software. Toda a documentação envolvida como casos de uso, requisitos, e documentação que descreve o design e arquitetura
O processo de inspeção envolve o planejamento, indivíduos revisando cada artefatos, encontros para debates e registros, passagem dos defeitos ao autor e avaliação geral acerca da necessidade de nova inspeção com base na existência de alterações durante o processo.
O termo defeito muitas vezes é utilizado de forma genérica, mas faz-se importante ter em mente que a interpretação depende do contexto de uso. Defeitos encontrados através de revisão, relacionam-se a faltas no artefato sendo revisado, falhas no software descritas no IEEE 830, 1998
A IEEE define atributos de qualidade que um documento de requisitos deve possuir, considerando a falta de qualquer dos atributos, caracteriza-se um tipo de defeito:
Omissões 1-5
+
1: Requisito imporante relacionado a funcionalidade, desempenho, interface externa.
2: Resposta do software para todas as possíveis situações de entrada de dados.
3: Falta de seções nas especificações do requisito.
4: Ausência de referência como figuras, tabelas ou diagramas, ao descrever um caso de uso ou especificação de software é comum a representação visual.
5: Falta de definicação de termos de unidade de medida, em um campo precisamos saber quantos caracteres suporta, input de texto e uma série de componentes que precisam de definição de unidade de medida, como numeral.
Ambiguidade: Um requisito com diversos significados em um termo para um contexto em particular, dificulta o entendimento da funcionalidade abrindo um grande leque para incidência de defeitos
Inconsistência: Mais de um requisito em conflito, ordens antagônicas para um mesmo contexto.
Fato Incorreto: Requisito que descreve um fato não verdadeiro considerando as condições estabelecidas para o sistema. Descrição pede A, retorna B
Informação Estranha: Informações fornecidas no requisito que não são necessárias ou sequer serão usadas, falta de eficiência na descrição, aumentando a documentação e abrindo margem para interpretações conflitantes.
Outros: Diversos, como a inclusão de um requisito em seção errada do documento, aplicação de regra em local errado, por exemplo.
Estas classes podem ser subdivididas em classificações mais específicas a depender da necessidade.
As inspeções localizam erros no início do processo, com o objetivo de previnir ao máximo o retrabalho nos ciclos posteriores, uma vez que os custos e dispêndio de tempo aumentam exponencialmente ao longo do ciclo de desenvolvimento.
Isto promove o aumento da produtividade no time, e gera artefatos mais inteligíveis facilitando a inspeção e gerando benefícios para fazes seguintes do ciclo, como a fase de manutenção das documentações.
Durante o processo de testes é necessário identificar o que deve ser testado, para isso, é necessário entender o que é um teste, e como ele é realizado.
Forma mais detalhada de documentar um teste, quando os scripts são mencionados, geralmente detalham linha a linha as ações e dados necessários para rodar o teste. Tipicamente tem etapas para entender como o usuario programa, quais ações e em qual ordem para executar, incluindo resultados específicos de cada etapa, como verificação de mudanças.
+A ação é clicar em botão X, o resultado é uma janela fechar. Ao iniciar o trabalho, não necessariamente o tester entende de forma aprofundada a função, os scripts auxiliam no desenvolvimento suave do processo e compreensão do sistema. Entretanto, devemos considerar que o projeto sempre sofre alterações, com páginas refeitas, novas funcionalidades, etc, portanto, os scripts devem ser sempre atualizados. O empecilho gerado nesta modalidade é que o tempo gasto para atualização do script poderia ser investido na execução de mais testes, além disso, são feitos para testar coisas muito específicas e repetitivas, abrindo margem para que bugs localizados nas margens deste caminho não sejam detectados, sendo necessária a evolução constante.
Segunda forma mais detalhada, descrevem uma ideia específica a ser testada, sem detalhar as etapas exatas a serem executadas. Por exemplo, testar se um código de desconto pode ser aplicado a produto em promoção, isto não descreve quais códigos serão utilizados, variando as abordagens utilizadas para encontrar o resultado. Proporciona maior flexibilidade de decisão ao tester para completar o teste, sendo benéfica para testers experiêntes e com boa compreensão da natureza e funções do sistema, entretanto, a ausência dessa familiaridade e experiência permite que bugs passem despercebidos.
Tipo menos detalhado de documentação, descrição de objetivo que o usuário pode encontrar ao utilizar o programa. Como por exemplo, testar se o usuário pode deslogar do programa ao fechá-lo, serão necessárias diversas técnicas para validar e testar a função apropriadamente, uma vez que os cenários oferecem pouca especificação o tester possui ampla flexibilidade para desenvolvimento do teste, esta flexibilidade oferece os mesmos prós e contras vistos nos casos de teste, sendo livre para o tester experiente e quase impossível ao profissional novato.
Pode ser feito o uso de todos estas modalidades, muitas vezes simultâneamente, e divida entre a equipe com base em suas diferentes habilidades e competências dentro do contexto específico do projeto.
Ao efetuar qualquer teste, a documentação mais atualizada deve ser solicitada, como casos de uso, regras de negócio e qualquer documentação relevante.
É importante, uma vez com as documentações em mãos, iniciar, terminar e reportar os casos de teste de forma contínua, evitando esquecimentos e retrabalho futuro.
# Casos de Teste, Relatos de Incidentes e Prioridades
Quando realizamos testes, é necessário que sejam escritos os casos de testes, para que possamos realizar os testes de forma organizada e padronizada. Devemos também relatar os incidentes encontrados, para que possamos corrigi-los e garantir a qualidade do software. Além de priorizar os incidentes encontrados, para que possamos corrigi-los de acordo com a sua importância.
# Como escrever casos de testes a partir de uma historia de usuário
O que são histórias de usuários
Explicação informal e geral sobre um recurso de software escrito a partir da perspectiva do usuário final, com o objetivo de articular como um recurso de software pode gerar valor ao cliente. Elas não são requisitos de sistema, são componentes chave no desenvolvimento que insere os usuários finais em ênfase, utilizam linguagem não-técnica para dar contexto a equipe de desenvolvimento, intruindo o que estão desenvolvendo e qual valor isso gerará ao usuário,
Possibilitam estrutura centrada no usuário, impulsionando a colaboração, criatividade e promovendo a qualidade do produto. Articulam como uma única tarefa pode oferecer um determinado valor ao cliente
São escritas em algumas frases com linguagem simples que delimitam o resultado desejado, os requisitos são adicionados mais tarde, uma vez que a equipe esteja de acordo com as histórias de usuário
Título: Deverá ser sucinto, simples e auto explicativo, com informações para que o analista saiba a qual validação o teste se propões (Validar Cadastro de Usuário, Envio de Ordem de Compra, etc).
Objetivo Detalhado: Descrever o que será executado, fornecendo visão geral do teste a ser realizado. Por exemplo, "Verificar se realiza o upload de arquivo com as extensões permitidas","Verificar se a ordem de compra é enviada informando ativo, quantidade, preço, etc";
Pré-Condições Necessárias para Execução: Evita que existam informações necessárias, como não informar que o usuário deve estar cadastrado para realização do teste. São os elementos fundamentais para que o teste seja executado corretamente, como a necessidade do usuário ter cadastrado nota anteriormente para testar a consulta. A ausência das pré condições, o teste será falho e ineficiente.
Passos Definidos: Descrevem todas as ações que o analista deve seguir durante a execução até chegar até o resultado esperado. "Acessar tal funcionalidade", "Clicar em tal botão", "Preencha formulário apresentado", "Verifique se foi apresentado formulário em branco".
Resultados Esperados: É a descrição do comportamento esperado do sistema após execução dos passos. "Válida","Apresenta", "Recupera", "Retorna". Deve ser direta e clara para evitar falsos positivos. "Sistema apresenta tela de edição com os campos preenchidos", "A ordem é enviada e resultada com preço informado", "Cadastro é salvo no banco de dados".
O caso deve ser autossuficiente, incluindo todas as informações necessárias para sua execução em seu próprio corpo. Deve ser conciso, otimizando o tempo de execução, como também devem possui o menor número de passos quanto o possível, facilitando a compreensão das etapas necessárias.
Também é necessário incluir com entradas válidas e não esperadas, bem como entradas válidas e esperadas.
Severidade: Define o grau ou intensidade de um defeito no que se refere ao seu impacto no software e seu funcionamento.
S1 - Crítica/ShowStopper: Bloqueio no teste ou funcionalidade que causa crash na aplicação ou principais caso de uso de funcionalidades chave, questões de segurança, perda grave no salvamento de dados. Bloqueios que impedem o teste de outras funções;
S2 - Grave: Problemas relacionados a informações inesperadas, defeitos indesejados, input incomum que cause efeitos irreversíveis, etc. A navegação é possível mas gera erros relevantes na função.
S3 - Moderada: A funcionalidade não atinge certos critérios de aceite, como mensagem de erro e sucesso não exibida.
S4 - Pequena: Gera pouco impacto, erros de interface, ortográficos, colunas desordenadas, falhas de design.
Resultados Esperados
Prioridade: Bugs vistos da perpectiva de negócio, quais devem ser corrigidos primeiro com base na demanda e contexto atual.
P1 - Crítico: Tem de ser solucionado imediatamente. Severidade 1, erros de desempenho, interface gráfica que afeta o usuário.
P2 - Alta: Funcionalidade não está usável como deveria por erros de código.
P3 - Média: Problemas que podem ser avaliados pelo desenvolvedor junto do tester para ciclo posterior a depender dos recursos disponíveis.
P4 - Baixa: Erros de texto, pequenas melhories de experiência e interface.
Caixa Preta: Requisitos e especificações, sem visão interna de funcionamento e estrutura do software, da parte funcional e sob a perspectiva do usuário
Caixa Branca: Baseada na estrutura interna, arquitetura e código fonte, podemos testar as unidades do sistema.
Caixa Cinza: Depuração de software, testador tem conhecimento limitado do funcionamento interno. Misto.
Metodologia de testes onde o cliente final é solicitado a usar o softwar para verificar sua facilidade de usa, percepção, desempenho do sistema, etc. Forma precisa de entender o ponto de vista do cliente, podendo ser utilizados protótipos mocks e etc.
#9) O que é cobertura e quais sãos os diferentes tipos de técnicas de cobertura?
Parâmetro para descrever até que ponto o código fonte é testado.
Cobertura de declaração: garante que cada linha de código foi executada e testada
Cobertura de decisão: todas os verdadeiro e falsos foram executadas e testados
Cobertura de Caminho: todas as rotas possíveis através de uma determinada parte do código foram executadas e testadas.
#10) Um defeito que poderia ter sido removido durante o estágio inicial é removido em um estágio posterior. Como isso afeta o custo?
O defeito deve ser removido o quanto antes, pois ao ser postergado o custo aumenta exponencialmente. A remoção em fases iniciais é mais barata e simples.
Regressão: confirma que uma alteração recente no código não afeta adversamente os recursos ja existentes
Confirmação: quando um teste falha devido a defeito, este é relatado, nova versão do software corrigido é enviado e o teste é novamente executado. É a confirmação da correção.
#12) Qual base em que você pode chegar a uma estimativa para o seu projeto
Para estimar o projeto deve-se considerar:
Dividir todo o projeto em tarefas menores:
Atribuir cada tarefa aos membros da equipe
Faça uma estimativa do esforço necessário para completar cada tarefa
Valide a estimativa
#13) Quais casos de teste são escritos primeiro: caixas brancas ou caixas pretas?
Normalmente os casos caixa preta são escritos primeiro.
Uma vez que estes necessitam somente dos documentos de requisitos e design, ou plano de projeto. Estes documentos estão facilmente disponíveis no início do projeto.
Já testes de caixa branca não podem ser executados na fase inicial do projeto pois precisam de maior clareza de arquitetura, que não está disponível em etapas iniciais. Portanto, são geralmente escritos depois dos testes caixa-preta.
#14) Mencione os componentes básicos do formato do relatório de defeitos
Cascateamento de defeitos ocorre quando um defeito é causado por outro defeito, um defeito adiciona o outro.
Quando um defeitos estiver presente em qualquer etapa, mas não for identificado, oculto para as outros fases sem ser notado, resultará em grande aumento no número de defeitos.
São majoritariamente detectados no teste de regressão
Errado: significa que os requisitos foram implementados incorretamente, é uma variação da especificação fornecida.
Ausente: Esta é variação das especificações, uma indicação de que uma especificação não foi implementada ou um requisito do cliente não foi anotado corretamente.
Extra: É um requisito incorporado ao produto que não foi fornecido pelo cliente final. É sempre uma variação da especificação, mas pode ser um atributo desejado pelo usuário do produto.
Documento de requisito: especifica o que exatamente é neecssário no projeto da perspectiva do cliente.
Entrada do Cliente: podem ser discussões, conversas informais, e-mail, etc.
Plano do Projeto: o plano do projeto preparado pleo gerente do projeto também serve como uma boa entrada para finalizar o teste de aceitação
#18) Por que o Selenium é a ferramenta preferida para testes de automação?
Selenium é uma ferramenta de código aberto que se destina a automatizar testes realizados em navegadores web. Como o Selenium é de código aberto, não há custo de licenciamento envolvido, o que é grande vantagem sobre outras ferramentas de teste. Outras razões são:
Os scripts de teste podem ser escritos em diversas linguagens de programação: Java, Python, C#, PHP, Ruby, Perl &, Internet
Os testes podem ser realizados em qualquer navegador: Mozilla, IE, Chrome, Safari ou Opera.
Ele pode ser integrado com ferramentas como TestNG, Junit para gerenciar casos de teste e gerar relatórios
Pode ser integrado com Maven, Jenkins & Docker para realizar testes contínuos.
#20) Quais são os diferentes tipos de localizadores no Selenium?
O localizador nada mais é que um endereço que identifica um elemento web exclusivamente dentro da página web. Assim, para identificar os elementos da web de forma precisa e, temos diferentes tipos de localizadores no Selenium da seguinte forma:
XPath, também chamado de XML Path é uma linguagem para consultar documentos XML. É uma estratégia imporatnte para localizar elementos no Selenium. Consiste em uma expressão de caminho junto com algumas condições. Aqui, voce pode escrever facilmente um script/consulta XPath para localizar qualquer elemento na página da web. Ele é projetado para permitir a navegação de documentos XML com o objetivo de selecionar elementos individuais, atributos ou alguma outra parte de um documento XML para processamento específico. Também produz localizadores confiáveis
#22) Qual a diferença entre Caminho Absoluto e Relativo?
XPath absoluto:
É a maneira direta de localizar o elemento, mas a desvantagem do XPath absoluto é que, se houver alguma alteração feita no caminho do elemento, o XPath falhará. Por exemplo:
/html/body/div[1]/section/div[1]/div
+
XPath Relativo:
Para XPath relativo, o caminho começa no meio da estrutura HTL DOM. Ele começa com barra dupla (//), o que significa que pode pesquisar o elemento em qualquer lugar da página da web. Por exemplo:
O Selenium Grid pode ser usado para executar scripts de teste iguais ou diferentes em várias plataformas e navegadores simultaneamente, de modo a obter execução de teste distribuida, testando em ambientes diferentes e economizando tempo de execução.
#24) Como eu inicio o navegador usando o WebDriver?
A seguinte sintaxe pode ser usada para iniciar o navegador:
WebDriver driver = new FirefoxDriver ()
Driver WebDriver = novo ChromeDriver()
Driver WebDriver = novo InternetExplorerDriver ()
#25) O teste deve ser feito somente após a conclusão das fases de construção e execução?
O teste é sempre feito após as fases de construção e execução. Quanto mais cedo detectarmos um defeito, mais econômico ele será. Por exemplo, consertar um defeito na manutenção é dez vezes mais caro do que consertá-lo durante a execuação.
#26) Qual a relação entre a realidade do ambiente e as fases de teste?
Conforme as fases de testes avançam, a realidade do ambiente se torna mais importante. Por exemplo, durante o teste de unidade, você precisa que o ambiente seja parcialmente real, mas na fase de aceitação você deve ter um ambiente 100% real, ou podemos dizer que deveria ser o ambiente real.
Normalmente, em testes aleatórios, os dados são gerados aleatoriamente, muitas vezes usando uma ferramenta. Por exemplo, a figura a seguir mostra como os dados gerados aleatoriamente são enviados ao sistema.
Esses dados são gerados usando uma ferramenta ou mecanismo automatizado. Com essa entrada aleatória, o sistema é então testado e os resultados observados.
#28) Quais casos de teste podem ser automatizados?
Teste de Fumaça
Teste de regressão
Teste de cálculo complexo
Testes baseados em dados
Teste não funcionais
#29) Com base em que você pode mapear o sucesso dos testes de automação?
Taxa de detecção de defeitos
Tempo de execução da automação e economia de tempo para lançar o produto
Redução de mão de obra e outros custos
#30) Como clicar em um hyperlink usando linkText()?
Este comando encontra o elemento usando o textos do link e, a seguir, clica no elemento. Assim, o usuário seria redirecionado para a página correspondente.
É uma estrutura avançada projetada de forma a aproveitar os benefícios dos desenvolvedores e testadores. Ele também possui um mecanismo de tratamento de exceções embutido que permite que o programa seja executado sem encerrar inesperadamente.
#32) Como definir a prioridade do caso de teste no TestNG
O código abaixo ajuda você a entender como definir a prioridade do caso de teste no TestNG:
```java
+ package TestNG;
+ import org.testing.annotation.*;
+
+ public class SettingPriority {
+ @Test(priority=0)
+ public void method1() {}
+
+ @Test(priority=1)
+ public void method2() {}
+
+ @Test(priority=2)
+ public void method3() {}
+ }
+ ```
+
Sequência de execução de teste:
Method1
Method2
Method3
#33) O que é repositório de objetos? Como podemos criar um repositório de objetos no Selenium?
O repositório de objetos refere-se à coleção de lementos da web pertencentes ao Application Under Test (AUT) junto com seus valores de localizador. Com relação ao Selenium, os objetos podem ser armazenados em uma planilha do Excel que pode ser preenchida dentro do script sempre que necessário.
#40) Como inserir texto na caixa de texto usando Selenium WebDriver?
Usando o método sendKeys() podemos inserir o texto na caixa de texto.
#41) Quais são as diferentes estratégias de distribuição para os usuários finais?
Piloto
Implementação Gradual
Implementação em Fases
Implementação Paralela
#42) Explique como você pode encontrar links quebrados em uma página usando o Selenium WebDriver
Suponha que entrevistador apresente 20 links em uma página web, e temos de verificar quais destes 20 links estão funcionando, e quais estão quebrados.
A solução é enviar solicitações HTTP a todos os links na página da web e analisar a resposta. Sempre que você usar o método driver.get() para navegar até uma URL, ele responderá com um status de 200-OK. Isso indica que o link está funcionando e foi obtido. Qualquer outro status indica que o link está quebrado
Primeiro, temos que usar as marcas âncora <a> para determinar os diferentes hiperlink na página da web.
Para cada tag <a> podemos usar o valor do atributo 'href' para obter os hiperlinks e então analisar a resposta recebida quando usado no método driver.get()
#43) Qual técnica deve ser considerada no script caso não haja ID ou nome do frame?
Se o nome e id do quadro não estiverem disponíveis, podemos usar quadro por índice. Por exemplo, caso existam 3 frames em uma páginda web, e nenhum deles tiver nome ou id de frame, podemos selecioná-los usando um atributo de índice de frame (baseado em zero).
Todo o quadro terá um número de índice, sendo o primeiro "0", o segundo "1" e o terceiro "2".
driver.switchTo().frame(int arg0);
+
#44) Como tirar screenshots no Selenium WebDriver?
Usando a função TakeScreenshot é possível efetuar a captura de tela. Com a ajuda do método getScreenshotAs() você pode salvar a captura efetuada.
#45) Explique como você logará em qualquer site se ele está mostrando qualquer pop-up de autenticação para nome de usuário e senha?
Se houver um pop-up para fazer login, precisamos usar o comando explícito e verificar se o alerta está realmente presente. O código a seguir a entender o uso do comando explícito.
Ele define uma amostra de variável do tipo WebElement e usa uma pesquisa Xpath para inicializá-la com uma referência a um elemento que contém o valor de texto "dados".
A testagem de uma aplicação é um processo que deve ser feito com bastante atenção, pois é através dela que podemos garantir que o software está funcionando corretamente, e que não há nenhum tipo de defeito que possa prejudicar o usuário. Porém, criar testes não é uma tarefa fácil. Existem duas maneiras que podem ser utilizadas para criar testes, cada uma com suas vantagens e desvantagens. São elas:
Proativa: onde o processo de design do teste é iniciado tão cedo quanto o possível para encontrar e corrigir erros antes que a build seja criada.
Reativos: abprdagem em que o teste não se inicia até após o design e desenvolvimento sejam completos.
Dadas essas duas maneiras, podemos dizer que a abordagem proativa é a mais recomendada, pois ela permite que os testes sejam criados antes do código, e assim, o desenvolvedor pode corrigir os erros antes que o código seja implementado. Por outro lado, a abordagem reativa é mais utilizada em projetos que possuem um cronograma apertado, pois ela permite que o desenvolvimento seja feito primeiro e depois os testes.
As abordagens de teste podem ser divididas em duas categorias, a caixa-preta e a caixa-branca. A diferença entre elas é que a caixa-preta foca no comportamento do sistema, enquanto a caixa-branca foca na estrutura interna do código.
Os testes de caixa-preta são os mais utilizados, pois eles são mais fáceis de serem implementados e não exigem conhecimento da linguagem de programação utilizada. Além disso, eles são mais fáceis de serem entendidos por pessoas que não possuem conhecimento técnico, e também são mais fáceis de serem implementados em diferentes linguagens de programação.
Os principais aspectos dos testes de caixa-preta são:
Foco principal na validação de regras de negócio funcionais.
Provém abstração ao código e foca no comportamento do sistema.
Testes de caixa-branca são mais difíceis de serem implementados, pois eles exigem conhecimento da linguagem de programação utilizada. Além disso, eles são mais difíceis de serem entendidos por pessoas que não possuem conhecimento técnico, e também são mais difíceis de serem implementados em diferentes linguagens de programação.
Alguns dos principais aspectos dos testes de caixa-branca são:
Valida estrutura interna e funcionamento de um código.
Conhecimento da linguagem de programação utilizada é essencial.
Alguns dos principais conceitos que define o teste de caixa branca são:
Envolve a testagem dos mecanismos internos de uma aplicação, o tester deve estar familiarizado com a linguagem de programação utilizada na aplicação que irá testar.
Código é visivel aos testers.
Identifica areas de um programa que não foram exercitadas por uma bateria de testes.
Técnica em que a estrutra interna, design e código são testados para verificar o fluxo input-output e melhorar o design, usabilidade e segurança.
Aqui, o código é visivel aos testers, também podendo ser chamado de teste da Caixa Transparente, Caixa Aberta, Caixa de vidro etc.
A primeira coisa que um tester geralmente fará é aprender e entender o código fonte da aplicação.
+Uma vez que teste Caixa Branca envolve a testagem dos mecanismos internos de uma aplicação, o tester deve estar familiarizado com a linguagem de programação utilizada na aplicação que irá testar.
+Além disso, o tester deve estar ciente de boas práticas do desenvolvimento de código.
+A segurança é muitas vezes um dos objetivos principais da testagem de software, o tester deve localizar brechas de segurança e previnir ataques de hackers e usuarios que podem infectar código maligno na aplicação.
O segundo passo básico para o teste de caixa branca envolve testar o código fonte para fluxo e estrutura apropriada.
Uma forma de fazer isso é escrevendo mais codigo para testar o código fonte.
O tester irá desenvolver pequenos testes para cada processo ou série de processos na aplicação, este método requer que o tester possua conhecimento intimo do código e muitas vezes é feito pelo dev
Outros métodos incluem testes manuais, tentativa e erro, e o uso de ferramentas de teste.
Vejamos um exemplo de teste de caixa branca em um código simples:
voidprintme(int a,int b){// Printme is a function
+ int result = a + b;
+
+ if(result >0)
+ print("Positive", result)
+ else
+ print("Negative", result)
+}// End of the source code
+
O objetivo do Caixa Branca em engenharia de software é verificar todas as ramificações de decisão, loops e statements no código.
Abaixo temos algumas technicas de analise de cobertura que um tester pode utilizar:
Cobertura de declarações: Esta técnica requer que todos os statements possíveis do código sejam testados ao menos uma vez durante o processo de testes.
Cobertura de execução: Esta técnica checa todos os caminhos possíveis (if/else e outros loops condicionais) de uma aplicação
Muitas vezes é o primeiro tipo de teste aplicado em um programa.
O teste unitário é performada em cada unidade ou bloco do código durante o seu desenvolvimento. É essencialmente realizado pelo dev, que desenvolve algumas linhas de código, uma unica função ou um objeto e testa para verificar que funciona antes de prosseguir.
Este tipo auxilia a identificar a maioria dos bugs nos estágios iniciais do desenvolvimento de um softare, sendo mais baratos e rapidos de concertar.
Vazamentos de memória são as principais causas de aplicações lentas. Um especialista em QA que é experiente em detectá-los é essencial em casos de uma aplicação que roda lento.
Neste teste, o tester/dev tem informação completa do código fonte, detalhes da network, endereços de IP envolvidos e toda a informação do servidor em que a aplicação roda.
+O objetivo é atacar o código por diversos angulos para expor ameaças de segurança.
O teste de caixa preta tem como objetivo verificar se o sistema sob verificação está funcionando corretamente, ou seja, se ele está de acordo com as regras de negócio e especificações do sistema.
Os testes de caixa-preta tem as seguintes características:
Teste em que as funcionalidades internas do código não estão disponíveis ao tester.
Feito da perspectiva do usuário.
Inteiramente focado nas regras de negócio e especificações da aplicação, também conhecido como teste Comportamental.
Para aplicar o teste de caixa-preta, o tester deve seguir os seguintes passos:
Inicialmente as regras de negócio e especificações são examinadas.
O tester escolhe inputs válidos (teste de cenário positivo) para checar se o sistema sob verificação processa-os corretamente. Também testando alguns inputsínvalidos (teste de cenário negativo) para verificar se o sistema detecta-os.
Tester determina os outputs esperados para cada um dos inputs selecionados.
Tester constrói casos de teste com os inputs selecionados.
Casos de teste são executados.
Tester compara os outputs factuais com os outputs ideais.
Defeitos, caso existam, são corrigidos e retestados.
Os testes de caixa-preta podem ser classificados em:
Teste Funcional: relacionado as regras de negócio de um sistema; é realizado pelos testers.
Teste Não-Funcional: não é relacionado com a testagem de qualquer feature específica, mas sim regras de negócio não-funcionais como performance, escalabilidade e usabilidade.
Teste de Regressão: esta modalidade é aplicada após quaisquer concertos, upgrades ou manutenções no código para verificar se estas não afetaram features previamente testadas com êxito.
As seguintes técnicas são usadas para testar um sistema:
Teste de Equivalencia de Classe: é usado para minimizar o número de possíveis casos de teste para um nível otimizado enquanto mantém razoável cobertura.
Análise do Valor-Limite: é focado nos valores em limites. Esta técnica determina se um certo escopo de valores é aceitável pelo sistema ou não, muito útil para reduzir o número de casos de teste. É mais apropriado para sistemas onde um input está dentro de determinados escopos.
Teste de Tabela de Decisão: uma tabela de decisões insere causas e seus efeitos em uma matriz, com uma combinação única em cada coluna.
Testes de caixa cinza são uma combinação de testes de caixa branca e de caixa preta. Eles são usados para testar um produto ou aplicação com conhecimento parcial da estrutura interna da aplicação. O propósito deste teste é procurar e identificar os defeitos gerados devido a estrutura ou uso impróprios da aplicação.
Algumas das principais características do teste de caixa cinza são:
É uma é uma junção dos métodos caixa branca (com conhecimento completo do código) e caixa preta (sem qualquer conhecimento do código).
O custo dos defeitos no sistema podem ser reduzidos ou previnidos ao aplicar a caixa cinza
É mais apropriados para teste de GUI, funcionais, de securança, aplicações web, etc.
Neste processo, erros de contexto específico que são relacionados a sistemas web são comumente identificados. Isso melhora a cobertura de testes ao concentrar em todas as camadas de qualquer sistema complexo
Em QA, o teste caixa cinza provém uma possibilidade de testar ambos os lados de uma aplicação, ou seja, tanto o front-end quanto o back-end.
Para performar um teste caixa cinza, não é necessário que o tester tenha acesso ao código fonte.
Um teste é designado baseado no conhecimento de algorítimo, estruturas, arquiteturas, estados interno ou outro tipo de descrição de alto nível do comportamento de um programa.
As principais técnicas usadas para o teste caixa cinza são:
Teste de Matriz: esta técnica de testes envolve definir todas as variáveis que existem em um programa.
Teste de Regressão: para checar se a mudança na versão anterior regrediu outros aspesctos do programa na nova versão. Isso será feito por estratégias de teste como retestar tudo, retestar features arriscadas e retestar dentro de um firewall.
Teste de Matriz ou Orientado a Ação (OAT): provê o máximo de cobvertyura de código com o mínimo de casos de teste.
Teste de Padrões: esta técnica é performada nos dados históricos da versão anterior dos defeitos no sistema. Ao contrário do teste caixa preta, o teste caixa cinza opera ao cavar dentro do código e determinar o motivo da falha acontecer.
Teste funcional é uma espécie de teste que valida o sistema contra especificações e regras de aceite.
+O propósito desta modalidade é testar cada uma das funções de um software provendo input apropriado e verificando o output de acordo com os requerimentos de funcionamento.
Vamos explorar algumas das principais técnicas de testes funcionais.
Técnica de teste que baseia-se em requisitos na documentação.
Executada através da abordagem caixa-preta, através dela o tester passa a ter noção clara da cobertura de testes a partir de requisitos e expecificações.
Não requer conhecimento dos caminhos internos, estrutura e implementação do software sobre testes, e reduz o número de casos de testes a um nível gerenciável, sendo intuitivamente utilizada pela maioria dos testadores.
O particionamento divide as entradas do usuário na aplicação em partições ou classes de equivalência, e então, as subdivide em faixas de valores possíveis, para que um destes valores seja eleito como base dos testes. Existem particões para:
Valores válidos, que devem ser aceitos pelo sistema.
Valores inválidos, que devem ser rejeitados pelo sistema.
Considere que em uma empresa exista um sistema de recursos humanos que processa pedidos de colaboradores com base na identidade.
Possuímos uma regra de negócios relacionada a identidade estabelendo que pessoas abaixo de 16 anos não podem trabalhar, indivíduos entre 16-60 anos estão aptos para contratação, e aqueles de 60 anos não são aptos a função.
Dividindo estas regras temos:
Partição inválida: 0-15
Partição válida: 16-60
Partição inválida: 60-
O particionamento de equivalência nos orienta a escolher um subconjunto de testes que encontrará mais defeitos do que um conjunto escolhido aleatóriamente.
Ao trabalhar com partições verificamos uma máxima que dita:
"Qualquer valor dentro de uma partição, é tão bom quanto qualquer outro"
+
Portanto, dados que pertençam a mesma partição devem ser tratados igualmente pelo sistema, ou seja, produzirão o mesmo resultado. Desta forma, qualquer valor dentro da classe de equivalência, em termos de testes, equivale a qualquer outro.
Para obtermos uma cobertura de testes satisfatória ao implementar esta técnica os casos de testes devem cobrir todas as partições existentes, no exemplo sob análise, verificamos 3 partições.
Um roteiro de testes para validação de idades no módulo de contratação possuiría 3 casos de testes:
C1: Idade = 5
De acordo com a regra, não poderia funcionar, o valor esperado é "Não deve contratar".
C2: Idade = 33
De acordo com a regra, pode trabalhar, o valor esperado é "Pode contratar".
C3: Idade = 65
De acordo com a regra, não pode trabalhar, o valor esperado é "Não deve contratar".
Subtende-se que dentra da faixa de valores 0-15, independentemente de qual selecionado dentro da partição inválida, não deve ser aceito pelo sistema, o mesmo se aplica a faixa de 16-60, diversas possibilidades que resultem em aceite no sistema.
Não faz-se necessário o teste de todos os valores possíveis, a cobertura é suficiente ao escolher um dentro de cada partição.
Parte do princípio que o comportamento na borda de uma partição tem maior probabilidade de apresentar erro.
No exemplo, com a técnica de valor limite selecionaríamos o valor 15, inválido pelo sistema, após, selecionamos o 16, limítrofe, mas que deve obter resultado positivo.
Uma boa prática de união das técnicas é selecionar um valor aleatório para cada partição, testar, e então validar os valores limítrofes dentre cada partição.
Tabela de Decisão:
Método relevante para documentação das regras de negócio a serem cumpridas pelo sistema, criadas a partir da análise de especificação funcional e identificação das regras de negócio.
A tabela contém condições de disparo, combinações de verdadeiro ou falso para entrada de dados e resultados para cada uma das combinações. É forma de expressar em forma de tabela qual conjunto de ações deve ocorrer para cheegar a um resultado esperado
O ponto principal da tabela é a regra de negocios, que define o conjunto de ações a serem tomadas a partir de um conjunto de condições.
No exemplo se sabemos que de 0-15 não deve trabalhar, na tabela estabelecemos que
0-15 Não Pode
16-60 Pode
Esta combinação pode, aquela não, é uma representação visual para aauxiliar a documentar as regras que o sistema segue.
Baseia-se que um sistema pode exibir diferentes comportamentos a depender de seu status atual ou eventos anteriores. A elaboração de um diagrama permite que o teste visualize os status, ou seja as transições, entrada de dados e eventos que acionam as ações
A técnica ajuda a identificar possíveis transações inválidas, pois ao sabermos o que o sistema espera, ao testar as combinações podemos descobrir transações defeituosas.
Uma pessoa pode estar apta a trabalhar, e passar a tornar-se inapta, inválida.
São aquelas em que os testes são derivados das habilidades e experiência do testador, a capacidade de visualização individuals do profissional, com base em seus trabalhos desenvolvidos no passado, que o possibilita a encontrar erros e falhas que talvez as outras não descubram.
O Teste de Aceitação do Usuário (UAT), ou muitas vezes chamado apenas de teste de aceitação é um tipo de teste aplicado pelo usuário final ou o cliente para verificar, e aceitar, o sistema antes de progredir a aplicação para o ambiente de produção.
O Teste de Aceitação é feito no final da fase de testes, após os testes de funcionamento, integração e sistema.
O principal objetivo do UAT é validar o fluxo do começo ao fim.
Ele não foca em erros cosméticos, de digitação ou teste do sistema, e é conduzido em um ambiente de testes separado com um setup semelhante ao ambiente de produção.
É parecido com o teste caixa-preta onde dois ou mais usuários finais estão envolvidos.
A necessidade deste teste surge uma vez que, tendo o software passado por teste de integração, sistemas, e unidade, podem ter os desenvolvedores construído o software baseado em regras de negócio documentadas sob seu próprio entendimento, havendo a chance de que demais mudanças necesárias durante esta fase não tenham sido eficientemente comunicadas a eles.
Logo, para verificar se o produto final é aceitável ao cliente/usuário, este teste faz-se necessário.
O plano de testes define a estratégia que será aplicada para verificar e garantir que a aplicação atinge as condições de aceite.
+Isto documenta critérios para entrada e saída do UAT, a abordagem dos cenários e casos de teste, bem como, a linha do tempo da testagem.
A identificação dos cenários respeitará o processo do business e criará casos de teste com passos claros.
+Os casos devem cobrir suficientemente a maioria dos cenários UAT.
+Os casos de uso do negócio são input para a criação dos casos de teste.
É recomendado utilizar dados em tempo real para o UAT.
+Os dados devem ser embaralhados por razões de segurança e privacidade.
+Testers devem estar familiarizados com o fluxo da database.
Analistas de Business ou UAT Testers precisam enviar uma declaração após a testagem. Com esta confirmação, o produto esta apto para prosseguir até a Produção.
+Entregas para o UAT são o Plano de Testes, cenários UAT e casos de testes, resultados e log de defeitos.
Testagem exploratória é avaliar um produto aprendendo sobre ele através de exploração e experimentação, incluindo:
Questionamento;
Estudo;
Modelagem;
Observação;
Inferência;
Muitas vezes descrito como aprendizagem simultânea, design de teste e execução. Foco na descoberta, e dependa da orientação do testador indivual para descobrir eventuais defeitos que não são abrangidos com facilidade no escopo de outros testes.
A maioria dos testes de qualidade de software usa uma abordagem estruturada, com casos de teste definidos segundo métricas como o histórico de usuários e parâmetros de engenharia de software, com uma projeção de cobertura adequada do ponto de vista técnico.
O que falta é cobertura para casos extremos, que são verificados no UAT e testados com base nas personas dos usuário. Já os testes Exploratórios são aleatórios, ou não estruturados, por natureza, e podem revelar bugs que não seriam descobertos nas modalidades estruturadas de testes.
A execução dos testes é implementada sem a criação de etapas formais, sendo, portanto, um precursor da automação.
Ajuda a formalizar as descobertas e fazer a documentação automática. Com o auxílio de feedback visual e ferramentas de teste colaborativo toda a equipe pode participar de testes exploratórios, permitindo uma rápida daptação às mudanças, promovendo um fluxo de trabalho ágil.
Além disso, o testador pode converter sequências de teste exploratório em scripts de testes funcionais, automatizando o processo.
Portanto, testes exploratórios aceleram a documentação, facilitam os testes unitários e ajudam a criar um ciclo de feedback instantâneo.
São adequados para cenários específicos, como quando alguem precisa aprender sobre um produto ou aplicativo com rapidez e fornecer feedback rápido. Eles ajudam a avaliar a qualidade sob a perspectiva do usuário.
Em muitos ciclos de software, uma iteração inicial é necessária quando as equipes não tem muito tempo para estruturar testes, testes exploratórios, são bastante úteis nesse cenário.
O teste exploratório garante que nenhum caso de falha crítica passe batido, garantindo a qualidade.
+Também auxiliam no processo de teste de unidade, podendo o tester documentar as etapas e usar essas informações para testar com maior amplitude em sprints posteriores.
É especialmente útil ao encontrar novos cenários de teste para aprimorar a cobertura.
As organizações devem ser capazes de atingir equilíbrio entre teste exploratório e com script. Sozinhos, os exploratórios não podem oferecer cobertura suficiente, sendo portanto, complementares aos com script em alguns casos.
Especialmente em testes regulamentados ou baseados em conformidade, que requerem o teste com script. Nestes casos, certas checklists e mandatos precisam ser seguidos por motivos legais, sendo preferível o teste com script.
Um exemplo são testes de acessibilidade que seguem protocolos legais, com padrões definidos que precisam ser aprovados.
// CI/CD: Continuous Integration/Continuous Delivery, método para entregar aplicações com frequência aos clientes. //
Testes exploratórios abrem os testes para todos, não apenas testadores treinados, assim, a revisão será mais rápida e eficiente, e poderá ser feita por pessoas além do tester tradicional.
Testes exploratórios complementam a estratégia de testes das equipes de QA, incluindo uma série de sessões de teste não documentadas para encontrar bugs ainda não descobertos.
Quando combinados com testes automatizados e outras práticas, aumentam a cobertura de testes, descobrindo casos extremo e adicionando, potencialmente, novos recursos e melhorias no produto.
Sem rigidez estrutural, estimulam a experimentação, a criatividade e a descoberta nas equipes.
A natureza quase instantânea de feedback ajuda a fechar lacunas entre testers e devs, mas acima de tudo, os resultados fornecem uma perspectiva orientada ao usuário e feedback para as equipes de devs.
O objetivo é complementar os testes tradicionais e localizar defeitos ocultos atrás do fluxo de trabalho tradicional.
É uma modalidade executada após o recebimento de uma build de software, com mudanças pequenas no codigo ou funcionalidade, para verificar que os bugs tenham sido corrigidos e que não foram introduzidos novos problemas.
O objetivo é assegurar que a funcionalidade proposta trabalha rudimentarmente como o esperado.
Caso falhe, a build é recusada para evitar o dispêndio de tempo e recursos que seriam envolvidos em uma testagem mais rigorosa.
O teste de sanidade é um subtipo do teste de regressão, e é aplicada para garantir que mudanças no código funcionam apropriadamente. É uma etapa para checar se a testagem da build pode prosseguir ou não.
O foco do time durante testes de sanidade é validar a funcionalidade da aplicação e não testagem detalhada.
É geralmente aplicado em uma build onde o implemento de produção é necessário imediatamente como uma correção de bug crítico.
Em um projeto de e-commerce, os módulos principais são página de login, página inicial e página de perfil do usuário.
Existe um defeito na página de login em que o campo de senha aceita menos do que 4 caracteres alfanuméricos e as regras de negócio mencionam que este campo não deveriam ser inferior a oito caracteres. Portanto, o defeito é reportado pelo QA para que o dev resolva.
O dev então corrige o problema e envia novamente para o time de testes para aprovação.
O QA checa se as mudanças feitas estão funcionando ou não.
Também é determinado se isso possui impacto em outras funcionalidades relacionadas. Supondo que agora exista uma funcionalidade para atualizar a senha na tela de perfil do usuário, como parte do teste de sanidade, a página de login é também validada, bem como a página de perfil para garantir que ambas funcionem bem com a adição da nova função.
É a modalidade de teste usado para confirmar que uma mudança recente no código não afetou de forma adversa outras features já existentes.
O testes de regressão é uma técnica de caixa preta, em que casos de teste são refeitos para verificar se funcionalidades anteriores da aplicação estão funcionando de forma adequada e que novas adições não produziram quaisquer bugs.
Ele pode ser aplicado em uma nova build quando existe uma mudança significativa na funcionalidade original, pois garante que o código ainda funciona uma vez que mudança ocorrem. Regressão significa "re-testar" essas partes da aplicação, que continuam sem alteração.
Testes de Regressão também são conhecidos como Método de Verificação, casos de teste são frequentemente automatizados, uma vez que precisam ser executadas repetidas vezes durante o processo de desenvolvimento.
Sempre que o código for modificado, como nos cenários a seguir:
Nova funcionalidade adicionada a aplicação
+Exemplo: Um site possui uma funcionalidade de login que permite login por Email. Agora provendo a opção de logar com o Facebook.
Quando existe um Requisito de Mudança
+Exemplo:
+Função "Lembrar senha" removida da página de login.
Quando um defeito é corrigido
+Exemplo:
+Foi encontrado e reportado bug, uma vez que o time de desenvolvimento tenha corrigido-o o time de QA irá testá-lo novamente para garantir que o problema foi resolvido. Simultaneamente testando demais funcionalidades relacionadas.
Quando existe uma correção para problemas de performance
+Exemplo: o loading de uma página inicial leva 5 segundos, e uma atualização o reduz para 2 segundos.
Quando existe uma mudança em Ambiente
+Exemplo: projeto sai do ambiente de Testes para o ambiente de Produção.
A necessidade para um teste de regressão surge quando uma manutenção no software inclúi melhorias, correções, otimizações ou remoção de features existentes.
Estas modificações podem afetar a funcionalidade do sistema, fazendo-se necessário a regressão.
O teste pode ser aplicado de acordo com as seguintes técnicas:
Se o software sofre mudanças constantes, os testes regressivos irão ficar cada vez mais custosos, assim como o tempo investido neste processo nos casos em que é feito manualmente.
Nestas situações, a automatização é a melhor escolha.
Selenium(opens new window): ferramenta open-source utilizada para a automação de testes em uma aplicação web. Para testes de regressão baseados em browsers, o Selenium é utilizado, assim como para regressõe a nível de UI.
# O que são o Teste de Regressão e a Administração de Configurações?
Administração de Configurações em testes regressivos torna-se imperativa em ambientes que apliquem a Metodologia Ágil, onde o código é continuamente alterado.
Para garantir um teste de regressão válido, devemos seguir os seguintes passos:
Mudanças no código não são permitidas durante a fase de teste regressivo.
Um caso de teste de regressão deve constituir-se de mudanças no desenvolvimento não afetadas.
A database utilisada para a regressão deve estar isolada, mudanças não são permitidas.
# Quais são as diferenças entre Re-testar e Teste de Regressão?
Re-Testar:
Significa testar a funcionalidade novamente para garantir a correção no código. Se não solucionada, defeitos devem ser re-abertos, se solucionada, o defeito é finalizado.
Re-testar é uma modalidade aplicada para checar se casos de teste infrutíferos na execução final, obtém sucesso uma vez que os defeitos foram corrigidos.
Re-testes trabalham para detectar correções.
A verificação de defeitos é parte do processo.
A prioridade é mais alta que a dos testes de regressão, sendo, portando, feitos antes.
É um teste planejado
Não pode ser automatizado
Teste de Regressão:
Significa testar a aplicação quando ela sofre uma mudança no código, para garantir que o novo código não afetou outras partes já existentes do software.
Não inclui verificação de defeitos
Baseado no tipo de projeto e disponibilidade de recursos o teste de regressão pode ser paralelo a Re-testagem.
É um teste genérico
Pode ser automatizado.
Checa por efeitos colaterais não previstos.
Ocorre quando há modificação, ou mudanças se tornam obrigatórias para o projeto.
É uma técnica de testagem em que unidades individuais ou componentes de um software são testados.
O propósito é validar se cada unidade do código funciona de forma satisfatória.
É aplicado durante a fase de desenvolvimento (fase de codificação) de uma aplicação pelos devs. Esta prática isola a seção de um código e verifica sua integridade, podendo ser uma função, método, procedimento, módulo ou objeto individuais.
Para executar esta técnica, desenvolvedores escrevem uma seção de código para testar uma função específcica na aplicação, podendo também isola-la para testes mais rigoros que revelam dependências desnecessárias entre a função sob testes e outras unidades, permitindo que sejam eliminadas.
Esta modalidade é comumente feita de forma automatizada, mas pode ainda ser realizada manualmente. Nenhuma das duas possui favoritismo, entretanto a automatização é preferível.
Acerca da abordagem automatizada:
O desenvolvedor elabora uma seção de código na aplicação apenas para testar a função.
O dev também poderia isolar a função para testagem mais rigorosa, o que ajuda a identificar dependências desnecessárias entre o codigo sob testes e demais unidades no produto.
Um coder gera os critérios para automação, de forma a validar que o código funciona. Durante a execução dos casos de teste o framework cataloga todas as falhas, com algumas ferramentas automaticamente reportando-as, e, dependendo da severidade, parando quaisquer demais testes.
O teste unitário depende da criação de mock objects para testar seções de código que ainda não são parte de uma aplicação completa. Os mocks preenchem as partes que faltam no programa.
Por exemplo, voce pode ter uma função que depende de variáveis ou objetos que ainda não foram criados. No teste unitário estas serão substituídas por mocks criados apenas para que o teste seja realizado na seção em questão.
Devs que buscam aprender qual funcionalidade é fornecida a partir de uma unidade e como usá-la, podem olhar os testes unitários novamente e adquirir uma copreensão básica da API;
Teste Unitário permite aos programadores refatorar o código em um estágio posterior, garantindo que o módulo ainda funcione corretamente (Teste de Regressão). O procedimento é escrever os casos de teste para todas as funções e métodos garantindo que novas mudanças falhas, possam ser rapidamente identificadas e corrigidas;
Devido a natureza modular do teste unitário, podemos testar partes do projeto sem esperar que outras sejam finalizadas (mocks);
Testes unitários não podem detectar todos os erros em um programa, não é possível avaliar todos os paths de execução mesmo nos mais triviais dos programas;
Devido a sua própria natureza, esta técnica foca em uma unidade de código, portanto, não pode detectar erros de integração ou falhas de amplo espectro do sistema.
É recomendado que esta abordagem de testes esteja aliada a demais técnicas.
Algumas das melhores práticas para o teste unitário são:
Os testes unitários devem ser independentes. Em caso de quaisquer melhorias ou mudanças nas regras de negócio, os testes devem permanecer inalterados;
Teste apenas um código por vez;
Siga diretrizes de nomenclatura claras e consistentes para as unidades de teste;
Em caso de mudanças no código ou em qualquer módulo, garnata que exista um caso de teste unitário correpondente, e que o módulo passe nos testes antes de alterar a implementação;
Bug identificados nesta técnicas devem ser corrigidos antes de proceder a demais fases do Ciclo de Desenvolvimento;
Adote uma postura de "teste enquanto coda". Quanto mais código for escrito sem testes, mais paths deverão ser verificados;
Técnica que verifica se a versão implantada do software está estável ou não.
Consiste em uma bateria mínima de teste aplicadas a cada build do software para verificar suas funcionalidades.
Também conhecido como "Teste de Verificação da Build" ou "Teste de Confiança".
+
Em termos simples o teste de fumaça valida se as features vitais estão funcionando e se não existem quaisquer showstoppers na build sob testes.
É um pequeno e rápido teste de regressão apenas para testar as principais funcionalidades, de forma a determinar se a build esta falha a ponto de tornar demais testes um desperdício de tempo e recursos.
Aplicado sempre que novas funcionalidades forem desenvolvidas e integradas com uma build já existente, que é então implantada no ambiente de QA, garantindo que todas as funcionalidades estejam, ou não, funcionando perfeitamente.
Caso a build seja positivamente verificada pelo time de QA no Teste de Fumaça, a equipe continua com a testagem funcional.
# Quais os motivos para aplicar o Teste de Fumaça?
Todos os showstoppers serão identificados aqui;
É feito após uma build ser encaminhada ao QA. Assim a maioria dos defeitos são identificados em estágios iniciais do desenvolvimento de software;
Com o teste de fumaça, nós simplificamos a detecção e correção dos principais defeitos;
Esta técnica é, geralmente, feita de forma manual embora exista a possibilidade de atingir o mesmo efeito através da automação. Pode variar de empresa pra empresa.
Testagem Manual:
+Realizado para garantir que a navegação de paths críticos esteja operando como esperando e não impeça a funcionalidade.
+Uma vez que a build é encaminhada ao QA, casos de teste de alta prioridade devem ser tomados para localizar defeitos principais no sistema.
+Caso a build seja aprovada, contniuamos a testagem funcional. Caso o teste falhe, a build é rejeitada e encaminhada de volta a equipe de desenvolvimento, recomeçando o ciclo.
Testagem Automatizada
+A automatização é utilizada para a testagem de regressão, entretanto, podemos também aplicá-la para casos de teste desta modalidade, agilizando todo o processo de verificação de novas builds.
+Ao invés do processo ineficiente de repetir todos os testes sempre que uma nova build for implementada, podemos automatizar os passos necessários, poupando tempo e recursos.
É um tipo de teste onde os módulos de software são logicamente integrados e testados como um grupo.
Um projeto de software típico consiste de múltiplos módulos, codificados por programadores diferentes, o propósito deste nível de teste é expor defeitos na interação entre estes módulos uma vez integrados.
+Esta técnica foca na validação da comunicação de dados entre estes módulos, também conhecido como I & T (Integration and Testing), String Testing, e, por vezes Thread Testing.
Embora cada módulo seja baseado em unidades, defeitos ainda existem por diversas razões:
Um módulo, no geral, é projetado por um dev individual, que pode possuir uma compreensão e lógica diferente de outros programadores;
No momento do desenvolvimento de um módulo, existes grandes chance de mudança nas regras de negócios por parte dos clientes. Estes novos requirementos podem não ser testados de forma unitário, e, portanto, o teste de integração do sistema se faz necessário;
A interface entre módulo e database pode ser errônea;
Interfaces de Hardware externo, caso existam, podem ser errõneas;
Administração inadequada de exceções podem causar erros;
O caso de testes de Integração difere de outras modalidades no sentido de que foca principalmente nas interface e fluxo de dados/informações entre os módulos.
A prioridade aqui são os links de integração ao invés das funções unitárias que ja foram testadas.
#Casos de teste de Integração entre Amostras para o seguinte cenário:
Aplicação possuí 3 módulos
Página de Login;
Caixa de Correio;
Deletar E-Mails;
Todos integrados lógicamente.
Aqui, não nos concentramos no teste da Página de Login já que os testes para esta feature já foram conduzidos no Teste Unitário, mas sim, checamos sua integração com a Caixa de Correio.
De forma semelhante, checamos a integração entre Caixa de Correio e o módulo Deletar E-Mails.
- Casos de teste:
+ - Caso 1
+ - Objetivo: Verificar o link de interface entre Login e Caixa de Correio;
+ - Descrição do Caso de Testes: Inserir credenciais de login e clicar no botão Login;
+ - Resultado Esperado: Ser direcionado até Caixa de Correio;
+ - Caso 2
+ - Objetivo: Checar o link de interface entre Caixa de Correio e Deletar E-Mails;
+ - Descrição do Caso: a partir de Caixa de Correio, selecione o e-mail e clique em um botão deletar;
+ - Resultado Esperado: e-mail selecionado aparecer na aba de deletados/lixo;
+
É uma abordagem no teste de integração em que todos os componentes ou módulos são integrados juntos de uma só vez e testados como uma unidade.
Este conjunto combinado de componentes é considerado como uma entidade durante os tstes, se todos os componentes na unidade não estão completos, a integração não sera executada.
Vantagens:
Conveniente para sistemas pequenos
Desvantagens:
Localização de falhas é dificil;
Dado o número de interfaces que precisam ser testadas neste método, algumas conexões de interface podem ser esquecidas facilmente;
Uma vez que o teste de integração pode começar apenas depois de "todos" os modulos foram arquitetados, o time de testes terá menos tempo para execução na fase de testes;
Dados que todos módulos são testados de uma vez, módulos críticos de alto risco não são isolados e testados com prioridade. Módulos periféricos que lidam com menos interfaces de usuários também não são isolados para testagem prioritária;
Nesta abordagem o teste é feito integrando dois ou mais módulos que são lógicamente relacionados entre si, e então, testados para funcionamento adequado da aplicação.
Então, os outros módulos relacionados são integrados incrementalmente e o processo continua até que todos os módulos lógicamente relacionados tenham sido testados com sucesso.
Stubs e Drivers:
+São os programas dummy utilizados para facilitar a atividades de testes. Estes programas agem como substitutos para os modelos faltantes no teste. Eles não implementam toda a lóica de programação do módulo mas simulam a comunicação de dados com o módulo calling durante os testes.
+ - Stub: é chamado pelo módulo sub testes.
+ - Driver: chama o módula para ser testado.
+
É a estratégia em que os módulos de mais baixo nível são testados primeiro.
Estes módulos já testados são então utilizados para facilitar o teste de módulos de nível mais alto. O processo continua até que todos os de nível máximo tenham sido verificados.
Uma vez que os módulos de nível baixo foram testados e integrados, o próximo nível de módulos é formado.
1. Vantagens:
+ - Localização de erros é mais fácil;
+ - Não perde-se tempo aguardando que todos os módulos sejam desenvolvidos como na abordagem Big-Bang
+2. Desvantagens:
+ - Módulos críticos (no nível máximo da arquitetura de software) que controlam o fluxo da aplicação são testados por ultimo e podem ser tendentes a defeitos;
+ - Um protótipo de estágio inicial não é possível;
+
Método em que a testagem se inicia do topo para baixo seguinto o fluxo de controle do sistema de software.
Os níveis mais altos são testados primeiro, seguindo então para os de nivel mais baixos, que são integrados para checar a funcionalidade do software. Stubs são utilizados para testar caso alguns módulos não estiverem prontos.
- Vantagens:
+ 1. Localização de falhas é mais fácil;
+ 2. Possibilidade de obter um protótipo;
+ 3. Módulos críticos são testados com prioridade, falhas maiores de design podem ser identificadas e corrigidas primeiro;
+- Desvantagens:
+ 1. Precisa de muitos Stubs;
+ 2. Módulos de nivel mais baixo são testados de forma inadequada;
+
Aqui, os módulos de mais alto nível são testados em conjunto com os de mais baixo nível, ao mesmo tempo, os mais baixos são integrados com os mais altos e testados como um sistema.
É a combinação do Top-down e do Bottom-up, portanto, é chamada de Testagem de Integração Híbrida.
Considere as seguintes práticas para testes de integração:
Primeiro, determine a estratégia de testes de integração que podem ser adotadas, e então, prepare os casos de teste e dados conforme.
Estude a arquitetura da aplicação e identifique os módulos críticos, para testagem prioritária;
Obtenha o design de interface do time de Arquitetura, crie os casos de teste para verificar todas as interfaces com detalhes. Interface para database/hardware externo/aplicações de software devem ser testadas com minúcia;
Após os casos de teste, são os dados de teste que desempenham papel fundamental;
Sempre tenha os dados de mock preparados, antes de executar. Não selecione dados de teste durante a execução dos casos de teste;
A testagem não funcional é um tipo de técnica para testar parâmetros não funcionais, como confiabilidade, carga de testes, performance e responsabilidade do software.
O propósito primário é testar a velocidade de leitura do sistema sob parâmetros não funcionais.
Estes parâmetros nunca são testados antes dos testes funcionais.
É essencial para confirmar que a confiabilidade e funcionalidade, as especificações de requerimentos do software servem de base para este método de testes, o que habilita os times de QA a checarem se o sistema esta em conformidade com os requerimentos de usuário.
Aumentar a usabilidade, efetividade, manutenibilidade e portabilidade do produto são os objetivos dos testes não-funcionais. Isso ajuda a deminuir os riscos de fabricação associados com os componentes não funcionais do produto.
É um tipo de teste de performance para o sistema ou produto de software sob condições de carga baseadas na vida real.
Aqui, determinamos o comportamento do sistema quando diversos usuários utilizam a aplicação ao mesmo tempo. É a resposta do sistema medida sob condições de carga variáveis.
Determinar se a mais recente infraestrutura é capaz de operar a aplicação, ou não;
Determinar a sustentabilidade da aplicação em face de carga extrema de usuários;
Descobrir a contagem total de usuários que podem acessar a aplicação ao mesmo tempo;
Determinar a escalabildiade da aplicação;
Permitir que mais usuários acessem a aplicação
Configuração do Ambiente de Testes: Primeiro, crie um ambiente dedicado a executar o teste de carga, isso garante que ele sera feito de forma apropriada;
Cenário de Teste de Carga: Aqui, os cenários são elaborados, e então, as transações de teste de carga são determinadas para a aplicação, e os dados são preparados para cada transação;
Execução dos Cenários de Teste: Diferentes medições e métricas são agrupados para coletar informação;
Análise dos Resultados;
Re-Testes: Caso um teste falhe, ele é realizado novamente para conseguir o resultado da forma correta.
As métricas são utilizas para conhecer a performance dos teste de carga sob circunstâncias diferentes. Isto nos diz o quão preciso o teste é em cada cenário diferente.
Existem muitas métricas, tais como:
Tempo de Resposta Médio: Mede o tempo que leva para resposta a partir de uma requisição gerada pelo cliente ou usuário. Também mostra a velocidade da aplicação dependendo de quanto tempo a resposta leva para todas as requisições feitas;
Taxa de Erro: É mencionado em termos de porcentagem e denota o numero de erros ocorridos durante as requisições para o total de requisições. Estes erros geralmente surgem quando o aplicativo não mais consegue suportar as requests no tempo dado, ou por demais problemas técnicos. Isto torna a aplicação menos eficiente quando a taxa de erros sobe;
Taxa de Transferência: Utilizada para auferir a quantidade de largura de banda consumida durante os scripts de carga ou testes, também usada para determinar a quantidade de datos que são usados para checar as requests que fluem entre o servidor do usuário e servidor principal da aplicação. É medido em kilobytes por segundo.
Resquests por Segundo: Nos diz quantas requests são geradas para o servidor do aplicativo por segundo. As requests podem ser qualquer coisa, desde requisições por imagens, documentos, paginas web, artigos ou quaisquer outras.
Usuários Simultâneos: Esta métrica é usada para determinar a quantidade de usuários que estejam ativamente presentes em um determinado, ou qualquer, horário. Isto apenas mantém registro da contagem daqueles que visitam a aplicação a qualquer momento, sem levantar request alguma dentro do aplicativo. A partir disto, podemos facilmente saber os horários de pico.
Pico de Tempo de Resposta: Mede o tempo levado para lidar com a request. Também auxilia a encontrar a duração do período de pico(o tempo mais longo) em que o ciclo request/resposta está levando mais tempo.
Teste de performance é um subgrupo da Engenharia de Performance, é um processo de avaliar o comportamento de um sistema sob diversas condições extremas.
O principal objetivo é monitorer e melhorar indicadores chave de performance, como tempo de resposta, taxa de transferência, memória, uso de CPU e mais.
Os três objetivos são:
Velocidade: Tempo de resposta a requests;
Escalabilidade: Carga de usuários máxima que a aplicação aguenta;
Estabilidade: Determina se a API é estável sob diversas cargas;
Features e Funcionalidades suportadas por um software não são as únicas preocupações. A performance de uma API, como o seu tempo de resposta, confiabilidade, uso de recursos e escalabilidade, também importam.
O objetivo não é localizar bugs mas sim eliminar gargalos de performance.
O teste é aplicado para prover os investidores com informações sobre suas aplicações, acerca dos fatores de performance. E, mais importante, o teste revela o que precisa ser melhorado antes do produto ir a mercado.
Sem este teste, o software provavelmente sofreria de problemas como, baixo desempenho sob stress, inconsistências entre diferentes sistemas operacionais e baixa usabilidade.
O teste determinará se o software atinge parâmetros de performance sob cargas de trabalho previstas. Aplicações enviadas ao mercados com baixas métricas de performance devido a testagem inexistente ou inadequada irão, provavelmente, adquirir uma má reputação, e não atingir seus objetivos de vendas.
Além disso,aplicações críticas como programas de lançamento espacial, equipamentos médicos e etc devem ser testados para performance a fim de garantir funcionalidade plena.
Teste de Carga: Checa a capacidade da aplicação de performar sob cargas de usuários previsíveis, para identificar gargalos antes que a aplicação seja lançada;
Teste de Stress: Envolve tester a aplicação sob cargas extremas, para auferir como o sistema lida com o tráfego e processamento de dados. O objetivo é identificar o ponto de ruptura da aplicação;
Teste de Spike: Testa a reação do software frente a um pico súbito na carga gerada por usuários;
Teste de Resistência: É feito para garantir que o software consiga lidar com a carga prevista durante um longo período de tempo;
Teste de Volume: Vasta quantidade de dados é inserida no database e o comportamento geral do sistema é monitorado. O objetivo é checar a performance em níveis diferentes de volumes na database;
Teste de Escalabilidade: Determina a efetividade do software sob cargas crescentes, de forma a comportar um aumento no número de usuários. Isto ajuda a planejar melhorias de capacidade para o sistema;
A maioria dos problemas de performance giram em torno de velocidade, tempo de resposta, tempo de load e baixa escalabilidade. A velocidade, é um dos atributos mais importante, uma aplicação lenta vai perder potenciais usuários. O teste de performance garante que um aplicativo seja executado rápido o suficiente para manter a atenção e interesse de um usuário. Na seguinte lista verificamos como a velocidade é um problema constante.
Alto Tempo de Carregamento: Tempo de load é normalmente o período que uma aplicação leva para iniciar, ele deveria, geralmente, ser o menor possível. Enquanto algumas aplicações são impossíveis de serem iniciadas em menos de um minuto, o tempo de carregamento deveria ficar abaixo de alguns segundos se possível;
Tempo de Resposta Inadequado: Aqui tratamos do tempo que leva entre um input do usuário e o output da aplicação para este input. Geralmente deveria ser muito rápido, pois novamente, se a espera for longa, o usuário perde interesse;
Baixa Escalabilidade: Um produto software sofre de baixa escalabilidade quando ele não suporta o número previsto de usuário ou quando não acomoda um espectro satisfatório de usuários;
Gargalo: São obstruções em um sistema que degradam a performance geral. Acontecem quando erros de código ou hardware causam uma diminuição na taxa de transferência sob certas cargas. A chave para localizar um problema de gargalo é encontrar a seção de código que gera a lentidão, e corrigí-la. O gargalo é comumente solucionado ao corrigir as linhas de código ou adicionar hardware. Alguns comuns são:
+
A metodologia adota para testes de performance podem variar, mas objetivo permanece.
Fluxograma genérico do teste de performance:
Identificar o Ambiente de Testes:
+Conheça o seu ambiente físico de testes, de produção e quais ferramentes de testes estão disponíveis. Entenda detalhes do hardware, software e configurações de networks usadas durante a testagem, antes de inicia-la. Este processo promove uma maior eficiência.
Identifique os Critérios de Aceite da Performance:
+Isto inclui objetivos e restrições da taxa de transferência, tempos de resposta e aloção de recuros. Também é necessário para identificar os critérios de sucesso do projeto além destes objetivos e restrições. Testers tambem devem estar empoderados para definir os critérios de performance e objetivos, uma vez que, geralmente, as especificações do projeto não incluirão uma variedade ampla o suficiente de benchmarks para performance. Quando possível encontrar uma aplicação similar para de fins de comparação pode auxiliar na definição dos objetivos de performance.
Planejamento e Design dos Testes de Performance:
+Determine o quanto a usabilidade irá variar entre os usuários finais para identificar cenários chave de testes para todos os casos de uso possíveis. É necessário simular uma variedade de usuários finais, planejar os dados para testes de performance e delimitar quais métricas serão coletadas.
Configuração do Ambiente de Testes:
+Prepare o ambiente de testes antes de sua execução, além disso, organize ferramentas e demais recursos.
Implemente o Design de Testes:
+Crie os testes de performance de acordo com o seu design original.
Execute os Testes
Analise, Ajuste e Reteste:
+Consolide, analise e compartilhe os resultados dos testes. Então, ajuste de forma específica e retestes para observar se existem melhorias ou declínios na performance. Uma vez que melhorias geralmente diminuem a cada teste, pare quando o gargalo é causado pela CPU. Para então poder considerar a opção de aumento do poder da CPU.
# Métricas do Teste de Performance: Parâmetros Monitorados
Uso do Processador: A quantidade de tempo que um processador gasta executando threads ativas;
Uso de Memória: Espaço físico disponível em memória para processos no computador;
Tempo de Disco: Período em que o disco ocupa-se para executar uma request de leitura ou escrita (read/write);
Bytes Privados: número de bytes que um processo alocou que não podem ser compartilhados entre demais processos. Estes são utilizados para medir vazamentos e uso de memória.
Memória Dedicada: quantidade de memória virtual utilizada;
Memory pages por segundo: Número de páginas escritas ou lidas a partir do disco com o objetivo de resolver falhas graves na página. Falhas graves identificam-se quando um código que não do grupo atualmente sob teste recebe um call de algum outro lugar e é buscado de um disco;
Falhas na Página por Segundo: A taxa geral em que falhas são processadas pelo processador. Novamente, ocorrem quando um processo requer código de fora do grupo sob teste;
Interrupções da CPU por Segundos: Número médio de interrupções no hardware que um processador esta recebendo e processando a cada segundo;
Comprimenta da Fila do Disco: Número médio de requests para read e writes na fila para o disco selecionado durante uma amostragem de tempo;
Comprimento da Fila do Output na Network: Comprimento da fila dos pacotes de output. Qualquer coisa superior a 2 significa um delay, e o gargalo precisa ser solucionado
Total de Bytes na Network por Segundo: Taxa em que bytes são enviados e recebidos na interface, incluindo caracteres de enquadramento;
Tempo de Resposta: Tempo entre a request do usuário e o recebimento do primeiro caracter da resposta;
Taxa de Transferência: Taxa em que um computador ou rede recebe requests por segundo;
Quantidade do Pool de Conexões: Número de requests de usuários que são atentidas por um pool de conexões. Quanto mais requests são atendidos por conexões na pool, melhor é a performance;
Máximo de Sessões Ativas;
Taxas de Acerto: Tem a ver com o número de statements SQL processados por dados em cache ao invez de operações I/O caras. Aqui é um bom ponto de partida para soluções de gargalo
Acertos por Segundo: O número de acertos um servidor web durante cada segundo de um teste de carga;
Segmento de Reversão: Quantidade de dados que podem ser revertidos a qualquer momento;
Travas da Database: O trancamento de tables e databases precisão ser monitorados e ajustados com cuidado;
Maiores Esperas: São monitoradas para determinar quais tempos de espera podem ser diminuídos ao lidas com o quão rápido os dados são buscados na memória;
Contagem de Threads: A saúde de uma aplicação pode ser medida pelo número de threads que estão ativas e em execução;
Coleta de Lixo: Refere-se ao retorno de memória não utilizada de volta ao sistema. A coleta de lixo precisa ser monitorada para eficiência;
É um tipo de testagem que verifica a estabilidade e confiabilidade de uma aplicação.
O objetivo é medir a robustez e capacidade de solução de erros de um software sob condições de carga extremas, garantindo que a aplicação não crashe em situações de stress. Aqui, testa-se além de pontos de operação usuais.
Em engenharia de Software, teste de stress também é conhecido como teste de resistência, teste sob stress, sobrecarregando o sistema por um período curto de tempo para validar sua capacidade de trabalho.
O uso mais proeminente da técnica é para determinar o limite, após o qual, um software ou sistema quebra, verificando também se o sistema demonstra solução de erros adequada sob condições extremas.
Considere as situações de vida real que se seguem para verificar a necessidade do Teste de Stress:
Durante um evento, um site de compras online pode experienciar um pico súbito no tráfego, ou quando anuncia uma promoção;
Quando um blog é mencionado em um jornal famoso, observa aumento súbito de acessos;
É imperativo que o teste de stress seja aplicado para acomodar estas situações anormais de tráfego, a falha na acomodação pode resultar na perda de renda e reputação.
Esta técnica também é extremamente importante pelas seguintes razões:
Checar se o sistema funciona em condições anormais;
Exibir uma mensagem de erro apropriada quando o sistema esta sob stress;
Falha do sistema em condições extremas pode resultar em lucros cessantes expressivos;
É melhor estar preparado para as situações de tráfego anormais;
Analisar o comportamento do sistema após uma falha, para obter sucesso, o sistema deve exibir uma mensagem de erro condizente com as condições de uso extremas.
Para conduzir um teste de stress, por vezes, enormes grupos de dados podem ser usados, e perdidos, durante a testagem. Testers não devem perder estes dados sigilosos durante o processo.
O principal propósito é garantir que o sistema recupere-se após uma falha, o que é chamado de recuperabilidade
Nesta modalidade o teste é feito através de todos os clientes do servidor.
A função do servidor de stress é distribuir um grupo de testes de stress por todos os clientes e rastrear os status de cada um. Após o cliente contatar o servidor, este adicionará o nome do cliente e enviará dados para teste.
Enquanto isso, as máquinas dos clientes enviam sinais de que estão conectadas com o servidor. Caso o servidor não receba quaisquer sinais das máquinas, ele precisar ser verificado para demais processos de debug.
Como verifica-se na imagem, o teste pode ser apenas em users específicos, ou de maneira geral, entre todos os clientes conectadas.
Integrações norturnas são a melhor opção para a execução destes cenários. Grupos de servidores grandes precisam de um metódo mais eficiente para determinar quais computadores tiveram falhas de stress que precisam de verificação..
Aplica o teste em uma ou mais transações entre duas ou mais aplicações. É utilizado para regulagem e otimização do sistema. É importante notar que uma transaction é expressivamente mais complexa do que uma request.
É o teste de stress integrado que pode ser aplicado em múltiplos sistemas rodando no mesmo servidor, utilizado para localizar defeitos em que uma aplicação gera bloqueio de dados na outra.
Aplicado para verificar o sistema em parâmetros não usuais ou condições que são improváveis de ocorrer em um cenário real.
+Utilizado para encontrar defeitos inesperados como:
Grande número de usuários logados ao mesmo tempo;
Se verificações de vírus são iniciados em todas as máquinas simultâneamente;
Se o banco dados ficou offline quando acessado a partir de um site;
Quando um vasto volume de dados é inserido na database de uma vez;
Planejamento do Teste de Stress: Coleta os dados, analisa o sistema e define os objetivos;
Criação dos Scripts de Automação: Nesta fase, cria-se os scripts de automação e são gerados os dados de teste para os cenários de stress;
Execução do Script e Armazenamento dos Resultados;
Análise dos Resultados;
Ajustes e Otimização: Nesta etapa, realizamos os ajustes finais no sistema, alteramos configurações e otimizamos o código com o objetivo de atingir a benchmark desejada
Por fim, reaplique o ciclo ajustado para verificar se estes produziram os resultados desejados. Por exemplo, não é incomum ter de aplicar 3 ou 4 ciclos do teste de stress para atingir a performance desejada.
É um tipo de Teste de Software que descobre vulnerabilidades, ameaças e riscos em uma aplicação de software, previnindo ataques de intrusos.
O propósito do Teste de Segurança é identificar todos as possíveis brechas e fraquezas no sistema que podem resultar em perda de informações, lucros e reputação nas mãos de colaboradores ou forasteiros da Organização.
Uma vez identificadas, as vulnerabilidades são verificadas de forma que o sistema não pare de funcionar e não possa ser explorado.
Confidencialidade: Limitando acesso ao acesso sensível administrado por um sistema.
Integridade: Garantindo que os dados são consistentes, precisos, e confiáveis através do ciclo de vida do software, e não pode ser modificado por usuários não-autorizados.
Autenticação: Verficando que dados ou sistemas sensíveis são protegidos por um mecanismo que verifica a identidade do usuário que os acessa.
Autorização: Definindo que todos os dados e sistemas sensíveis possuam contorle de acesso para usuários autenticados de acordo com seus papéis ou permissões.
Disponibilidade: Garantindo que dados e sistemais críticos ficam disponíveis para seus usuários quando necessários.
Não-Repúdio: Estabelece que um dado enviado ou recebido não pode ser negado, ao trocar informações de autenticação com um time stamp demonstrável.
Scan de Vulnerabilidades: Feito através de software automatizado para explorar o sistema em busca de assinaturas de vulnerabilidades;
Scan de Segurança: Envolve a identificação de fraquezas na rede e no sistema, provendo soluções para reduzir estes riscos. Este scan pode ser aplicado de forma manual ou automatizada;
Teste de Penetração: Esta modalidade simula ataques de hackers maliciosos. Aqui, envolvemos a análise de um sistema particular para verificar potenciais vulnerabilidades a ataques externos;
Avaliação de Risco: Esta técnica envolve a análise de riscos na segurança observados dentra da organização. Riscos são então classificados em baixo, médio e alto. Este teste recomenda controles e medidas para redução dos riscos;
Auditoria de Segurança: Inspeção interna de aplicações e Sistemas Operacionais por falhas na segurança. Uma auditoria também pode ser feita linha a linha no código;
Hacking Ético: Processo de hackear uma organização sem intenções malignas, mas sim, para expor e corrigir riscos de segurança do sistema;
Avaliação de Postura: Isto combina o scan de segurança, o hacking ético e a avaliação de riscos para demonstrar a postura de segurança geral de uma organização;
Tiger Box: Este método de hacking é geralmente feito em um laptop que possua uma coleção de sistemas operacionais e ferramentas de hacking. Este teste auxilia a testers de penetração a conduzir avaliação de vulnerabilidades e ataques.
Black Box: O tester está autorizado a performar os testes em tudo sobre a topologia da rede e tecnologia.
Grey Box: Informação parcial é fornecida ao tester sobre o sistema, é um híbrido.
É definido como um tipo de testagem aplicado para garantir que a aplicação em voga é usável por pessoas com condições como surdez, daltonismo, idade avançada, etc.
É um subgrupo do Teste de Usabilidade.
Estas pessoas fazem uso de assistentes, que os auxiliam a operar um produto de software, tais como:
Reconhecimento de Voz: Converte a língua falada em texto, que funciona como input para o computador;
Software de Leitura de Tela: Utilizado para ler o texto em exposição na tela;
Software de Aumento de Tela: Utilizado para aumentar o monitor, e deixar a leitura mais confortável para usuários com deficiência visual;
Teclado Adaptado: Feito para usuários com problemas motores, de forma a tornar seu uso mais fácil;
Atender ao Mercado:
+Com um quantidade expressiva de usuários com condições limitantes, o teste é aplicado para solucionar quaisquer impedividos de acessibilidade, sendo uma boa prática a inclusão desda técnica como parte normal do ciclo de desenvolvimento;
Conformidade com a Legislação Pertinente:
+Institutos governamentais do mundo todo produziram legislação no sentido de determinar que produtos em TI sejam acessíveis ao máximo de usuários possível.
Isto torna o teste de acessibilidade parte fundamental do processo, também por requerimentos legais.
Evitar POtenciais Litígios:
No passado, empresas do Fortune 500 foram processadas por seus produtos não serem acessíveis ao mercado.
Resta como melhor interesse da empresa que seus produtos sejam acessíveis como maneira de evitar processos no futuro.
Podendo ser manual, ou automatizado, a aplicação pode ser desafiadora para testers devido a não familiaridade com as possíveis deficiências.
É vantajoso trabalhar lado a lado com pessoas portadoras de deficiência, de forma que estas exponham necessidades específicas, promovendo um melhor entendimento de seus desafios.
Temos formas diferentes de testar, a depender de cada deficiência, tais como:
Aqui utiliza-se Softwares de Leitura de Tela, que narra o conteúdo em exibição para o osuário, tais como conteúdo, links, botões, iamgens, vídeos etc.
Em resumo, ao iniciar um destes softwares e acessar um website, ele irá narrar todo o conteúdo, tornando a navegação possível a pessoas com deficiência visual.
Um site mal desenvolvido, pode gerar conflitos com estes softwares, impedindo a narração correta e completa, e portanto, gerando inacessibilidade.
Por exemplo, devido a erro estrutural, o software não anuncia um link como tal, descrevendo-o apenas como texto e tornando impossível que o usuário o reconheça.
Importante ressaltar que nesta categoria também temos outras modalidades de deficiência visual, tais como baixa visão ou daltonismo.
No daltonismo a pessoa não é cega, mas não é capaz de visualizar algumas cores específicas. Vermelho e azul são casos comuns, tornando o acesso complexo caso o site seja baseado em uma dessas cores.
O design de um site deve levar isto em consideração, tomando por exemplo um botão em vermelho, que pode ser mais acessível ao possuir uma moldura em preto.
Já na baixa visão, o usuário também não é completamente cego, mas possui dificuldades ao enxergar.
A melhor coisa a se fazer é evitar textos muito pequenos, estruturar o site de tal forma que o usuário possa aplicar o zoom sem quebrar o layout, promovendo uma melhor experiência.
Um ponto extremamente imporante é considerar o acesso ao site sem o uso do mouse.
Um usuário deve poder ter completo acesso aos links, botões, pop-ups, dropdowns etc inteiramente a partir de atalhos no teclado.
O foco deve ser completamente visível, de forma que ao pressionar tab, o usuário possa observar para onde o controle se move, com foco visível tornamos o acesso possível para indivíduos com baixa visão ou daltonismo, permitindo a identificação do fluxo no site e promovendo facilidade de uso.
Por fim, é importante a observação de usuários com deficiências auditivas, como surdez ou baixa audição.
Aqui o usuário pode acessar o site e ver o seu conteúdo, mas encontra problema em audios e vídeos, tornando imperativo o alt text. O texto alternativo é o suplemento de um vídeo, ou seja, se o site apresenta um tutorial em vídeo para compra de passagens, também deve oferecer alternativa em texto, de forma que o usuário entenda o conteúdo do vídeo.
Compatibilidade nada mais é do que a capacidade de coexistir, no contexto de software, o teste de compatibilidade verifica se o seu software é capaz de ser executado em diferentes configurações de hardware, sistema operacional, aplicativos, ambientes de network ou dispositivos móveis.
Hardware: Verfica se o software é compatível com diferentes configurações de Hardware.
Sistema Operacional: Checa se o software funciona adequadamente em diferentes sistemas operacionais como Windows, Unix, Mac OS etc.
Software: Valida se a aplicação é compatível com outros softwares. Por exemplo, MS Word deve ser compatível com outros softwares como MS Outlook, MS excel, etc.
Network: Avaliação da performance de um sistema em uma rede com parâmetros variáveis, como largura de banda, velocidade de operação, capacidade, etc. Também valida a aplicação em diferentes redes com todos os parâmetros anteriores.
Browser: Checa a compatibilidade do site com diferentes navegadores como Firefox, Chrome, IE, etc.
Dispositivos: Verifica compatibilidade com plataformas móveis como Android, iOS etc.
Versões do Software: Consiste em verificar se a aplicação de software é compatível entre as diferentes versões. Como validar se o Microsoft Word é compatível com Windows 7, Windows 7 SP1, Windows 7 SP2, etc.
+Existem dois tipos de checagem da versão no Teste de Compatibilidade:
Teste de Compatibilidade com Versões Anteriores: Técnica que valida o comportamento e compatiblidade do software com suas versões anteriores de hardware ou software. Esta modalidade é bastante previsível uma vez que todas as mudanças entre versões são conhecidas.
Teste de Compatibilidade Futura: Processo que verifica o compartamento e compatibilidade da aplicação com novas versões de hardware ou software. É um processo mais complexo de prever, uma vez que as mudanças em novas versões são desconhecidas.
Desktops Virtuais-Compatibilidade de Sistemas Operacionais: Aplicada para executar a aplicação em múltiplos sistemas operacionais como máquinas virtuais, diversos sistemas podem ser conectados, e os resultados comparados.
A fase inicial da testagem é definir o grupo de ambientes ou plataformas que a aplicação deveria funcionar.
O tester deve possuir conhecimento suficiente das plataformas/software/hardware para compreender o comportamento esperado da aplicação sob diferentes configurações.
O ambiente deve ser configurado para testes com diferentes plataformas/dispositivos/redes para checar se a aplicação funciona corretamente.
Relatar bugs, corrigir defeitos e retestar para confirmar as correções aplicadas.
Um projeto é uma empreitada temporária com o objetivo de criar um produto, serviço ou resultado únicos.
O projeto é temporário pois tem prazo de começo e fim definidos, e é único pois possui um conjunto de operações designadas para atingir o objetivo.
A administração de projetos é a disciplina de planejar, organizar, motivar e controlar os recursos para atingir os objetivos do projeto, enquanto mantém em mente o escopo, tempo, qualidade e custos.
Isto facilita o fluxo de trabalho do time de colaboradores.
Um Plano de Testes é um documento detalhado que descreve a estratégia de testes, objetivos, agenda, estimativas, entregáveis e recursos necessários para desenvolver os testes em um produto de software.
O plano auxilia a determinar o esforço necessário para validar a qualidade da aplicação sob testes. Este plano funciona como um blueprint para conduzir as atividades de teste como um processo definido, o que é monitorado de perto e controlado pelo Gerente de Testes.
De acordo com a definição da ISTQB
"O Plano de Testes é um documento que descreve o escopo, abordagem, recursos e agenda das atividades de teste planejadas"
+
Os benefícios do documento Plano de Testes são variados:
Auxilia pessoas fora do time de teste, como desenvolvedores, gerentes de business e clientes a entender os detalhes da testagem.
O plano guia o raciocínio, é como um livro de regras a serem seguidas.
Aspectos importantes como estimativa de testes, escopo dos testes, estratégias, etc são documentadas no Plano, para que possam ser revisadas pelo Time de Gerência e reutilizada para outros projetos.
Como você pode testar um produto sem qualquer informação dele? Não pode. É necessário profunda familiaridade com um produto antes de testa-lo.
O produto sob testes é Guru99 Site Bancário. Deve-se pesquisar clientes, usuários finais e conhecer suas necessidades e expectativas do aplicativo.
Quem irá usar o Site?
Qual sua função?
Como funcionará?
Quais softwares/hardwares o produto utiliza?
A ideia é sondar o produto e revisar sua documentação, isto auxiliará a entender todas as features do projeto bem como sua usabilidade. Em caso de não entendimento, pode-se conduzir entrevistas com clientes, desenvolvedores e designers para maiores informações.
A Estratégia de Testes é um passo crítico ao elaborar um Plano de Testes dentro da testagem de software. Uma estratégia é documento de alto nível, que é geralmente desenvolvida pelo Gerente de Testes. O documento define:
Os objetivos de teste do projeto, bem como os meios para atingí-los.
Um tipo de teste é um procedimento padrão que provê um resultado esperado para os testes.
Cada tipo de testagem é formulada para identificar um tipo específico de bug no produto. Mas, todos os tipos possuem como alvo atingir o objetivo comum de identificação antecipada dos defeitos, antes do lançamento ao cliente.
Os tipos comumente utilizados são:
Teste Unitário: Verifica as menores partes de software verificável na aplicação
Teste de API: Valida a API criada para a aplicação
Teste de Integração: Módulos individuais são combinados e testados como um grupo
Teste de Sistemas: Conduzidos em um sistema completo e integrado para avaliar se está em conformidade com os requerimentos
Teste de Instalação/Desinstalação: Foca no que os clientes precisarão fazer para instalar/desinstalar e configurar/remover o novo software com sucesso
Teste Ágil: Avalia o sistema de acordo com a metodologia ágil
Existe uma infinidade de tipos de teste para o produto, deverá o Gerente de Testes definir a Priorização adequada, com base nas funções da aplicação e respeitando o orçamento definido.
Riscos são eventos futuros e incertos com probabilidade de ocorrência e potencial de perda. Quando o risco ocorre de fato, torna-se um "problema".
Exemplos de Riscos para documentação:
Membro da equipe não possui habilidade necessária: Planeje sessões de treinamento
O cronograma é apertado, tornando difícil completar os requisitos a tempo: Determine prioridade de testes para cada atividade
Gerente de Testes possui habilidades de gerência inadequadas: Planeje sessões de treinamento para lideranças
Uma falta de cooperação negativamente afeta a produtividade da equipe: Encoraje cada membro em suas tarefas, e inspire-os a maiores esforços
Estimativa de orçamento errada e custos adicionais: Estabeleça o escopo antes de iniciar o trabalho, preste atenção devida ao planejamento e constantemente meça os progressos
Na lógica de testes, o Gerente deverá responder as seguintes perguntas:
Quem irá testar?
Quando o teste irá ocorrer?
Você pode não conhecer exatamente os nomes de cada tester, mas o tipo de tester pode ser definido.
Para selecionar o membro correto para uma tarefa específica, deve-se considerar se suas habilidades qualificam-se para a tarefa ou não, também estimando o orçamento disponível. Selecionar errôneamente pode causar atrasos ou falha no projeto.
Possuir as seguintes habilidades é o mais ideal para aplicação de testes:
Capacidade de compreensão do ponto de vista dos clientes
Forte desejo por qualidade
Atenção a Detalhes
Boa cooperação
Em seu projeto, o tester irá tomar as rédeas da execução. Baseado no orçamento, pode-se selecionar terceirizações.
Quando o teste ocorrerá?
Atividades de teste devem ser associadas com atividades de desenvolvimento, devendo iniciar-se quando todos os itens necessários existirem.
Consiste no objetivo geral e conquista da melhor execução. O objetivo dos testes é encontrar tantos defeitos quanto o possível, garantindo que o software seja livre de bugs antes de seu lançamento.
Para definir objetivos, deve-se:
Listar todas as features (funcionalidade, performance, GUI, etc) que podem precisar de testes.
Definir o alvo, ou objetivo, do teste baseado nas características acima.
Especifique os critérios de suspensão críticos para um teste. Caso estes sejam atendidos durante a testagem, o ciclo de testes ativos será suspendido até que os critérios sejam solucionados.
Exemplo: Caso os relatórios da equipe indiquem que 40% dos casos falharam, você deve suspender a testagem até que o time de desenvolvimento corrija todos os casos.
Especificam as diretrizes que denotam sucesso em uma fase de testes. Os critérios de saída são resultados alvo dos testes, necessários antes de proceder para a proxima fase de desenvolvimento.
+Ex: 95% de todos os casos de teste críticos devem passar.
Alguns métodos para definir os critérios de saída consistem na especificação de taxas par execução e sucesso.
Taxa de execução: É a relação entre o número de casos de teste executados/total de casos.
Taxa de Sucesso: Relação entre número de testes que passaram/casos de teste executados.
Estes dados podem ser coletados em documentos de Metrica para Testes.
Taxa de Execução deve ne cessáriamente ser de 100%, a não ser que uma razão clara seja provida.
Taxa de Suceso depende do escopo do projeto, mas o ideal é que seja tão alta quanto o possível.
Planejamento de recursos é um sumário detalhado de todos os tipos de recursos necessários para completar um projeto de tarefa. Recursos podem ser humanos, equipamento e materiais necessários para finaliza um projeto.
O planejamento de recursos é fator importante para o planejamento de testes uma vez que auxilia a determinar o número de recursos a serem empregados no projeto. Portanto, o Gerente de Testes pode elaborar corretamente o cronograma e estimativas para o projeto.
Recursos Humanos:
+
Gerente de Teste:
+1. Administra todo o Projeto
+2. Define diretrizes
+3. Adquire os recursos necessários
+4. Identifica e descreve técnicas/ferramentas/arquitetura de automação apropriadas
Tester:
Executa os testes, cataloga resultados, reporta defeitos
Pode ser interno ou terceirizado, com base no orçamento disponível
Para tarefas que requeiram baixa especialização, é recomentdado o uso de equipe terceirizada para poupar custos
Desenvolvedor em Teste:
Implementa casos de testes, programa de testes, baterias etc.
Administrador de Testes:
Constrói e garante que Ambiente de Testes e seus recursos sejam administrados e recebam manutenção
Provê apoio ao Tester para uso do ambiente de testes
Membros SQA:
Responsável pelo Quality Assurance
Verifica e confirma se o processo de testes atende aos requerimentos especificados
Consiste em setup de software e hardware em que o time de teste desenvolve os casos. Caracteriza-se de um ambiente real de negócios e usuários, bem como ambientes físicos, como servidores e ambiente para execução de front-end.
Pressuponto cooperação entre time de desenvolvimento e time de testes, pergunte aos desenvolvedores todo o necessário para compreender a aplicação sob testes de forma clara.
Qual o máximo de usuários conectados ativamente o website pode aguentar de forma simultânea?
Qual os requerimentos de hardware/software para instalação do website?
O usuário precisa de alguma configuração específica para navegar no website?
Suponha que todo o projeto seja subdivido em tarefas menores e adicionados na estimativa da seguinte forma:
Criação das Especificações de Teste:
+
Elaborado pelo Desginer de Testes
170 horas de trabalho
Execução de Testes:
+
Tester, Administrador de Testes
80 horas de trabalho
Relatório de Testes:
+
Tester
10 horas de trabalho
Entrega de Testes:
+
20 horas de trabalho
Total: 280 Horas de Trabalho.
Assim, pode-se elaborar o cronograma para completar todas as tarefas.
Elaborar cronogramas é um termo comum em administração de projetos. Ao criar uma agenda solida no Planejamento de Testes, o Gerente pode usar como ferramenta para monitorar o progresso e controlar custos adicionais.
Para elaborar o cronograma de um projeto, o Gerente de Testes precisa de diversas informações, tais como:
Prazos de Funcionários e do Projeto: Dias de trabalho, prazo do projeto e recursos disponíveis são fatores que afetam o cronograma
Estimativa do Projeto: Com base na estimativa, o Gerente saberá quanto tempo será dispendido para completar o projeto. Podendo elaborar o cronograma apropriado
Riscos do Projeto: Compreender os riscos auxilia o Gerente a adicionar tempo extra suficiente ao cronograma para lidar com riscos
Entregáveis são uma lista de todos os documentos, ferramentas e outros componentes que precisam ser desenvolvidos e mantidos em apoio ao esforço de testes.
Existem diferentes entregáveis em todas as fases do desenvolvimento
Entregáveis são providenciados antes da fase de testes:
Documento Planos de Testes
Documento Casos de Teste
Especficiações do Design de Testes
Entregáveis providenciados durante a fase de testes:
Scripts de Teste
Simuladores
Dados de Testes
Matriz de Rastreabilidade de Teste
Logs de erros e execuções
Entregáveis providenciados após a fase de testes:
Resultados/Relatórios de Testes
Relatório de Defeitos
Instalação/Diretrizes dos Procedimentos de Testes.
A priorização é uma das formais mais eficientes para produzir produtos de alta qualidade de acordo com os padrões do mercado e de consumo.
É uma forma de priorizar e tabelar os casos do mais importante ao menos importante.
Minimiza custos, esforço e tempo durante a fase de testes.
É importante conhecer bem os benefícios, desafios e tecnicas de priorização dos casos para colher os melhores benefícios
Priorizar testes é ordenar os casos de testes a serem eventualmente conduzidos.
Priorizar os testes ajuda a satisfazar as limitações de tempo e orçamento na testagem para melhorar a taxa de detecção de falhas o mais rápido quanto o possível
Casos de teste que precisam ser executados, ou as consequências podem ser piores após o lançamento do produto. Estes são casos de teste críticos, onde as chances de uma funcionalidade ser quebrada por uma funcionalidade nova são mais prováveis.
Prioridade 2:
Casos que podem ser executados se houver tempo. Estes não são tão críticos, mas podem ser executados como uma medida de boas-práticas para dar um double check antes do lançamento.
Prioridade 3:
Casos de teste que não são importantes o suficiente para serem testados antes do lançamento atual. Estes podem ser testados depois, logo após o lançamento da versão atual do software, novamente, como uma medida de boas práticas. Entretanto, não há dependência direta para com eles.
Prioridade 4:
Casos que nunca são importantes, já que seu impacto é irrisório.
No esquema de priorização, a diretriz principal a ser seguida é garantir que os casos de baixa prioridade não devem causar impactos severos no software. Esta priorização deve possuir diversos objetivos, assim como:
Baseada na funcionalidade que já foi comunicada aos usuários e é crucial do ponto de vista do business.
Avaliar a probabilidade de falhas ao checar a taxa de detecção de falhas de uma categoria de testes. Isto ajuda a entender se esta categoria é crítica ou não.
Aumentar a cobertura de código do sistema sob testes com maior velocidade utilizando os critérios de cobertura usados anteriormente.
Aumentar a taxa de detcção de falhas críticas em uma categoria de teste ao localizar falhas similares que ocorreram mais cedo no processo de testes.
Aumentar a probabilidade de falhas serem reveladas devido a mudanças específicas no código anteriormente no processo de Teste de Regressão.
Aqui, os casos de teste são priorizados de acordo com o quão úteis eles serão para versions subsquentes do produto. Isto não requer qualquer conhecimento das versões modificadas, portanto, uma priorização geral pode ser aplicada logo após o lançamento de uma versão do programa fora do horário de pico. Devido a isso, o custo de aplicação desta categoria de priorização é amortizado durante lançamentos subsquentes.
Priorização de Casos de Teste Específica por Versão:
Nesta modalidade, priorizamos os casos de forma que eles serão úteis de acordo com cada versão do produto. Isto requer conhecimento de todas as mudanças que foram feitas no produto. É aplicado antes da testagem de regressão na versão modificada.
# Quais são as Diferentes Técnicas para Priorização?
Podemos priorizar os casos de teste de acordo com as seguintes técnicas:
Foca na cobertura de código pelos testes de acordo com as seguintes técnicas:
Cobertura Total de Extratos:
Aqui, o número total de extratos cobertos por um caso de testes é usado como fator para priorizar os testes. Por exemplo, um teste que cubra 5 extratos receberá prioridade sobre um que cubra somente 2
+
Cobertura de Extrato Adicional:
Esta técnica envolve selecionar iterativamente um caso de testes com o máximo de cobertura, e, então, selecionar um caso que cubra o que o anterior deixou de cobrir. O processo é repetido até que tudo esteja coberto.
Cobertura de Branches Total:
Aqui, branches se refere ao total de possibilidades de output em uma condição, e a maior cobertura destas é o fator determinante.
Cobertura de Branches Adicional:
De forma semelhante a cobertura de extratos adicional, aqui a técnica pega o teste com a maior cobertura de branches, e vai iterativamente selecionando os próximo de acordo com aqueles que o anterior não cobre.
Nesta técnica a priorização é feita com base em diversos fatores que determinam as regras de negócio. Estes fatores são documentados nas condições de aceite. Casos de teste são pensados considerando a prioridade assinalada pelo cliente para uma regra, sua complexidade e volatilidade.
Os fatores usados são:
Prioridade Indicada pelo Cliente: é a medida da importante de regras de negócio para um cliente sob o ponto de vista do business.
Volatividade da Regra de Negócio: indica quantas vezes a regra de negócios mudou.
Complexidade de Implementação: indica o esforço ou tempo necesário para implementar uma regra de negócio.
Tendência a erro: indica o quão passível de erro uma regra de negócio foi em versões anteriores do software.
Nesta técnica, a priorização é feita no histórico dos casos de teste, ou seja, os resultados das execuções anteriores são verificadas.
É usado para determinar as possíveis chances de falha nos testes e aqueles em que o erro é mais provável recebem prioridade. A verificação de histórico é utilizada para selecionais quais casos de testes poderiam ser considerados para retestagem no ciclo atual.
É um processo seguido para um projeto de software dentro de uma empresa. Consiste em um plano detalhado que descreve como desenvolver, manter, trocar, alterar ou melhorar partes específicas do software. O Ciclo define uma metodologia para melhorar a qualidade do softare e o processo geral de desenvolvimento.
Análise das regras de negócio é um dos estágios mais fundamentais no SLDC, é aplicado por membros sêniors no time com inputs dos clientes, departamento de vendas, pesquisas de mercado e especialistas na indústria. A informação é usada para planejar a abordagem básica do projeto e conduzir estudos de viabilidade do produto nas áreas econômicas, operacionais e técnicas.
Planejar para os requerimentos de garantia de qualidade e identificação de riscos associados com o projetos também é são feitos no estágio de planejamento. O Resultado dos estudos de viabilidade é definir as diversas abordagens técnicas que podem ser seguidas para implementar o projeto com sucesso, assumindo riscos mínimos.
Uma vez que a análise de requerimentos foi feita o próximo passo é definir e documentar claramente todas as regras de negócio e condições de aceite, recebendo a aprovação de clientes e analistas de mercado. Isto é feito através de um SRS (Software Requirement Specification) que consiste no design de todos os requerimentos do produto e seu desenvolvimento durante o ciclo de vida do projeto.
SRS é a referencia para arquitertos de produto desenvolverem a melhor arquitetura possível. Com base nos requerimentos especificados no SRS, geralmente mais de uma abordagem de design é proposta e documentada em um DDS (Design Document Specification)
Este DDS é revisado por todos os investidores majoritários e baseado em diversos parâmetros como análise de risco, robustez do produto, modularidade do design, orçamento e restrições de tempo, escolhe-se a mlehor abordagem para o produto.
Uma abordagem de design claramente define todos os módulos de arquitetura do produto junto de sua comunicação e representação do fluxo de dados com módulos externos (caso existam). O design interno de todos os módulos da arquitetura proposta devem ser claramente definidos com o máximo de detalhes no DDS.
Aqui, o desenvolvimento propriamente dito começa, e o produto é construído
+O código de programação é gerado de acordo com o DDS neste estágio. Se o design é aplicado de forma detalhada e organisada, a geração de código pode ser concluída sem maiores dificuldades.
Desenvolvedores devem conhecers as diretrizes de código definidas por sua organização, bem como as ferramentas pertinentes. A linguagem de programação a ser utilizada é definida de acordo com o software a ser desenvolvido.
Esta etapa é geralmente um subtipo de todos os estágios em modelos modernos de SLDC. Entretanto, esta etapa regere-se apenas a testagem do produto, onde defeitos são localizados, reportados, catalogados, corrigidos e validados, até que o produto atinja os maiores padrões de qualidade.
Uma vez que o produto é testado e esta pronto para ser implementado, ele é formalmente lançado a mercado. Por vezes a implementação de produto acontece em estágios, de acordo com a estratégia de negócios da organização. O produto pode ser lançado primeiro em um segmento limitado, e testado no ambiente de negócios real (UAT).
Então, baseado em feedback, o produto pode ser lançado como estiver, ou com melhorias sugeridas pelo mercado alvo. Uma vez lançado no mercado, sua manutenção é feita com foco na base de usuários existentes.
Existem diversos modelos definidos e arquitetados que são seguidos durante o processo de desenvolvimento. Estes modelos também são chamados de Software Development Process Models. Cada modelo de processo segue uma serie de passos única para garantir o sucesso nos processos de desenvolvimento.
O QA possui papel fundamental no processo que deve ser implementando no ciclo de desenvolemento.
Sua principal função é garantir que o softawre atenda as regras de negócio, esteja livre de bugs e funcione perfeitamente sob diferentes circunstâncias.
Para a atual realidade de mercado, em que um produto ficará disponível em diversos modais, e é crítico que seja desenvolvido sem defeitos. Aqui entra o QA.
O QA em TI é integrado em todos os estágios de desenvolvimento, e é usado mesmo após o estágio de lançamento.
Especialistas em QA criam e implementam diversas estratégias para melhoria de qualidade de software, aplicando diversos tipos de teste para garantir correta funcionalidade, este estágio é chamado de Controle de Qualidade (QC).
Podendo de empresa para empresa, as principais funções são:
Analista de QA: Posição proxima ao analista de negócios, coleta todas as informações do projeto, avalia riscos e pontos fracos, e cria documentações para descrever aspectos futuros do desenvolvimento que Engenheiros de QA devem atenter-se.
Lider de QA: A liderança do time é a pessoa que controla toda a equipe de especialistas. Além disso, o lead administra testes, cria planos de teste, processa a informação recebida de analistas, observa todos os prazos para garantir uma testagem oportuna.
Engenheiro de QA: Este especialista aplica os testes e faz tudo para melhorar a qualidade geral do software, deixando-o em conformidade com as regras de negócio.
O escopo de tarefas do QA deve ser bastante amplo. O time de quality assurance mais uma vez prova sua importância no SLDC.
Planejamentos de Testes: Os analistas planejam o processo de testes, com seus objetivos a atingir e quais abordagens usar.
Testes Iniciais: Engenheiros de QA conduzem a testagem inicial para identificar bugs durante a primeira fase de desenvolvimento, de forma a acelerá-la.
Execução de Testes: Engenheiros de QA aplicam testes manuais ou automatizados de diferentes tipos em acordo com as particularidades do software.
Análise de Defeitos: É necessário analisar todos os defeitos e identificar a razão de sua ocorrência.
Relatórios: Especialistas usam sistemas para o rastreio de bugs e criam relatórios para os desenvolvedores com descrições ods bugs e defeitos a serem corrigidos.
Colaboração: O time de QA colabora com analsitas de negócio, gerentes de projeto, devs e clientes para atingir a maior qualidade possível para um produto de software.
Sumário de Testes e Criação de Reports: Quando um software é testado, engenheiros de QA precisam criar um sumário dos relatórios para demonstrar o nível de qualidade do software.
# Qual é o Papel do QA em Desenvolvimento de Projeto?
Quality Assurance no ciclo de vida de desenvolvimento desempenha papel crucial em todos os estágios, como por exemplo:
Análise de Requerimentos: Em TI, o time de QA colabora com analistas de negócio para desenvolver um estudo de viabilidade das regras de negócio, análise de possíveis riscos, criação de plano de teste e construção da estratégia para a abordagem utilizada na garantia de qualidade (cada projeto requer uma abordagem individual devido as suas particularidades), quais testes usar, etc.
Design: É necessario revisão o design, verificar sua estabilidade, checar se sua arquitetura atende todos os requerimentos. Além disso, especialistas de QA produzem diagramas de fluxo de dados em conjunto com designers UI/UX e documentam-os. Por fim, engenheiros de QA testam testam o design após a sua conclusão para imitar o comportamento do usuário final.
Desenvolvimento> QA no desenvolvimento de softwares pode ser aplicada uma vez que o software, ou de acordo com a abordagem TDD (Test Driven Development), que define testagens durante o processo de desenvolvimento após cada iteração.
QA Pós Lançamento: Uma vez lançado, desenvolvedores devem realizar a manutenção do produto, o time de QA cria, então, guias de usuário e manuais do produto para entrega ao usuário final. Elaborando também documentação de testes para garantir que todos os bugs tenham sido identificados e tudo esteja corrijido.
Poupa Recursos e Preserva Reputação: Sendo esta última uma das mais importantes. Por exemplo, se você desenvolve um software de trading, e não testou-o corretamente, usuários perderiam dinheiro, e mesmo compensados por suas perdas seria impossível salvar a reputação de seu produto. Portanto, a garantia de qualidade auxilia a detectar bugs antes que usuários os encontrem.
Previne Emergências: Imagine que voce encomenda o desenvolvimento de um softare para uso interno, e seus funcionários irão usá-lo para melhor comunicação com clientes. Um bug, mesmo que pequeno, pode levar a severas falhas como perda de dados e quebras de comunicação. Então, será mais complexo recuperar essas informações sem despesas adicionais.
Aumenta a Fidelidade de Clientes: Um software livre de bugs significa que clientes não enfrentam problemas au utilizar seu aplicativo. Além disso, se você responde as reclamções de clientes e corrige problemas rapidamente, sua clientela verá que os respeita e aspira aos mais altos niveis de qualidade. Como resultados, sua base de clientes é fidelizada, lucro adicional.
Impacta na Produtividade dos Colaboradores: Funcionários podem trabalhar melhor e mais eficientemente quando obstaculos como bugs de software não ficam em seu caminho. Colaboradores, portanto, não perdem tempo tentando descobrir motivos por trás de falhas no software e outros desafios para continuar o trabaho.
Torna o Software Mais Seguro: Por fim, a garantia de qualidade contribui para uma aplicação mais segura, elminando vulnerabilidades e defeitos, previnindo ataques maliciosos. O custo dos serviços de QA é incomparável a potenciais perdas financeiras que um empreendimento pode sofrer devido a falta de proteção confiável.
A metodologia ágil consiste em prática que promove a iteração contínua de desenvolvimento e teste através do SLDC no projeto. Na metodologia Ágil dentro do teste de software, tanto desenvolvimento quanto testes são concomitântes, ao contrário do modelo cascata.
# Em que Consiste o Desenvolvimento de Software Ágil?
Esta metodologia é uma das mais simples e eficientes para tornar a visão das necessidades de um negócio em soluções de software. Ágil é um temro usado para descrever as abordagens de desenvolvimento que aplicam planejamento, aprendizando, melhorias, colaboração em time, desenvolvimento evolucionário e entregas iniciais contínuas, Isto encoraja respostas flexíveis a mudança.
Os quatro valores nucleares da metodologia Ágil são:
Interações individuais e em time acerca de processos e ferramento;
Software Funcional sobre documentação compreensível;
Colaboração com cliente sobre negociação de contrato;
Responder a mudança sobre seguir um plano;
Metodologia Ágil vs Modelo Cascata
Metodologia Ágil
Metodologias Ágeis proponhem abordagens incrementais e iterativas ao design de software
O Processo Ágil na engenharia de software é dividido em modelos individuais que designers se debruçam sobre;
O cliente tem oportunidades frequentes e desde o início para ver o produto e realizar decisões ou mudanças no projeto;
É considerado inestruturado quando comparado ao modelo cascata
Projetos pequenos podem ser implementados rapidamente, já projetos grandes é difícil estimar o tempo de desenvolvimento;
Erros podem ser corrigidos no meio do projeto;
O processo de desenvolvimento é iterativo, e o projeto é executado em iterações curtas (2-4 semanas)
Documentação possui menor prioridade do que desenvolvimento de software;
Cada iteração tem sua própria fase de testes. Isto permite o implemento de testes de regressão toda vez que uma nova funcionalidade ou lógica for lançada;
No teste Ágil quando uma iteração termina, features enviáveis do produto são entregues ao cliente. Novas features são usáveis logo após o envio, o que é útil quando se tem bom contato com clientes;
Devs e testers trabalham juntos;
No fim de cada sprint, a aceitação de usuário é aplicada;
Requer comunicação próxima com desenvolvedores, para juntos analisar requerimentos e planejamentos;
Modelo Cascata:
Desenvolvimento do software flue sequencialmente do começo ao fim;
O processo de design não é subdividido em modelos individuais
O cliente pode ver o produto apenas no fim do projeto;
Modelo cascata é mais seguro por ser orientado pelos planos;
Todos os tipos dep rojetos podem ser estimados e completos;
Apenas no fim, o produto inteiro é testado. Se erros são localizados ou quaisquer mudanças forem feitas, o projeto começa todo de novo;
O processo de desenvolvimento se da por estágios, e o estágio é muito maior que uma iteração. Cada estágio termina com uma descrição detalhada do próximo;
Documentação é de altíssima prioridade e pode ser usada inclusive para treinar colaboradores e melhorar o software com outro time;
Apenas após a fase de desenvolvimento a testagem se inicia, pois partes separadas não são completamente funcionais;
Todas as features desenvolvidads são entregues de uma vez após uma longa fase de implementação;
Testers trabalham de forma separada dos devs;
Aceitação de usuários é aplicada no fim do projeto;
Devs não se envolvem nos processos de regras de negócio e planejamento. Geralmente, existem atrasos entre testes e código;
Em testagem de software o Scrum é uma metodologia utilizada para construir aplicações complexas. Ela provê soluções fáceis para execução de tarefas complexas. Scrum auxilia o time de desenvolvimento a focas em todos os aspectos do desenvolvimento de um produto de software, como qualidade, performance, usabilidade, etc. Gera transparência, inspeção e adaptação durante o SLDC para evitar complexibilidade.
É feita na metodologia scrum para validar as regras de negócio, e envolve a checagem de parâmetros não funcionais. Não existe papel ativo do tester no processo então é usualmente desenvolvida por developers com Testes Unitários. Por vezes times de testes dedicados são necessários a depender da natureza e complexidade do projeto.
Scrum possui agendas curtas para ciclos de lançamento com escopos ajustavens conhecidas como sprints. Cada realease pode possuir múltiplas sprints, e cada projeto Scrum pdoe possuir múltiplos ciclos de lançamento;
Uma sequência repetitiva de reuniões, eventos e milestones;
A prática de testagem e implementação de novas regras de negócio, conhecida como estórias, para garantir que part e do trabalho é lançada logo após cada sprint;
Estórias de Usuários: São uma explicação curta das funcionalidades do sistema sob testes. Um exemplo para uma agência de seguros é - "Premium pode ser pago usando o sistema online";
Backlog do Produto: É uma coleção de estórias de usuários capturadas para um projeto Scrum. O P.O prepara e mantém este backlog. É priorizado pelo P.O, e qualquer um pode adicionar dados com sua aprovação;
Backlog de Lançamento: Um lançamento é um lapso temporal em que um número de iterações é completa. O P.O coordena com o Scrum Master para decidir quais estórias devem ser priorizadas em uma release. Estórias no backlog de lançamento são priorizadas para finalização em uma release;
Sprints: É um espaço de tempo determinado para finalização das histórias de usuário, decidida pelo P.O e time de desenvolvemento, geralmente 2-4 semanas;
Sprint Backlog: É um grupo de histórias de usuários a serem finalizadas em uma sprint. Durante o sprint backlog, o trabalho nunca é designado, e o time se habilita para um trabalho por si só. É de posse e administração do time enquanto o trabalho restante estimado é atualizado diariamente. É a lista de tasks que devem ser desenvolvidas em uma sprint;
Lista de Blocks: É uma lista de blocks e decisões que não foram realizadas, de posse de Scrum Master e atualizada diariamente;
Gráfico Burndown: Representa o progresso geral entre trabalho em desenvolvimento e trabalho completo através de todo o processo. Representa em forma de gráfico as histórias e features não finalizadas;
Planejamento de Sprints: Uma sprint se inicia com o time importando estórias do Backlog de Lançamentos para o Backlog de Sprints. Os testers estimam o esforço para validar as diversas histórias no Sprint Backlog;
Scrum Diário: Apresentado pelo Scrum Master, dura cerca de 15 minutos. Durante o Scrum diário os membros irão discutir o trabalho completo no dia anterior, o trabalho planejado para o dia seguinte e dificuldades encontradas durante uma sprint. No decorrer da reunião diária o progresso de um time é rastreado;
Review da Sprint/Retrospectiva: Também apresentada pelo Scrum Master, dura entre 2-4 horas e discute o que o time desenvolveu na última sprint e que lições foram aprendidas;
Geralmente, os testes são desenvolvidos por um dev com o Teste Unitário. Enquanto o P.O é também frequentemente envolvido no processo de testes em cada sprint. Alguns projetos Scrum tem times de teste dedicados dependendo da natureza e complexibilidade do projeto.
Aqui o tester deve escolher uma estória de usuário do backlog de produto para testes.
Como tester, deve decidir quantas horas (Estimativa de Esforço) levará para finalizar os testes para cada estória selecionada.
Deve saber quais os objetivos da sprint.
Contribuir para o proesso de priorização.
Sprints:
Dão suporte a devs no teste unitário
Com testes de histórias de usuário completos, a execução de teste é desenvolvida em laboratório onde dev e tester trabalham juntos. Defeitos são catalogados na ferramenta de Gerenciamento de defeitos que são verificados diariamente. Defeitos podem ser conferidos e analisados durante uma reunião Scrum. Quaisquer bugs são retestados tão logo corrigidos e implementados para teste.
Enquanto tester, comparecer a todas as reuniões diárias para falar;
Trazers quaisquer itens de backlog que não foram completos na sprint atual, para inserção na proxima sprint;
Tester é resposável pelo desenvolvimento dos scripts de automação. Ele agenda as testagens automatizadas com o Sistema de Integração Contínuo (CI). Automatização recebe importância devido aos tempos de entrega curtos. Automatização de testes pode ser atingida utilizando diversas ferramentas pagas ou open-source disponíveis. Isto prova sua eficiência ao garantir que tudo que precisa ser testado esteja coberto. Cobertura de Testes Satisfatória pode ser atingida com uma comunicação proxima com o time.
Revisão dos resultados da Automação no CI e envio de Relatórios para os Investidores.
Execução de testes não funcionais para estórias de usuários aprovadas.
Coordenação com cliente e P.O para definir critérios de aceite para os Testes de Aceite.
No fim da Sprint, o tester também performa o UAT em alguns casos, e confirma a finalização dos testes para a sprint atual.
Retrospectiva da Sprint:
Enquanto tester, ira estabelecer o que deu errado e o que obteve sucesso na sprint atual.
Métricas de teste Scrum provém transparência e visibilidade para os investidores sobre o projeto. As métricas reportadas permitem que um time analise seu progresso e planeje estratégias futuras para melhoria do produto.
Existem duas métricas frequentimente usadas para reportar:
Diariamente, o Scrum Master registra o trabalho restante estiamdo para a sprint atual. O que nada mais é do que o Burn Down, atualizado diariamente.
Este grafico provê visualização geral rápida do progresso no projeto, aqui, temos informações como o volume total de trabalho no projeto que precisa ser finalizado, volume de trabalho completo em cada sprint e etc.
Esta técnica prevê a velocidade do time em cada sprint, É um gráfico de barras que representa como o output do time mudou ao longo.
As métricas adicionais que podem ser úteis consistem na queima de cronograma, queima de orçamento, porcentagem do tema completo, estórias completas, estórias remanescentes, etc.
O Kanban é uma estrutura popular usada para implementar o desenvolvimento de software Ágil e DevOps, requer comunicação em tempo real de capacidade e transparência de trabalho.
Itens de trabalho são representados visualmente num painél Kanban, permitindo que os membros do time vejam o estado de cada setor do projeto a qualquer momento.
É uma ferramenta de gerenciamento de projetos Ágeis que auxiliam na visualização clara do projeto, maximizando eficiência (ou fluxo).
Isto auxilia tanto times Ágeis quanto DevOps em seu dia-a-dia de trabalho. Painéis Kanban usam cards, colunas e melhoria contínua para auxiliar times serviços e tecnologias a empenharem-se na quantidade correta de trabalho.
Um dos primeiros elementos perceptíveis sobre o painél são os cards visuais (adesivos, tickets, etc). Times Kanban escrevem todos seus projetos e items de trabalho em cards, geralmente um por card. Para times Ágeis, cada card pode encapsular uma estória de usuário. Uma vez no painél, estes sinais visuais auxiliam membros do time e investidores a rapidamente entender no que o time está focado.
Número máximo de cards que podem estar em uma coluna a qualquer momento. Uma coluna com um limite WIP de três não podem conter mais do que três cards em si.
Quando a coluna atinge seu máximo, o time precisa focar nestes cards para movê-los adiante, abrindo espaço para novos cards entrarem neste estágio do workflow.
Estes limites WIP são críticos para expor gargalos na produção e maximizar o fluxo. Limites WIP provém avisos prévios de que você inscreveu-se em trabalho demais.
Times Kanban usualmente possuem um backlog de seus painéis. É aqui que clientes e parceiros de time inserem ideias para projetos que o time pode assumir quando estiverem prontos. O ponto de compromisso é o momento em que uma idéia é assumida pelo time e o trabalho inicia-se no projeto.
Para a maioria dos times, o ponto de entrega é quando o produto ou serviço está nas mãos do cliente. O objetivo da equipe é levar os cards do commitment para a entrega o mais rápido quanto possível. O período de tempo entre os dois pontos pode ser chamado de Lead Time, times Kanban continuamente esforçam-se para melhorar e diminuir este tempo ao máximo.
Jim Benson diz que o Kanban possui apenas duas regras:
+
+"Limite o WIP e visualize seu trabalho. Se começar apenas com estas duas regras e aplicá-las ao seu trabalho, seu painél Kanban será bastante diferente do descrito acima. E tá tudo bem!"
+
Os painéis mais simples de Kanban são quadros físicos divididos em colunas. Times marcam o quadro com post-its, que se movem através do workflow demonstrando progresso.
Uma vantagem de quadros físicos é que "está sempre ligado". Você não pode abrir uma aba nova em um quadro branco enorme logo ao lado da sua mesa"
É simples e fácil de montar, mas por vezes, a tela física não é ideal para times remotos.
Enquanto o sistema Kanban ganhou espaço com os times de software e engenharia, sofreu.
Painéis digitais permitem que times que não dividem espaços físicos possam usar quadros Kanban remotamente e de forma assíncrona.
A plataforma Trello oferece uma forma rápida e fácil de criar painéis Kanban virtualmente.
As vantagens de um quadro Kanban virtual estão na velocidade ed configuração, facilidade de compartilhamento e o caráter assíncrono do infinito número de conversas e comentários ao longo do projeto. Não importa onde ou quando os membros do projeto chequem o painél, eles verão o status mais atualizado. Além disso, voce pode usar um workflow construído em Trello para seus afazeres pessoais.
As diferenças entre Kanban e Scrum são bastante sutis. Na maioria das interpretações, os times Scrum utilizam um quadro Kanban, mas com processos, artefatos e papéis Scrum dentro dele. Existem, entretanto, diferenças chave:
Sprints Scrum tem datas de início e fim, enquanto o Kanban é um processo contínuo;
Funções do time são claramente definidas no Scurm (P.O, devs, Scrum Master), enquanto Kanban não possui papéis formais. Ambos os times são bem organizados;
Um painél Kanban é utilizado através do ciclo de um projeto, enquanto um quadro Scrum é limpo e reciclado após cada sprint.
Quadros Scrum possuem um número determinado de tarefas e datas de entregas fixadas;
Painéis Kanban são mais flexíveis no que tange a tarefas e limites de tempo. Tarefas podem ser repriorizadas, redesignadas ou atualizadas conforme necessário.
Tanto o Kanban quanto o Scrum são estruturas Ágil populares entre desenvolvedores de software.
Kanban é um método "comece com o que sabe". Isto significa que você não precisa descobrir o que fará a seguir para iniciar o Kanban. O método presume três coisas:
Você compreende os processos atuais, enquanto eles são aplicados, e respeita os papés, responsabilidades e hieriarquias atuais;
Você concorda em perseguir a melhoria contínua através da mudança evolucionária;
Você encoraja atos de liderança em todos os níveis, de colaboradores até gerentes sênior;
É uma estrutura sequencial que divide o desenvolvimento de software em fases pré-definidas. Cada uma deve ser completa antes que a próxima possa ser iniciada, sem sobreposição entre fases.
Cada etapa é estruturada para desenvolver uma atividade específica durante a fase SDLC.
Fase de Coleta das Regras de Negócio: Coleta de tantas informações quanto possíveis acerca dos detalhes e especificações do software desejado pelo cliente.
Fase de Design: Planejamento da linguagem de programação a ser utilizada, database, etc. Que deve adequar-se ao projeto, bem como funções de alto nível e arquitetura.
Fase de Construção: Após o Design, passamos a construir de fato o código do software.
Fase de Testes: Após, testamos o software para verificar que foi feito conforme as especificações fornecidas pelo cliente.
Fase de Implementação: Implementa a aplicação no ambiente designado.
Fase de Manutenção: Uma vez que o sistema está pronto para uso, pode ser necessário alterar o código mais tarde a depender de solicitações dos usuários.
É uma estrutura de SLDC altamente disciplinada que possui uma faze de testes paralela a cada etapa de desenvolvimento.
O modelo V é uma extensão da modalidade de Cascata onde o desenvolvimento e testes são executados sequencialmente. Também conhecido como modelo de Validação ou de Verificação.
Fase de Coleta das Regras de Negócio: Coleta de tantas informações quanto possíveis acerca dos detalhes e especificações do software desejado pelo cliente.
Fase de Design: Planejamento da linguagem de programação a ser utilizada, database, etc. Que deve adequar-se ao projeto, bem como funções de alto nível e arquitetura.
Fase de Construção: Após o Design, passamos a construir de fato o código do software.
Fase de Testes: Após, testamos o software para verificar que foi feito conforme as especificações fornecidas pelo cliente.
Fase de Implementação: Implementa a aplicação no ambiente designado.
Fase de Manutenção: Uma vez que o sistema está pronto para uso, pode ser necessário alterar o código mais tarde a depender de solicitações dos usuários.
Todas estas etapas constituem o modelo CASCATA, de desenvolvimento.
Como pode observar, os testes são realizados apenas após a implementação estar finalizada.
Mas se você estiver trabalhando em um projeto grande, onde os sistemas são complexos, é fácil perder detalhes chave na própria fase inicial. Nestes casos, um produto completamente errado será entregue ao cliente e existe a possibilidade de recomeçar todo o projeto.
Desta forma, os custos de corrigir defeitos aumentam a medida que progredimos no SDLC. Quanto mais cedo detectados, mais baratos serão para corrigir.
Para endereçar estes conflitos, o modelo de testagem em V foi desenvolvido de forma que cada fase de desenvolvimento possui uma fase de testes correspondente.
Além do modelo V existem outras categorias de desenvolvimento iterativo, onde cada fase adiciona uma funcionalidade ao projeto em etapas. Cada etapa compreende um grupo independente de ciclos para teste e desenvolvimento.
Exemplos destes métodos iterativos são o Desenvolvimento Ágil e o Desenvolvimento de Aplicação Rápida.
Elaborar um relatório é uma tarefa que exige muita atenção e cuidado, pois é um documento que deve ser claro e objetivo, e que deve conter informações relevantes para o leitor.
Um bug é a consequencia/resultado de uma falha no código. Uma falha no código pode ter sido gerada por um erro de programação, ou por um erro de design. Geralmente erros no código acontecem por falta de conhecimento do programador, ou por falta de atenção.
É esperado que o software desenvolvido contenha uma quantidade razoável de bugs, pois é impossível prever todos os cenários possíveis de uso da aplicação. Porém, quanto mais bugs forem encontrados de forma tardia, mais tempo será gasto para corrigi-los, e mais tempo será gasto para testar a aplicação.
Um defeito é uma variação ou desvio da aplicação de software em relação as regras de negócio ou requerimentos de business originais.
Um defeito de software consiste em um erro no processo de codificação, o que causa resultados incorretos ou inesperado no programa, o que não atende aos requerimentos estabelecidos. Testers podem se deparar com tais defeitos ao aplicar os casos de teste.
Estes dois termos possuem tênue diferença, e na indústria ambos são falhas que precisam ser corrigidas, sendo usadas de forma intercambeável por alguns times
Um relatório de bugs é um documento detalhado acerca de bugs encontrados na aplicação, contendo cada detalhe como descrição, data em que foi localizado, nome do testers que o encontrou, nome do dev que corrigiu, etc. Estes relatórios auxiliam a identificar bugs similares no futuro, de forma a evitá-los.
Ao reportar bugs ao desenvolvedor, o seu relatório deve conter as seguintes informações:
Defeito_ID: Número de identificação única para o defeito.
Descrição do Defeito: Descrição detalhada incluindo informações sobre o módulo em que o defeito foi encontrado.
Versão: Em qual versão da aplicação o defeito foi localizado.
Data de Surgimento: Data em que o defeito surgiu.
Referência: Onde se provê referencias a documentações como requerimentos, design, arquitetura ou até mesmo capturas de tela do erro para auxiliar a compreensão.
Detectado por: Nome/ID do testers que identificou o defeito.
Status: Situação do defeito.
Corrigido por: Nome/ID do desenvolvedor que corrigiu.
Data de Encerramento: Data em que o defeito foi finalizado.
Gravidade: Descreve o impacto do defeito na aplicação.
Prioridade: Relacionada com a urgência na correção do defeito. A prioridade pode ser alta/média/baixa com base na urgência de impacto com que o defeito deve ser corrigido.
Outros elementos necessários para o relatório são:
Quando o bug ocorre? Como é possível reproduzí-lo?
Qual é o comportamento incorreto e o que era esperado?
Qual é o impacto no usuário? O quão crítica será sua correção?
Isto ocorre apenas com dados de teste específicos?
Qual build foi utilizada para o teste? (incluindo, idealmente, a commit do git)
Se o bug ocorre na versão mobile, qual modelo, tamanho de viewport e sistema operacional?
Se o bug ocorre em um browser, qual o tipo de browser, resolução e versão?
Se o bug ocorre em uma API, qual a API específica/fluxo de trabalho é impactado, quais são os parâmetros de request e resposta?
Captura de tela com as áreas relevantes demarcadas.
Video demonstrando os passos tomadas até ocorrência do bug.
Logs da aplicação/servidor
Qualquer feature de seleção/configuração específica, caso envolvida quando o bug ocorreu?
Nesta fase os times devem descobrir tantos defeitos quanto possível antes que o usuário final o faça. Um defeito é declarado como encontrado, e tem seu status alterado para "Aceito" uma vez reconhecido e aceito por desenvolvedores.
A resolução de defeitos na testagem de software é um processo que corrige desvios passo a passo, iniciando-se com a designação de defeitos para desenvolvedores, que por sua vez inserem os defeitos em um cronograma de acordo com sua prioridade.
Uma vez que a correção seja finalizada, os desenvolvedores enviam um relatório ao Gerente de Testes, o processo auxilia na correção e registro dos defeitos.
Designação: Um desenvolvedor ou outro profissional recebe a correção a ser feita, e altera o status para Respondendo.
Fixação de Cronograma: O desenvolvedor assume parte do controle nesta fase, criando uma agenda para corrigir os defeitos com base em sua prioridade.
Correção do Defeito: Enquanto o time de desenvolvimento corrige os defeitos, o Gerente de Testes registra o processo.
Relatório da Resolução: Envio do relatório sobre a correção de defeito por parte dos desenvolvedores.
É um processo em que gerentes de testes preparam e enviam o relatório de defeitos para que o time de gerência provenha feedback no processo de gestão dos defeitos, bem como o status destes.
Então, o time de gerência checa o relatório, podendo enviar o feedback ou prover suporte adicional caso necessário. O relatório de defeitos auxilia a melhor comunicar, registrar e explicar defeitos com detalhes.
O conselho de administração tem o direito de saber o status dos defeitos, uma vez que devem compreender o processo de gestão para auxiliar no projeto. Portanto, deve-se reportar a eles a situação atual dos defeitos, acatando feedback.
# Como medir e avaliar a qualidade da execução de testes
Taxa de Rejeição dos Defeitos: (Número de defeitos rejeitados/Número total de defeitos)*100
Taxa de Vazamento dos Defeitos: (Número de defeitos não detectados/Total de defeitos do software)*100
A verificação, na testagem de software é um processo de checar documentos, design, código e programa para validar se o software foi construído de acordo com as regras de negócio.
O principal objetivo é garantir a qualidade da aplicação, design, arquitetura, etc. Este processo envolve atividades como revisões, passo a passo e inspeções.
É um mecanismo dinâmico que testa e valida se o software de fato atende as exatas necessidades do cliente ou não. O processo auxilia a garantir que o produto atende o uso desejado em um ambiente apropriado. O processo de Validação envolve atividades como Teste Unitário, Teste de Integração, Teste de Sistema e Teste de Aceitação do Usuário (UAT)
É um processo que avalia se produto de software está de acordo com os exatos requerimentos de usuários finais ou investidores. O propósito é testar o produto de software após desenvolvimento, para garantir que atenda as regras de negócios no ambiente de usuário.
A validação preocupa-se em demonstrar a consistência e completude do design no que tange necessidades do usuário. Este é o estágio em que se constrói uma versão do produto e valida-se contra as regras de negócio.
O objetivo é provar com evidências objetivas que o produto satisfaça as necessidades de usuários, as evidências objetivas não são nada além de provas físicas do output, como uma imagem, texto ou arquivo de audio que indique que o procedimento obteve sucesso.
Este processo envolve atividades de teste, inspeção, análise, etc.
É um método que confirma se o output de um produto de software designado atende as especificações de input ao examinar e prover evidências. O objetivo do processo de verificação é garantir que o design é idêntico ao especificado.
Entrada de projeto é qualquer requerimento físico e de performance usado como base para propósitos de design. O output é resultado de cada fase de design ao final de todo o esforço de desenvolvimento. O output final é a base para registro mestre do dispositivo.
Durante o estágio de desenvolvimento de uma especificação, as atividades de identificação e verificação são feitas de forma paralela. Isto permite ao designer garantir que as especificações são verificáveis. Um engenheiro de testes pode, então, iniciar planos de teste e procedimentos detalhados. Quaisquer mudanças na especificação devem ser comunicadas.
Identificar a melhor abordagem para condução da verificação, definir métodos de medição, recursos necessários, ferramentas e instalações.
O plano de verificação completo será revisado pelo time de design para identificar eventuais problemas antes da finalização do plano.
Planejamento:
Planejar para verificação é uma atividade concomitante entre times de core e desenvolvimento. Isto ocorre através do ciclo de vida do projeto, e será atualizado conforme e quaisquer mudanças sejam feitas nos inputs.
Durante esta fase, o sistema ou software sob testes deve ser documentado em escopo.
Plano de testes preliminar e seu refinamento são feitos neste estágio. O plano captura as milestones críticas reduzindo os riscos do projeto.
Ferramentas, ambiente de testes, estratégia de desenvolvimento e identificação de requerimentos através de inspeção ou análise.
Desenvolvimento:
O desenvolvimento do caso de testes coincidirá com a metodologia SLDC implementada por um time. Uma variedade de métodos são identificados durante este estágio.
As entradas de projeto serão desenvolvidos de forma a incluir verificações simples, livres de ambiguidade e verificáveis.
Tempo de verificação deve ser reduzido quando conceitos similares são conduzidos em sequência. Até mesmo o output de um teste pode ser usado como input de testes subsequentes.
Links de tratabilidade são criados entre casos de testes e inputs de projeto correspondentes, para garantir que todos os requerimentos sejam testados e que o output de projeto atenda aos inputs.
Execução:
Os procedimentos de teste criados durante a fase de desenvolvimento são executados de acordo com o plano de testes, que deve ser estritamente seguido para atividades de verificação.
Caso qualquer resultado inválido ocorra, ou caso qualquer procedimento necessite de modificações, é importante documentar as mudanças e conseguir aprovações pertinentes.
Neste estágio, quaisquer problemas são identificados e catalogados como um defeito.
Matriz de tratabilidade é criada para verificar que todos os inputs de projeto identificados no plano de teste de verificação tenham sido testados e determinar a taxa de sucesso.
Relatórios:
Esta atividade é desenvolvida ao final de cada fase de verificação.
O relatório de verificação do design provê um sumário detalhado dos resultados de verificações que incluem gerenciamento de configurações, resultados de teste para cada modalidade e problemas encontrados durante a verificação
O relatório de rastreabilidade de verificação de design é criado entre requerimentos e resultados de teste correspondentes para verificar que todas as regras de negócio foram testadas e providas com resultados apropriados.
Qualquer inconformidade será documentada e apropriadamente abordada.
Revisões são feitas quando da finalização das verificações de design, e são aprovadas respectivamente.
Alguns dos designs podem ser validados ao comparar com equipamentos similares desenvolvendo atividades semelhantes. Este método é particularmente relevante para validar alterações de configuração para a infraestrutura existente, ou designs padrão que devem ser incorporados em um novo sistema ou aplicação.
Demonstração e/ou inspeções podem ser usadas para validar regras de negócio e outras funcionalidades do projeto.
Análises de produto podem ser feitas como modelagem matemática, uma simulação que recria a funcionalidade necessária.
Testes são executados no design final, que valida a habilidade do sistema de operar conforme as diretrizes estabelecidas.
Plano de testes, execução e resultados devem ser documentados e mantidos como parte dos registros de design. Portanto, Validação é uma coletânea dos resultados de todas as ações de validação.
Quando produtos equivalentes são utilizados na validação de design final, o fabricante deve documentar a similaridade e qualquer diferença da produção original.
Exemplo:
Tomemos como exemplo um produto simples, um relógio a prova d'agua.
As regras de negócio podem definir que "o relógio deve ser a prova de água durante natação".
A especificação de design pode definir que "o relógio deve funcionar mesmo que o usuário nade por tempo prolongado">
Os resultados de teste devem confirmar que o relógio atende estas regras ou iterações de redesign são feitas até que satisfaça aos requerimentos.
Podemos monitorar continuamente os designs, o que nos permite atender aos requerimentos definidos por usuários em cada estágio.
Validar o design irá pontuar a diferença entre como a funcionalidade opera e como ela deveria operar.
Documentar os procedimentos de validação irá auxiliar a facilmente enteder a funcionalidade em qualquer estágio no futuro caso exista alguma mudança ou melhoria.
O tempo de desenvolvimento será consistentemente reduzido, melhorando a produtividade, o que habilita a entrega do produto conforme esperado.
Este processo inclue amplitude e escopo de cada método de validação que devem ser aplicados.
Qualquer diferença entre o resultado e as necessidades de usuário devem ser documentados.
Mudanças na validação de design levam a revalidações.
É importante documentar todas as atividades que ocorram durante a validação, o que adequadamente prova que o design atende aos requerimentos de usuário.
Inicialmente para executarmos testes precisamos ter noção de como o software funciona, para isso talvez seja necessário que o software esteja em um estágio avançado de desenvolvimento, ou que ele tenha requerimentos muito consistentes.
Existem duas formas em quais testes podem ser executados, manualmente ou automaticamente. A execução manual é a mais comum, pois ela permite que o teste seja executado de forma mais rápida e simples. Porém, ela é mais propensa a erros, pois o teste pode ser executado de forma incorreta. Por outro lado, a execução automática é mais lenta, pois ela requer a criação de um script que será responsável por executar o teste.
Devido a essas diferenças, a execução manual é mais recomendada para testes simples, enquanto a execução automática é mais recomendada para testes complexos.
A complexidade de testes é relativa ao seu escopo, ou seja, quanto maior o escopo do teste, maior será a complexidade dele. Por exemplo, um teste que verifica se um botão está funcionando corretamente é um teste simples, pois ele possui um escopo pequeno. Por outro lado, um teste que verifica se um sistema inteiro está funcionando corretamente é um teste complexo, pois ele possui um escopo grande.
Além disso, a complexidade de um teste também pode ser medida pela quantidade de passos necessários para executá-lo. Por exemplo, um teste que possui apenas um passo é um teste simples, enquanto um teste que possui vários passos é um teste complexo.
Casos de teste consiste em um grupo de ações executadas para verificar uma feature ou funcionalidade da aplicação de software. Um Caso de Testes contém passos de teste, de dados, pré-condições, pós-condições desenvolvidas para um cenário de testes específico, a fim de validar quaisquer requerimentos necessários.
O caso de testes incluí variáveis e condições específicas, por meio das quais um engenheiro de testes pode comparar os resultados esperados, com os factuais, para determinar se um produto de software está funcionando de acordo com as regras de negócio determinadas.
Criemos um Caso de Testes para o Cenário: Verifique funcionalidade Login
Passo 1) Um caso de testes simples para explicar o cenário seria
Caso de Testes #1
Descrição Do Caso:
+Verificar resposta quando informações de email e senha válidos são inseridos
Passo 2) Testar as Informações
A fim de executar os casos de teste, seriam necessárias as informações do teste, adicionadas abaixo:
Caso de Testes #1
Descrição do Caso:
+Verificar resposta quando dados de email e senha válidos são inseridos
Dados de Teste:
+Email: guru99@email.com
+Senha: lNf9^Oti7^2h
Identificar os dados de teste pode demorar, e por vezes requerer a criação de dados novos, razões pelas quais precisa ser documentado.
Passo 3) Executar Ações
Para executar um caso, o tester deve desenvolver uma série de ações no UAT, que são documentadas da seguinte forma:
Caso de Testes #1
Descrição do Caso:
+Verificar resposta quando dados de email e senha válidos são inseridos.
Passos do Teste:
+
Inserir endereço de email;
Inserir senha;
Clicar em Sign In;
Dados de Teste:
+Email: guru99@email.com;
+Senha: lNf9^Oti7^2h;
Muitas vezes os Passos de Testes não são simples assim, fazendo-se necessária a documentação. Além disso, o autor do caso de testes pode deixar o quadro de funcionários, entrar em férias, ficar doente ou demais situações do gênero. Uma contratação recente pode receber a função de executar o caso de testes, passos documentados irão auxiliar no desenvolvimento da função e facilitar revisões por outros investidores.
Passo 4) Verificar o comportamento do AUT
O objetivo dos casos na testagem de software é verificar o comportamento da UAT por um resultado esperado. Deve ser documentado como se segue:
Caso de Testes #1
Descrição do Caso: Verificar resposta quando dados de email e senha válidos são inseridos.
Passos do Teste:
+
Inserir endereço de email;
Inserir senha;
Clicar em Sign In;
Dados de Teste:
+Email: guru99@email.com;
+Senha: lNf9^Oti7^2h;
Resultados Esperados:
+Login com sucesso.
Durante o período de execução do teste, o profisisonal irá verificar resultados esperados contra os resultados factuais, designando um status de Sucesso ou Falha.
Caso de Testes #1
Descrição do Caso:
+Verificar resposta quando dados de email e senha válidos são inseridos.
Passos do Teste:
+
Inserir endereço de email;
Inserir senha;
Clicar em Sign In;
Dados de Teste:
+Email: guru99@email.com;
+Senha: lNf9^Oti7^2h;
Resultados Esperados: Login com sucesso.
Sucesso/Falha: Sucesso.
Passo 5) O caso de testes pode possuir uma pré-condição que especifique elementos necessários antes do inícios dos testes.
Para o nosso caso de testes, uma pré-condição seria ter um browser instalado para obter acesso ao site sob validação. Um caso também pode incluir pós-condições que especifiquem quisquer elementos que apliquem-se após a finalização dos casos.
Neste exemplo, a pós-condição seria que o horário e data do login sejam documentados na base de dados.
# Melhores práticas para escrever um bom Caso de Testes
O principal objetivo de qualquer projeto de software é criar casos de teste que atendam as regras de negócio do cliente e sejam fáceis de operar. Um tester deve criar casos com o usuário final em mente.
Garanta que a escrita dos casos de teste verifiquem todos os requerimentos de software mencionados na documentação de especificação. Use matrizes de rastreamento para garantir que nenhuma função/condição seja deixada de lado.
Nomeie os ID para casos de forma que sejam indentificáveis facilmente ao vasculhar por defeitos ou identificar um requerimento de software nos estágios mais avançados.
Não é possível verificar todas as possíveis condições na aplicação de software. As técnicas de testagem auxiliam a selecionar casos de teste com a maior possibilidade de localizarem defeitos.
Análise de Valor de Limite (Boundary Value Analysis - BVA): Como o nome sugere esta técnica define a testagem dos limites de um escopo específico de valores.
Partição de Equivalência (Equivalence Partition - EP): Esta técnica divide o intervalo em partes/grupos iguais que tendem a possuir o mesmo comportamento.
Técnica de Transição de Estado: Este método é utilizado quando o comportamento de um software muda de um estado para outro em seguida de uma ação particular.
Técnica de Dedução de Erros: Esta técnica deduz/antecipa os erros que podem surgir durante a execução de um teste manual. Este não é um método formal e se vale da experiência do testers com a aplicação.
O caso de testes criado deve voltar ao Ambiente de Testes em seu estado pre-testes, não devendo tornar o ambiente testes inutilizável. Isto é especialmente pertinente para testes de configuração.
Após a criação dos casos de teste, leve-os para revisão por seus colegas. Seus pares podem descobrir defeitos no design do caso.
Inclua as seguintes informações ao desenvolver um caso de testes:
A descrição de qual requerimento está sendo testado.
Expllicação de como o sistema será validado.
O setup de testes como uma versão da aplicação sob verificação, software, arquivos de dados, sistema operacional, acesso de segurança, data lógica ou física, horário do dia, pré requisitos como outros testes e quaisquer outras informações de setup pertinentes aos requerimentos sob teste.
Inputs, outputs, ações e seus resultados esperados.
Quaisquer provas ou anexos.
Use linguagem ativa para maiúsculas e minúsculas.
Caso de testes não deve possuir mais do que 15 passos.
Um script de teste automatizado é comentado com inputs, propósito e resultados esperados.
O Setup oferece uma alternativa para testes prévios necessários.
Com outros testes, deve ser uma ordem incorreta do cenário de negócios.
# Ferramentas para Administração de Casos de Teste
Ferramentas de administração são os elementos de automação que auxiliam a coordenar e manter os casos de testes. As principais funcionalidades de uma ferramenta como esta, são:
Documentar Casos de Teste: com ferramentas, pode-se acelerar a criação de casos de testes com o uso de templates.
Executar o Caso de Testes e Documentar resultados: Casos podem ser executados através das ferramentas, e resultados coletados para fácil registrar.
Automatizar o Rastreio de Defeitos: Testes que obtiveram falha são automaticamente ligados ao rastrador de bugs, o que, por sua vez, pode ser designado aos desenvolvedores através de notificação via email.
Rastreabilidade: Requerimentos, casos de teste e suas execuções são conectados através das ferramentas, e cada caso pode ser rastreado até os demais para validar cobertura.
Proteção dos Casos de Teste: Casos de testes devem ser reutilizáveis, e protegidos de perda ou corrupção devido a controle de versões deficitário.
As feramentas muitas vezes oferecem funcionalidades como:
Convenções de nomenclatura e numeração
Controle de Versão
Armazenamento read-only
Acesso controlado
Backup externo
Ferramentas de administração dos testes populares são:
Esta técnica de testagem verifica casos executados manualmente por um profissional sem qualquer auxílio de ferramentas automatizadas. O propósito da Testagem Manual é identificar bugs, problemas e defeitos no aplicativo. Os testes de software manuais constituem a mais primitiva técnica dentre todas as abordagens, e auxilia na identificação de bugs críticos da API.
Qualquer nova aplicação precisa ser manualmente testada antes que seja automatizada. Esta técnica requer maior esforço, mas é necessária para avaliar aplicabilidade de automação.
O conceito de teste manual não requer qualquer conhecimento de ferramentas para teste. Um dos fundamentos da Testagem de Software é "100% de automação não é possível", o que torna a abordagem manual imperativa.
O conceito chave do teste manual é garantir que a aplicação esteja livre de bugs e funciona em conformidade com as regras de negócio funcionais.
Baterias e casos de teste são desenvolvidos durante a fase de testes e devem ter 100% de cobertura, o que também garante que defeitos reportados sejam corrigidos por desenvolvedores, e que a retestagem tenha sido aplicada por testers nos defeitos corrigidos.
Basicamente este técnica verifica a qualidade do sistema e entrega um produto livre de bugs para o cliente.
O diagrama representa os tipos de teste manual. Na verdade, qualquer tipo de abordagem para testes pode ser executada tanto manualmente ou com uma ferramenta de automatização.
Testagem automatizada é aplicação de ferramentas de software para automatizar um processo manual de revisão e validação do produto de software. Projetos Ágil e DevOps mais modernos incluem esta técnica.
A modalidade cooloca responsabilidades de propriedade nas mãos do time de engenharia. Os planos de teste são desenvolvidos paralelamente ao roteiro de desenvolvimento padrão e executado automaticamente por ferramentas de integração contínua. Isto promove um time de QA eficiente, e permite que a equipe foque em features mais sensíveis
Entrega Contínua (Continuous Delivery/CD) refere-se a entrega de novos lançamentos de código o mais rápido possível aos clientes, e a automatização de testes desempenha fator crítico para este objetivo. Não há forma de automatizar a entrega aos usuários se existe um processo manual e dispendioso dentro do processo de entregas.
A entrega contínua faz parte de uma pipeline de implantação maior, sendo sucessora e também dependente da integração contínua (Continuous Integration/CI). Esta, por sua vez, é inteiramente responsável por executar testes automatizados em quaisquer mudanças de código, verificando se estas mudanças não quebram features estabelecidas ou introduzem novos bugs.
O deploy contínuo entra em ação uma vez que a etapa de integração contínua passe no plano de testes automatizado.
Esta relação entre testagem automatizada, CI e CD produzem muitos benefícios para um time de alta eficiência. A automação garante qualidade em todos de desenvolvimento ao verificar que novas commits não introduzam bugs, para que o software permaneça pronto para implantação a qualquer momento.
#Quais tipos de testes devem ser automatizados primeiro?
Discutivelmente um dos testes mais valiosos a serem implementados, a técnica simula uma experiência a nível de usuário através de todo o produto de software. Planos para testes ponta-a-ponta geralmente cobrem estórias a nivel de usuário como "o usuário pode realizar login", "o usuário pode efetuar um depósito", "usuário pode alterar configurações de Email".
A implementação destes teste é altamente valiosa já que oferecem garantia de que usuários reais terão uma experiência suave e livre de bugs, mesmo quando novas commits são aplicadas.
Como o nome sugere, testes unitários cobrem partes individuais de código, sendo melhor medidos em definições de função.
Um teste unitário irá validar uma função individual, verificando que o input esperado em uma função irá coincidir com o output previsto. Código que possuam cálculos sensíveis (uma vez que pode referir-se a finanças, planos de saúde ou espaço aereo) são melhor cobertor por esta técnica de testes.
Caracterizam-se por seu baixo custo e velocidade de implementação, provendo um alto retorno de investimento.
Muitas vezes uma unidade de código fará uma chamada externa para um serviço terceirizado, mas a base de código primária sob testes não terá acesso ao código deste utilitário de terceiros.
Testes de integração irão lidar com o mock destas dependências de terceiros, com o intuito de verificar se o código que realiza a interface comporta-se como esperado.
Esta técnica é similar aos Testes Unitários na forma com que são escritos e em suas ferramentas. São uma alternativa mais barata aos testes ponta-a-ponta, porém, o retorno de investimento é debatível quando a combinação de testes unitários e ponta-a-ponta já está estabelecida.
Quando usado no contexto de desenvolvimento de software 'performance' refere-se a velocidade e responsividade com que um projeto de software reaje. Alguns exemplos para métricas de performance são:
Tempo para carregamento de página
Tempo para renderização inicial
Tempo de resposta para resultados de pesquisa
Esta modalidade de testes criam métricas e garantias para estes casos.
Em sua versão automatizada, os testes de performance irão executar os casos de teste através das métricas e alertar o time caso regressões ou perdas de velocidade ocorram.
# Quais tipos de teste devem ser executados manualmente?
É discutível se todos os testes que podem ser automatizados, deveriam ser. A automação representa enorme ganho de produtividade e custo de horas de trabalho, isto posto, existem situações em que o Retorno de Investimento (Return of Investiment/ROI) para desenvolver uma bateria de testes automatizada é inferior quando comparado a execução de testes manuais.
Teste automatizados são, por definição, scriptados, e seguem uma sequência de passos para validar um comportamento. Um teste exploratório é mais aleatório e aplica sequências não roteirizadas para localizar bugs ou comportamentos inesperados.
Enquanto existem ferramentas para estabelecer uma bateria de testes exploratórios, elas não foram refinadas o suficiente, e ainda não receberam adoção ampla por empresas. Pode ser muito mais eficiente designar um tester manual e utilizar criatividade humana para explorar como é possivel quebrar um produto de software.
Uma regressão visual ocorre quando uma falha de design visual é introduzida na UI do produto, podendo constituir-se de elementos mal posicionados, fontes ou cores erradas, etc.
Assim como no teste exploratório existem ferramentas para desenvolvimentos de testes automatizados com o intuito de detectar estas regressões. As ferramentas realizam capturas de tela a partir de diferentes estados do produto, aplicando reconhecimento óptico de caracteres (Optical Character Recognition/OCR) para comparar com os resultados esperados. Estes testes possuem desenvolvimento custoso, e as ferramentas também não possuem adoção ampla, tornando a opção humana e manual mais eficiente em alguns casos.
# 3. Construindo estruturas de automação para times DevOps
Não existe solução única para automação de testes, ao desenvolver um plano de automação alguns pontos chaves devem ser levados em consideração:
Frequencia de Lançamento:
+Produtos de software que são lançados em intervalos fixos, como mensalmente ou semanalmente, podem encaixar-se melhor com a modalidade manual. Produtos com lançamentos mais rápidos em muito se beneficiam dos testes automatizados uma vez que o CI e CD dependendem de uma testagem automática.
Ferramentas Disponíveis e Ecosistema:
+Cada linguagem de programação possui seu próprio ecosistema de ferrmentas complementares e utilidades. E cada tipo de padrão automatizado de testes detém um grupo de ferramentas próprio, que pode ou não estar disponível no ecosistema de certas linguagens. Implementar com sucesso um padrão de testes automáticos irá requerer uma interseção da linguagem e suporte de ferramentas.
Ajuste ao mercado do produto e maturidade da base de código:
+Caso o time esteja construindo um novo produto que não recebeu validação de público alvo e modelo de negócios, pode não fazer sentido investir em testes automatizados, considerando que estes atuam como um mecanismo de garantia que restringe regressões inexperadas de código. Considerando que a equipe trabalhe em alta velocidade pode ser frustrantemente custoso atualizar e manter testes automatizados quando o código muda drástica e rapidamente.
Esta categoria de estrutura pode auxiliar tanto desenvolvedores quanto QAs a criarem softwares de alta qualidade, reduzindo o tempo que desenvolvedores levam para se a mudança introduzida quebra o código e contribuindo para o desenvolvimento de uma bateria de testes mais confiável.
Essencialmente, a pirâmide de testes, também conhecida como pirâmide de automação, estabelece os tipos de teste que devem ser inclusos em uma bateria automatizada. Também delimitando a sequência e frequência destes testes.
O principal objetivo é oferecer feedback imediato, garantindo que mudanças no código não afetem negativamente features já existentes.
Testes unitários formam a base da pirâmide, validando componentes e funcionalidades individuais para validar que funcionem corretamente sob condições isoladas. Portanto, é essencial executar diversos cenários em testes unitários.
Sendo o subgrupo mais significativo, a bateria de testes unitários deve ser escrita de forma a ser executada o mais rápido quanto o possível.
Lembre-se de que o número de testes unitários irá aumentar conforme novas features são adicionadas.
Esta bateria de testes deve ser executadas sempre que uma nova funcionalidade é implementada.
Consequentemente, desenvolvedores recebem feedback imediato sobre se as features individuais funcionam em sua forma atual.
Uma bateria de testes unitários eficiente e de execução rápida incentiva desenvolvedores a aplicarem-na com frequência.
A aplicação do TDD (Test-driven-development) contribui para a criação de uma bateria robusta, uma vez que a técnica requer a escrita dos testes antes que qualquer código seja estabelecido, tornando-o mais direto, transparente e livre de bugs.
Enquanto testes unitários verificam pequenas peças do código, os testes de integração devem ser executadas para verificar como as diferentes partes do software interagem entre si. Essencialmente, são testes que validam como uma parte do código interagem com componentes externos, podendo variar de databases até serviços externos (APIs)
Testes de Integração constituem a segunda camada da pirâmide, isto significa que não devem ser executados com a mesma frequència dos testes unitários.
Fundamentalmente, testam como uma feature comunica-se com dependências externas.
Seja uma chamada no banco de dados ou serviço web, o software deve comunicar-se eficientemente e buscar as informações corretar para funcionar conforme o esperado.
É importante ressaltar que esta técnica envolve interação com serviços externos, logo, sua execução será mais lenta do que a de testes unitários. Além disso, requerem um ambiente de pré-produção para poderem ser aplicados.
O nível mais alto da pirâmide, garantem que toda a aplicação funcione como deveria ao testa-la do começo ao fim.
Esta técnica encontra-se no topo da pirâmide uma vez que leva mais tempo para ser executada.
Ao desenvolver estes testes, é essencial pensar a partir da perspectiva de um usuário.
Como um usuário utilizaria este aplicativo? Como os testes podem ser escritos para replicar estas interações?
Eles também podem ser frágeis já que precisam testar diversos cenários de uso.
Assim como testes de integração, podem exigir que a aplicação comunique-se com elementos externos, o que possivelmente contribui com gargalos na conclusão.
Uma aula exemplificativa acerca da estratégia por trás dos testes ponta-a-ponta pode ser encontrada aqui(opens new window).
#Por que times Ágil deveriam usar a Pirâmide de Automação?
Os processos Ágil priorizam velocidade e eficiência, elementos oferecidos pela pirâmide através ao organizar o processo de testes em uma progressão lógica e clara, promovendo uma conclusão eficiente do trabalho.
Uma vez que a estrutura é feita de forma a executar testes mais acessíveis no início, testers podem melhor administrar seu tempo, obtendo melhores resultados e melhorando o trabalho de todos os envolvidos ao fornecer as prioridades certas para o time de testes.
Se scripts de testes são escritos com um foco maior na UI, chances são de que a lógica de negócios central e as funcionalidades back-end não foram suficientemente verificadas. Isto afeta a qualidade de produto e leva a um aumento no fluxo de trabalho das equipes.
Além disso o tempo de resposta dos testes de UI é alto, o que leva a uma menor cobertura geral de testes. Ao implementar a pirâmide de automação tais situações são completamente solucionadas.
Na automação de testes, ferramentas e estruturas como Selenium executam testes scriptados em uma aplicação de software ou componentes para garantir que funcionem como esperado. Seu único objetivo é reduzir o esforço e erro humanos, mas para que a máquina provenha os resultados corretos, deve ser apropriadamente direcionada.
A pirâmide de automação procura atingir esta necessidade ao organizar e estruturar o ciclo de testes, racionalizando todo o processo e trazendo um gerenciamento de tempo eficiente, de forma a prover testers com modelos já validados com os quais moldar seus projetos.
Comumente desenvolvida para verificação do banco de dados, o teste Back-End é um processo que verifica parâmetros de servidor em busca de uma transição suave. Constitui uma das mais essenciais atividades de teste, ocorrendo em todos os programas.
O armazenamento de dados geralmente ocorre no backend, que é validado pelo processo de testes para remoção de quaisquer ameaças no banco de dados.
Existem diferentes tipos de bancos de dados disponíveis no mercado, variando de SQL, Oracle, DB2, MYSQL, etc. A organização de dados em tabelas específicas é um dos fatores importantes a serem considerados. Portanto, auxilia a oferecer o resultado correto no front end.
Alguns dos problemas e complicações mais sensíveis como corrupção e perda de dados são solucionados através dos testes de database.
Não é obrigatório visualizar o teste backend através de interfaces gráficas de usuário, portanto, os testes ocorrem apenas em funcionalidades e códigos fonte. Os parâmetros de navegador são comumente verificados dependendo do programa ou projeto.
A testagem backend é geralmente concluída em poucos passos, logo, é importante conhecer o objetivo do processo antes de iniciar.
Os primeiros passos examinam o banco de dados e o servidor antes de progredir para funções, as etapas seguintes são construídas com base nas especificações e programação.
Testers preferem conduzir testes backend nos estágios iniciais por diversos motivos. A técnica ajuda a identificar alguns dos problemas básicos com o banco de dados, bem como a solucionar problemas relacionados ao servidor.
As ferramentas atuais permitem facilmente identificar problemas no backend, poupando quantias expressivas de tempo sem comprometer a qualidade
Existem variadas abordagens para validação do backend, tornando-se necessária a compreensão dos requisitos para desenvolvimento de uma estratégia eficiente.
É uma abordagem para desenvolvimento de software em que os casos de teste são desenvolvidos para especificar e validar o que o código fará. Em termos simples, casos de teste para cada funcionalidade são criados e testados primeiro, caso falhem, então o novo código é escrito de forma a passar pelo teste, gerando um código simples e livre de bugs.
O Test-Driven Development se inicia com o design e desenvolvimento de testes para cada funcionalidade de um aplicativo. A estrutura TDD instrúi desenvolvedores a escreverem código novo apenas caso um teste automatizado falhe, isto evita a duplicação de códigos, já que apenas uma pequena quantidade de código é escrita por vez, com o objetivo de passar nos testes.
O conceito simples do TDD é escrever e corrigir casos falhos antes de escrever código novo.
O TDD é um processo de desenvolver e aplicar testes automatizados antes do desenvolvimento da aplicação propriamente dita.
A abordagem TDD é primariamente uma técnica de especificação, que garante testagem satisfatória do código fonte.
Nos testes tradicionais, um teste que obteve sucesso encontrará um ou mais defeitos. Também é assim no TDD, caso um teste falhe, você gerou progresso já que identificou correções necessárias.
TDD garante que o sistema atenda de fato as regras de negócio definidas para ele. Isto auxilia a construir confiança no sistema.
O TDD foca predominantemente na produção de código que valide que os testes irão funcionar apropriadamente. Nas técnicas tradicionais, maior enfoque recai sobre o design dos casos de testes.
Na modalidade TDD, é atingida cobertura de testes total. Cada linha de código individual é testada, diferentemente da modalidade tradicional.
A combinação de ambas as abordagens leva a importância de testar o sistema, em detrimento de uma perfeição geral da aplicação
Na metodologia Ágil, o objetivo é "testar com propósito". Deve-se saber o motivo de testar algo e até que nível os testes são necessários.
Acceptance TDD(ATDD): Com o ATDD, escreve-se apenas um único teste de aceite, que atende aos requerimentos da especificação ou satisfaça o comportamento do sistema. Após, escreva código suficiente para atender ao teste de aceite.
+O teste de aceite foca no comportamento geral do sistema, sendo também conhecido como Desenvolvimento Liderado pelo Comportamento(Behavioral Driven Development).
Developer TDD: Com o TDD de Desenvolvedor, um unico teste de developer é escrito, um teste Unitário, e em seguida, código suficiente para atender ao teste. O teste unitário foca em cada funcionalidade do sistema. Simplesmente chamada de TDD.
O objetivo principal do ATDD e TDD é especificar requerimentos detalhados e executáveis para a solução em uma base de Just In Time (JIT). JIT significa levar apenas os requerimentos necessários para o sistema em consideração, de forma a aumentar a eficiência.
#Escalando o TDD Através do Agile Model Driven Develipment (AMDD)
O TDD é muito bom em validações e especificações detalhadas, mas falha em considerar problemas maiores como design geral, uso do sistema e UI. AMDD trata dos problemas de escalabilidade Ágil em que o TDD falha.
Portanto, AMDD é aplicado para problemas maiores.
No AMDD, modelos extensos são criados antes que o código fonte seja escrito.
Cada caixa na figura acima representa uma atividade de desenvolvimento.
Visualização é um dos processos TDD de previsão/imaginação dos testes que serão aplicados durante a primeira semana de projet. O objetivo principal da visualização é identificar o escopo e arquitetura do sistema. Requerimentos de alto nivel e modelagem de arquitetura são feitas para uma visualização eficiente.
É o processo em que não desenvolve-se uma especificação detalhada do sistema ou software, mas sim, exploram-se os requerimentos que definem a estratégia geral do projeto.
Iteração 0: Visualização
Visualização de Requerimentos Iniciais: Pode levar tempo para identificar requerimentos de alto nível e o escopo do projeto. O foco principal é explorar os modelos de uso, modelo de domínio inicial e modelo de UI.
Visualização de Arquitetura Inicial: Também pode ser dispendioso identificar a arquitetura do sistema, que permite definir as diretrizes técnicas do projeto. O foco é explorar diagramas de tecnologia, fluxo de UI, modelos de domínio e casos de Mudança.
Iteração de Modelagem: Aqui, o time deve planejar o trabalho que será desenvolvido em cada iteração.
+
O processo Ágil é utilizado em cada iteração, ou seja, para cada iteração novos itens de trabalho serão adicionados com prioridade.
Trabalhos priorizados serão levados em consideração primeiro. Work Items adicionados podem ser repriorizados ou removidos da pilha de itens a qualquer momento.
O time debate ocmo irão implementar cada requerimento. A modelagem é aplicada para este propósito.
Análise de modelo e design são feitos para cada requerimento que será implementado naquela iteração.
Model Storming: Também conhecida como modelagem Just in Time (JIT).
+
Aqui, a sessão de modeling envolve um itme de 2/3 membros que debatem problemas.
Um membro do time irá pedir a outro para que modelem juntos. Esta sessão irã levar de 5 a 10 minutos, onde membros da equipe juntam-se para compartilhar informações.
Eles exploram problemas até que não possam encontrar a causa principal do problema. Just in Time, caso um membro da equipe identifique o problema que deseja solucionar, irá receber pronto auxílio dos demais membros.
Outros membros do grupo irão explorar o problema, para que então, todos continuem como estavam antes. Este processo também é chamado de modelagem Stand-Up, ou Customer QA Sessions.
Test Driven Develipment (TDD)
Promove testagem confirmatória do código com especificações detalhadas.
Tanto testes de aceite quanto testes unitários são inputs para o TDD;
TDD torna o código mais simples e claro. Ele permite que o desenvolvedor tenha que manter menos documentação.
Revisões
São opcionais, incluem inspeções de código e revisões de modelo.
Isto pode ser feito para cada iteração ou para o projeto inteiro.
Constiue boa opção para prover feedback ao projeto.
# *Test Driven Development (TDD) Vs. Agile Model Driven Development (AMDD)
TDD:
O TDD encurta o loop de feedback de programação.
TDD é especificação detalhada.
TDD promove o desenvolvimento de códigos de alta qualidade.
TDD comunica-se com programadores.
TDD não é visualmente orientado.
Possui escopo limitado para trabalhos de software.
Ambos apoiam o desenvolvimento evolucionário.
AMDD:
Encurta o loop de feedback da modelagem.
Funciona para problemas maiores.
Promove comunicação de alta qualidade entre investidores e desenvolvedores.
AMDD comunica-se com analistas de business, investidores e profissionais de dados.
É orientado visualmente.
Possui escopo amblo incluindo investidores. Envolve trabalhar em prol de um entendimento em comum.
No exemplo, definiremos uma classe de senha. Para esta classe, tentaremos satisfazer as seguintes condições de aceite:
Deve possuir entre 5 e 10 caracteres.
Primeiro, escrevemos o código que atende aos requerimentos acima.
Cenário 1: Para executar o teste, criamos a classe PasswordValidator():
Iremos executar a clase TestPassword() acima.
Output é PASSED como demonstrado abaixo:
Output:
Cenário 2: Aqui podemos ver que no método TestPasswordLength() não há necessidade de criar uma intância da classe PasswordValidator. Instância significa criar um objeto de clase para referir-se aos membros (variáveis/métodos) desta classe.
Iremos remover a classe PasswordValidator pv=new PasswordValidator() do código. Podemos chamar o método isValid() diretamente através do PasswordValidator. iSvALID("Abs123").
Então refatoramos da seguinte forma:
Cenário 3: Após refatorar o output demonstra status de falha, isto ocorre pois removemos a instância, portando não existe referencia para o método não estático isValid().
Então precisamos alterar este método com a adição da palavra "static" antes da booleana como public static boolean isValid (String password). Refatorando a classe PasswordValidator() para remover o erro acima e passar no teste:
Output:
Após as alterações na classe PassValidator() se executarmos o teste o output sera PASSED como demonstrado abaixo:
Devs podem testar seu código no mundo da database, isto consiste, geralmente, de testes manuais ou scripts individuais. Usando o TDD você constrói de baixo para cima, ao longo do tempo, uma bateria de testes automatizados que você ou qualquer outro desenvolvedor podem executar a qualquer momento.
Código mais Limpo, Extensível e com Melhor Design:
Isto auxilia a entender como o código será usado e como isso interage com outros módulos.
Resulta em um melhores decisões de design, e um código que permite melhor manutenção.
TDD permite escreve códigos menores, com responsabilidades simples, ao invés de procedimentos monolíticos com múltiplas responsabilidades. O que torna o código mais simples de se compreender.
Também força a escrever apenas código de produção para passar nos testes baseados em requerimentos de usuário.
Confiança para Refatorar:
Se você refatora um código, existem possibilidades de que ele quebre, logo, possuindo um grupo de testes automatizados, é possível consertar e estes erros antes do lançamento. Avisos apropriados serão dados caso falhas encontradas durante testes automatizadas sejam implementadas.
O uso do TDD resulta em código mais rápido e extensivel, com menos bugs e que pode ser atualizado com riscos mínimos.
Apropriado para Trabalho em Equipe:
Na ausência de qualquer membro do time, outro integrante pode facilmente assumir o trabalho no código, auxiliando o compartilhamento de conhecimento e aumentando a produtividade geral da equipe.
Bom para Desenvolvedores:
Embora desenvolvedores tenham de passar mais tempo ao escrever casos de teste TDD, leva muito menos tempo para realizar o processo de Debugging e desenvolver novas features. Você pode escrever um código mais limpo e simples.
O framework Cypress é uma estrutura de testes ponta-a-ponta open-source baseada em JavaScript capaz de testar qualquer elemento executado em um browser.
A ferramenta pode ser utilizada para:
Testes Unitários
Testes de Integração
Testes ponta-a-ponta
Features
Time Travel: O Cypress realiza capturas de tela a medida que o teste é desenvolvido.
Recarregamentos em Tempo Real: Automaticamente reinicia o teste quando mudanças são feitas.
Spies, stubs e clocks: Verifique e controle o comportamento de funções resposta "so" e temporizadores
Resultados Consistentes: Os testes ficam livres de falhas
Capacidade de Debugg: Indica o exato local em que ocorre erro
Espera Automática: Cypress automaticamente esperará por comandos e associações antes de progredir, portanto, não há necessidade de adicionar "waits" e "sleeps" no teste.
-
-
-
-
-## ❓ About the Project
-
-Software quality is an area of knowledge that involves ensuring that a software product meets requirements, is reliable, efficient, and effective. Software quality is an attribute that can be assessed through testing, which aims to verify if a software product meets requirements and is free of defects.
-
-This project aims to present the fundamentals of software testing, tools, and best practices for those starting in the field of software quality.
-
-
-
-## 🤝 How to Contribute
-
-Contributions make the open-source community an amazing place to learn, inspire, and create. All contributions are **greatly appreciated**.
-
-1. Fork the project.
-2. Create a branch for your new feature (`git checkout -b feature/awesomeFeature`).
-3. Commit your changes (`git commit -m 'Added awesome content'`).
-4. Push to the branch (`git push origin feature/awesomeFeature`).
-5. Open a Pull Request.
-
-### Local Development
-
-To run the project locally, you need to have [Node.js](https://nodejs.org/en/) installed on your machine. We also recommend using [Yarn](https://yarnpkg.com/) as the package manager.
-
-Add environment variables to your path:
-
-```sh
-source scripts/enviroment.sh
-```
-Run the following commands:
- ```sh
-# Install dependencies
-yarn
-
-# Serve with hot reload at localhost:8080
-yarn dev
-```
-### 💁♂️ Authors
-
-Victor Manoel - Software Quality Engineer - @Keeabo
-Victor Wildner - Software Quality Engineer - @vcwild
-
-### 🏷️ License
-This project is licensed under the AGPL-3.0 License. See the [LICENSE](LICENSE) file for more details.
-
-
-
Quality Assurance (QA) also known as QA Tests is an activity that guarantees the best possible quality for the product provided by a company to the final consumer
The QA test in a software involves the testing of:
Performance
Adaptability
Functionality
However, software quality assurance extends beyond the quality of the software itself. The activity also encompasses the quality of the process:
Quality can be simply defined as "fit for use or function". The idea is to meet customers' needs and expectations regarding functionality, design, reliability, durability, and product price.
Assurance is nothing more than a positive statement about a product or service that conveys confidence. It is the assurance that a product or service provides, indicating that it will function exactly as intended.
Assurance ensures that it will work without any problems according to expectations and requirements.
Quality Assurance in testing is defined as a procedure to ensure the quality of software products or services provided to customers by a company.
QA focuses on improving the software development process, making it efficient and effective according to the defined quality parameters for software products.
As a QA engineer, your job is to look for failure points in a product, whatever it may be, and report them so they can be fixed, ensuring the highest quality product.
To perform your function successfully, it's necessary to have the right mindset:
Think as destructively and creatively as possible
Important points:
Know the product you are testing.
Don't be afraid to think outside the box while testing it.
Don't be afraid to use it in the most incorrect way possible.
The software is guilty until proven innocent.
QA is responsible for proving the software is guilty.
In testing techniques, there are two types of tests: traditional and agile.
Traditional tests are based on a waterfall model lifecycle, where testing is conducted after software construction, with a focus on finding defects.
On the other hand, agile tests are based on an iterative and incremental lifecycle model, where testing occurs during software construction, focusing on defect prevention.
Face-to-face Communication: The most effective communication method is in person. Unlike the traditional model where the tester had limited access to other team members, here, developers and testers work side by side.
Continuous Feedback: Working in sprints involves constant testing, providing immediate and progressive feedback to the team.
Continuous Improvement: Both in processes and people, values of transparency, professional development.
Have Courage
Deliver Value to the Customer: Testers need to be close to the customer, understand their needs, and translate them into business-focused test scenarios.
Keep it Simple: The nature of testing is to validate various aspects, but simplification and prioritization based on customer needs are necessary. Use lighter tools to optimize the development process.
Respond to Changes: Adaptability to new scenarios and conditions that may occur during sprints, learning new skills and attitudes to become adaptable.
Self-Organization: Agile teams self-organize to solve a problem in the best way, considering each team member's skills. This dynamic emerges from the team itself, requiring autonomy and collaboration with the team's purpose.
People Focus: Agile methodology is more about people, the human factor, than methodological and bureaucratic factors. Apply all other principles and stay close to other team members for collaboration.
Have Fun
In this context, the tester plays an active and fundamental role in the product development process, from understanding business rules to delivering the complete product.
They must add value by being a quality reference, serving the team and the customer, using their critical and analytical skills to find solutions to the team's problems.
Used throughout the development process, from defining requirements and versioning them for staging, to project versioning for secure and risk-free implementation.
Version control is applied to create stable releases for client delivery, while unvalidated development is restricted to test branches. This ensures there is always a stable, bug-free, and validated version in case an implemented feature breaks the code.
Test Management:
+TestLink allows the creation of test cases and manages their execution, helping identify failed or successful tests. It also assists in assigning tests among team members and supervising the execution.
Defect Management:
+Enables describing the found flaw, assigning severity, work allocation among team members, development tracking, separation by status, inclusion of test evidence, etc.
Test automation tools are used for executing repetitive tests that do not require human intervention, such as interface tests, integration tests, performance tests, security tests, regression tests, etc. It is a broad concept, varying between programming languages and different methodologies for automating manual tests.
Artifacts: Types of tangible subproducts produced during software development. All the involved documentation such as use cases, requirements, and documentation describing the design and architecture.
The inspection process involves planning, individuals reviewing each artifact, meetings for discussions and record-keeping, passing defects back to the author, and an overall assessment regarding the need for a new inspection based on changes during the process.
The term defect is often used generically, but it's essential to understand that the interpretation depends on the usage context. Defects found through inspection relate to deficiencies in the reviewed artifact, software faults described in IEEE 830, 1998.
IEEE defines quality attributes that a requirements document must have; the lack of any of these attributes characterizes a defect:
Omissions 1-5:
1: Important requirement related to functionality, performance, external interface.
2: Software response to all possible input data situations.
3: Lack of sections in requirement specifications.
4: Absence of references like figures, tables, or diagrams; visual representation is common when describing a use case or software specification.
5: Lack of definition of unit measurement terms; in a field, we need to know how many characters it supports, input of text, and a series of components that need unit measurement definition, like a numeral.
Ambiguity: A requirement with multiple meanings in a term for a specific context, making it challenging to understand functionality, leaving room for defects.
Inconsistency: More than one conflicting requirement, conflicting instructions for the same context.
Incorrect Fact: Requirement describing a fact not true considering established system conditions. Asks for A, returns B.
Extraneous Information: Information provided in the requirement that is unnecessary or won't be used; inefficient description, increasing documentation and opening room for conflicting interpretations.
Others: Various, like placing a requirement in the wrong section of the document, applying a rule in the wrong place, for example.
These classes can be further subdivided into more specific classifications depending on the need.
Inspections find errors early in the process, aiming to prevent rework in subsequent cycles, as costs and time exponentially increase throughout the development cycle.
This promotes increased productivity in the team, generating more understandable artifacts, facilitating inspection, and benefiting subsequent phases of the cycle, such as the maintenance phase of the documentation.
During the testing process, it's necessary to identify what needs to be tested. To do this, understanding what a test is and how it's conducted is crucial.
The most detailed way to document a test, scripts typically detail step-by-step actions and necessary data to run the test. It often includes steps to understand how the user interacts, what actions to perform, and in what order, including specific outcomes for each step, such as verifying changes.
+For example, the action might be clicking button X, and the result is a window closing. At the start of a project, the tester might not have an in-depth understanding of the function. Scripts assist in the smooth development of the process and understanding the system. However, projects often undergo changes, with pages redesigned, new features added, etc., so scripts must be regularly updated. The drawback here is that time spent updating the script could be invested in executing more tests. Moreover, scripts are designed to test very specific and repetitive actions, leaving room for bugs outside these predefined paths to go undetected, requiring constant evolution.
The second most detailed way, test cases describe a specific idea to be tested without detailing the exact steps to be executed. For example, testing if a discount code can be applied to a discounted product. This doesn't describe which codes will be used, allowing different approaches to find the result. It provides greater decision flexibility to the tester to complete the test, benefiting experienced testers with a good understanding of the system's nature and functions. However, the absence of this familiarity and experience allows bugs to go unnoticed.
The least detailed documentation, describing the goal the user might achieve when using the program. For instance, testing if the user can log out of the program when closing it. Various techniques are needed to properly validate and test the function, as scenarios provide minimal specification. Testers have ample flexibility in developing the test. This flexibility offers the same pros and cons as seen in test cases, being liberating for experienced testers and nearly impossible for novices.
A combination of these modalities, often used simultaneously, can be employed, divided among the team based on their different skills and competencies within the project's specific context.
When conducting tests, it's necessary to write test cases for organized and standardized testing. Incident reports should be documented to fix issues and ensure software quality. Additionally, prioritizing incidents is essential to fix them according to their importance.
An informal and general explanation of a software feature written from the perspective of the end user. Its purpose is to articulate how a software feature can deliver value to the customer. They are not system requirements but are key components in development that emphasize end users, using non-technical language to provide context to the development team, instructing them on what they are building and what value it will generate for the user.
They enable a user-centered structure, promoting collaboration, creativity, and product quality. They articulate how a single task can offer specific value to the customer.
They are written in a few sentences with simple language that outlines the desired result. Requirements are added later once the team agrees on the user stories.
Title: It should be concise, simple, and self-explanatory, providing information so the analyst knows the validation the test aims for (Validate User Registration, Order Placement, etc.).
Detailed Objective: Describe what will be executed, providing an overview of the test to be performed. For example, "Check if file upload with allowed extensions is possible," "Verify if the purchase order is sent with information on asset, quantity, price, etc."
Preconditions Necessary for Execution: Prevents necessary information from being missing, such as not specifying that the user must be registered to perform the test. These are fundamental elements for the test to be executed correctly, such as the need for the user to have registered a note previously to test the query. The absence of preconditions will result in a flawed and inefficient test.
Defined Steps: Describe all actions the analyst must follow during execution until reaching the expected result. "Access X functionality," "Click on Y button," "Fill out the presented form," "Check if a blank form is displayed."
Expected Results: Describes the expected system behavior after executing the steps. "Valid," "Displays," "Recovers," "Returns." It should be direct and clear to avoid false positives. "System displays an editing screen with filled fields," "The order is sent and results in the informed price," "Registration is saved in the database."
The case should be self-sufficient, including all necessary information for execution within its body. It should be concise, optimizing execution time, and should have as few steps as possible, facilitating the understanding of the required stages.
It's also necessary to include both valid and unexpected inputs, as well as valid and expected inputs.
Severity: Defines the degree or intensity of a defect concerning its impact on the software and its operation.
S1 - Critical/Showstopper: Testing blockage or functionality that causes the application to crash or affects major use cases of key functionalities, security issues, severe data loss. Blockages that prevent testing other functions.
S2 - Major: Problems related to unexpected information, unwanted defects, unusual input that causes irreversible effects, etc. Navigation is possible but generates significant errors in function.
S3 - Moderate: Functionality does not meet certain acceptance criteria, such as error and success messages not displayed.
S4 - Minor: Has little impact, interface errors, typos, misordered columns, design flaws.
Priority: Bugs viewed from a business perspective, indicating which ones should be fixed first based on demand and current context.
P1 - Critical: Must be fixed immediately. Severity 1, performance errors, graphical interface affecting the user.
P2 - High: Functionality is not usable as it should be due to code errors.
P3 - Medium: Problems that can be evaluated by the developer and the tester for a later cycle depending on available resources.
P4 - Low: Text errors, minor user experience and interface improvements.
Testing methodology where the end user is asked to use the software to check ease of use, perception, system performance, etc. A precise way to understand the customer's perspective, using prototypes, mocks, etc.
#9) What is coverage, and what are the different coverage techniques?
A parameter to describe how much source code is tested.
Statement Coverage: Ensures that each line of code was executed and tested.
Decision Coverage: Ensures that all true and false paths were executed and tested.
Path Coverage: Ensures that all possible routes through a specific part of the code were executed and tested.
#10) A defect that could have been removed during the initial stage is removed at a later stage. How does this affect cost?
Defects should be removed as early as possible because postponing removal increases costs exponentially. Early-phase removal is cheaper and simpler.
Regression: Confirms that a recent code change does not adversely affect existing features.
Confirmation: When a test fails due to a defect, it is reported, a new version of the corrected software is sent, and the test is re-run. This is confirmation of the correction.
#12) What is the basis for estimating your project?
To estimate a project, you should:
Break down the entire project into smaller tasks.
Assign each task to team members.
Estimate the effort required to complete each task.
Validate the estimation.
#13) Which test cases are written first: white box or black box?
Usually, black box test cases are written first.
Since these only require requirements and design documents or a project plan, these documents are readily available at the beginning of the project.
White box tests cannot be executed in the initial project phase because they require a clearer understanding of the architecture, which is not available in the early stages. Therefore, they are generally written after black box tests.
#14) Mention the basic components of the defect report format
Wrong: Indicates that requirements were implemented incorrectly, a deviation from the provided specification.
Missing: A variation from the specifications, an indication that a specification was not implemented, or a customer requirement was not noted correctly.
Extra: An attribute desired by the product's end user, not provided by the final customer. It is always a deviation from the specification but may be a desired attribute by the product's user.
#17) On what basis is the acceptance plan prepared?
Requirement Document: Specifies what is required in the project from the customer's perspective.
Customer Input: May include discussions, informal conversations, emails, etc.
Project Plan: The project plan prepared by the project manager also serves as good input to finalize acceptance testing.
#18) Why is Selenium the preferred tool for automation testing?
Selenium is an open-source tool designed to automate web browser testing. Since Selenium is open source, there is no licensing cost, which is a significant advantage over other testing tools. Other reasons include:
Test scripts can be written in various programming languages: Java, Python, C#, PHP, Ruby, Perl, and more.
Tests can be conducted in various web browsers: Mozilla, IE, Chrome, Safari, or Opera.
It can be integrated with tools like TestNG and JUnit for test case management and report generation.
Integration with Maven, Jenkins, and Docker for continuous testing.
#20) What are the different types of locators in Selenium?
A locator is an address that uniquely identifies a web element within a web page. To identify web elements accurately, Selenium offers different types of locators, including:
XPath, also known as XML Path, is a language for querying XML documents. It is a crucial strategy for locating elements in Selenium automation. XPath comprises a path expression along with certain conditions. Here, you can easily write an XPath script/query to locate any element on a web page. XPath is designed to enable navigation of XML documents with the aim of selecting individual elements, attributes, or specific parts of an XML document for processing. It also produces reliable locators.
#22) What is the Difference Between Absolute and Relative Path?
Absolute XPath:
It is the direct way to locate an element, but the disadvantage of absolute XPath is that if there is any change made to the element's path, the XPath will fail. For example:
/html/body/div[1]/section/div[1]/div
+
Relative XPath:
For relative XPath, the path starts in the middle of the HTML DOM structure. It begins with a double forward slash (//), which means it can search for the element anywhere on the web page. For example:
Selenium Grid can be used to execute identical or different test scripts on multiple platforms and browsers simultaneously, enabling distributed test execution, testing across different environments, and saving execution time.
The following syntax can be used to launch the browser:
WebDriver driver = new FirefoxDriver()
Driver WebDriver = new ChromeDriver()
Driver WebDriver = new InternetExplorerDriver()
#25) Should Testing Be Done Only After the Completion of Development and Execution Phases?
Testing is always done after the development and execution phases. The earlier a defect is detected, the more cost-effective it is. For example, fixing a defect during maintenance is ten times more expensive than fixing it during execution.
#26) What Is the Relationship Between the Reality of the Environment and Testing Phases?
As testing phases progress, the reality of the environment becomes more crucial. For instance, during unit testing, you need the environment to be partially real, but in the acceptance phase, you must have a 100% real environment, or we can say it should be the real environment.
Usually, in random testing, data is generated randomly, often using a tool. For example, the figure below demonstrates how randomly generated data is fed into the system.
This data is generated using an automated tool or mechanism. With this random input, the system is then tested, and the results are observed.
It is an advanced framework designed to leverage the benefits of developers and testers. It also has a built-in exception handling mechanism that allows the program to run without unexpectedly terminating.
The code below helps you understand how to set the test case priority in TestNG:
```java
+ package TestNG;
+ import org.testing.annotation.*;
+
+ public class SettingPriority {
+ @Test(priority=0)
+ public void method1() {}
+
+ @Test(priority=1)
+ public void method2() {}
+
+ @Test(priority=2)
+ public void method3() {}
+ }
+ ```
+
Test execution sequence:
Method1
Method2
Method3
#33) What Is Object Repository? How Can We Create an Object Repository in Selenium?
Object repository refers to the collection of web elements belonging to the Application Under Test (AUT) along with their locator values. In the context of Selenium, objects can be stored in an Excel spreadsheet that can be filled within the script whenever needed.
#40) How to Enter Text in a Text Box Using Selenium WebDriver?
Using the sendKeys() method, we can enter text into the text box.
#41) What Are the Different Deployment Strategies for End Users?
Pilot
Gradual Rollout
Phased Implementation
Parallel Implementation
#42) Explain How You Can Find Broken Links on a Page Using Selenium WebDriver
Let's assume the interviewer presents 20 links on a web page, and we need to check which of these 20 links are working and which ones are broken.
The solution is to send HTTP requests to all the links on the web page and analyze the response. Whenever you use the driver.get() method to navigate to a URL, it will respond with a status of 200-OK. This indicates that the link is working and was successfully retrieved. Any other status indicates that the link is broken.
First, we have to use the anchor tags <a> to identify the different hyperlinks on the web page.
For each <a> tag, we can use the 'href' attribute value to get the hyperlinks and then analyze the response received when used in the driver.get() method.
#43) Which Technique Should Be Considered in the Script If There Is No ID or Name of the Frame?
If the frame's name and ID are not available, we can use frame by index. For example, if there are 3 frames on a web page, and none of them have a frame name or ID, we can select them using a frame index attribute (zero-based).
Each frame will have an index number, with the first one being "0", the second one "1", and the third one "2".
driver.switchTo().frame(int arg0);
+
#44) How to Take Screenshots in Selenium WebDriver?
You can capture screenshots using the TakeScreenshot function. With the help of the getScreenshotAs() method, you can save the captured screenshot.
#45) Explain How You Would Log into Any Site if It Shows an Authentication Pop-Up for Username and Password?
If there is a login pop-up, we need to use the explicit command and check if the alert is actually present. The following code helps understand the use of the explicit command.
It defines a sample variable of type WebElement and uses an Xpath search to initialize it with a reference to an element containing the text value "data".
Testing an application is a process that must be done with great care because it ensures that the software is working correctly and there are no defects that could harm the user. However, creating tests is not an easy task. There are two approaches that can be used to create tests, each with its advantages and disadvantages. They are:
Proactive: where the test design process starts as early as possible to find and fix errors before the build is created.
Reactive: an approach where testing does not start until after the design and development are complete.
Given these two approaches, we can say that the proactive approach is the most recommended because it allows tests to be created before the code, enabling the developer to fix errors before the code is implemented. On the other hand, the reactive approach is more commonly used in projects with tight schedules as it allows development to be done first, followed by testing.
Testing approaches can be divided into two categories, black-box and white-box. The difference between them is that black-box focuses on the system's behavior, while white-box focuses on the internal structure of the code.
Black-box tests are the most commonly used because they are easier to implement and do not require knowledge of the programming language used. Moreover, they are easier to understand for non-technical individuals and can be implemented in different programming languages.
Key aspects of black-box tests include:
Primary focus on validating functional business rules.
Provides abstraction to the code and focuses on the system's behavior.
White-box tests are more challenging to implement as they require knowledge of the programming language used. They are also harder to understand for a layman and are more difficult to implement in different programming languages.
Some key aspects of white-box tests include:
Validates internal structure and functionality of code.
Knowledge of the programming language used is essential.
Does not facilitate test communication between modules.
Some of the key concepts defining white box testing are:
Involves testing the internal mechanisms of an application; the tester must be familiar with the programming language used in the application being tested.
Code is visible to testers.
Identifies areas of a program that have not been exercised by a set of tests.
A technique where the internal structure, design, and code are tested to verify the input-output flow and improve design, usability, and security.
Here, the code is visible to testers, also referred to as Transparent Box Testing, Open Box Testing, Glass Box Testing, etc.
The first thing a tester will typically do is learn and understand the application's source code.
+Since White Box Testing involves testing the internal mechanisms of an application, the tester must be familiar with the programming language used in the application being tested.
+Additionally, the tester must be aware of coding best practices.
+Security is often a primary goal of software testing; the tester must locate security breaches and prevent attacks from hackers and users who can inject malicious code into the application.
The second basic step for white box testing involves testing the source code for proper flow and structure.
One way to do this is by writing additional code to test the source code.
The tester will develop small tests for each process or series of processes in the application; this method requires the tester to have an intimate knowledge of the code and is often done by the developer.
Other methods include manual testing, trial and error, and the use of testing tools.
Consider a simple code example for white box testing:
voidprintme(int a,int b){// Printme is a function
+ int result = a + b;
+
+ if(result >0)
+ print("Positive", result)
+ else
+ print("Negative", result)
+}// End of the source code
+
The goal of White Box Testing in software engineering is to verify all decision branches, loops, and statements in the code.
Often the first type of test applied to a program.
Unit testing is performed on each unit or block of the code during its development. It is essentially done by the developer, who develops a few lines of code, a single function, or an object and tests to ensure it works before moving forward.
This type helps identify most bugs in the early stages of software development, being cheaper and faster to fix.
In this test, the tester/dev has complete information about the source code, network details, IP addresses involved, and all server information where the application runs.
+The goal is to attack the code from various angles to expose security threats.
Black box testing aims to verify whether the system under scrutiny is functioning correctly, meaning it adheres to business rules and system specifications.
Black box tests have the following characteristics:
Testing where the internal functionalities of the code are not accessible to the tester.
Done from the user's perspective.
Entirely focused on business rules and application specifications, also known as Behavioral Testing.
To apply black box testing, the tester must follow these steps:
Initially, business rules and specifications are examined.
The tester selects valid inputs (positive scenario testing) to check if the system processes them correctly. Invalid inputs (negative scenario testing) are also tested to verify if the system detects them.
The tester determines the expected outputs for each of the selected inputs.
The tester constructs test cases with the selected inputs.
Test cases are executed.
The tester compares actual outputs with ideal outputs.
Functional Testing: Related to the business rules of a system; conducted by testers.
Non-Functional Testing:Not related to testing any specific feature but rather non-functional business rules like performance, scalability, and usability.
Regression Testing: This mode is applied after any fixes, upgrades, or maintenance in the code to verify if these changes have not affected features previously tested successfully.
The following techniques are used to test a system:
Equivalence Class Testing: Used to minimize the number of possible test cases to an optimized level while maintaining reasonable coverage.
Boundary Value Analysis: Focuses on values at boundaries. This technique determines if a certain range of values is acceptable by the system or not, very useful for reducing the number of test cases. It is more appropriate for systems where an input falls within certain scopes.
Decision Table Testing: A decision table inserts causes and their effects into a matrix, with a unique combination in each column.
Gray box tests are a combination of white-box and black-box testing methods. They are used to test a product or application with partial knowledge of the application's internal structure. The purpose of this testing is to search for and identify defects caused due to improper application structure or usage.
Some of the key characteristics of gray box testing are:
It is a combination of white-box methods (with complete code knowledge) and black-box methods (with no code knowledge).
System defects can be reduced or prevented by applying gray box testing.
It is more suitable for GUI, functional, security, web applications, etc.
In this process, context-specific errors related to web systems are commonly identified. This improves test coverage by focusing on all layers of any complex system.
In QA, gray box testing provides an opportunity to test both the front-end and back-end of an application.
The primary techniques used for gray box testing are:
Matrix Testing: This testing technique involves defining all variables that exist in a program.
Regression Testing: To check if the change in the previous version has regressed other aspects of the program in the new version. This will be done by testing strategies like retest everything, retest risky features, and retest within a firewall.
Matrix or Action-Oriented Testing (OAT): Provides maximum code coverage with a minimum number of test cases.
Pattern Testing: This technique is performed on historical data from the previous version's defects in the system. Unlike black-box testing, gray box testing operates by digging into the code and determining why the failure occurred.
Functional testing is a type of testing that validates the system against specifications and acceptance criteria. The purpose of this type of testing is to test each function of the software by providing appropriate input and verifying the output according to the functional requirements.
Let's explore some of the key functional testing techniques.
Equivalence partitioning is a testing technique based on requirements in the documentation.
Executed through the black-box approach, it provides the tester with a clear understanding of test coverage based on requirements and specifications.
It does not require knowledge of internal paths, structure, and implementation of the software under test and reduces the number of test cases to a manageable level. It is intuitively used by most testers.
Partitioning divides user inputs into partitions or classes of equivalence, and then subdivides them into ranges of possible values, so that one of these values is elected as the basis for the tests. There are partitions for:
Valid values, which should be accepted by the system.
Invalid values, which should be rejected by the system.
Consider a human resources system in a company that processes employee requests based on age. We have a business rule related to age stating that individuals under 16 years old cannot work, individuals between 16-60 years old are eligible for hire, and those who are 60 years old or older are not suitable for the job.
Dividing these rules, we have:
Invalid partition: 0-15
Valid partition: 16-60
Invalid partition: 60-
Equivalence partitioning guides us to choose a subset of tests that will find more defects than a randomly chosen set.
When working with partitions, we observe a maxim that states:
"Any value within a partition is as good as any other."
+
Therefore, values belonging to the same partition must be treated equally by the system, meaning they will produce the same result. Thus, any value within the equivalence class, in terms of testing, is equivalent to any other.
To achieve satisfactory test coverage when implementing this technique, test cases must cover all existing partitions. In the example under analysis, we have identified 3 partitions.
A test script for age validation in the hiring module would have 3 test cases:
C1: Age = 5
According to the rule, it should not work; the expected value is "Should not hire."
C2: Age = 33
According to the rule, it can work; the expected value is "Can hire."
C3: Age = 65
According to the rule, it should not work; the expected value is "Should not hire."
It is understood that within the range of values 0-15, regardless of which one is selected within the invalid partition, it should not be accepted by the system. The same applies to the range of 16-60, multiple possibilities that result in acceptance in the system.
It is not necessary to test all possible values; the coverage is sufficient when choosing one within each partition.
It assumes that the behavior at the edge of a partition is more likely to cause errors.
In the example, with the boundary value technique, we would select the value 15, invalid according to the system, then we select 16, borderline, but it should yield a positive result.
A good practice of combining techniques is to select a random value for each partition, test it, and then validate the boundary values within each partition.
Decision Table:
A relevant method for documenting business rules to be followed by the system, created from the analysis of functional specifications and identification of business rules.
The table contains trigger conditions, combinations of true or false for data entry, and results for each of the combinations. It is a way to express in a tabular form which set of actions should occur to arrive at an expected result.
The main point of the table is the business rule, which defines the set of actions to be taken based on a set of conditions.
In the example, if we know that from 0-15 should not work, in the table, we establish that
0-15 Cannot
16-60 Can
This combination can/cannot, is a visual representation to assist in documenting the rules the system follows.
It is based on the idea that a system can exhibit different behaviors depending on its current state or previous events. Creating a diagram allows the test to visualize the statuses, i.e., the transitions, data entry, and events that trigger actions.
The technique helps identify possible invalid transactions because knowing what the system expects, when testing the combinations, we can discover faulty transactions.
A person can be eligible to work and then become ineligible, invalid.
These are techniques where tests are derived from the skills and experience of the tester, the individual visualization capability of the professional, based on their past work, enabling them to find errors and faults that others may not discover.
User Acceptance Testing (UAT), often simply called acceptance testing, is a type of testing applied by the end user or the client to verify and accept the system before progressing the application to the production environment.
User Acceptance Testing is performed at the end of the testing phase, after functional, integration, and system testing.
The primary purpose of UAT is to validate the flow from start to finish.
It does not focus on cosmetic errors, typos, or system testing, and is conducted in a separate test environment with a setup similar to the production environment.
It is similar to black-box testing where two or more end-users are involved.
The need for this test arises once the software has passed integration, system, and unit testing, as developers might have built the software based on documented business rules under their own understanding, leaving a chance that any further necessary changes during this phase might not have been efficiently communicated to them.
Therefore, to verify if the final product is acceptable to the customer/user, this test becomes necessary.
The test plan defines the strategy that will be applied to verify and ensure that the application meets the acceptance conditions. It documents entry and exit criteria for UAT, the approach for scenarios and test cases, as well as the testing timeline.
Identification of scenarios will respect the business process and create clear test cases. The cases should sufficiently cover most of the UAT scenarios. Business use cases are inputs for creating test cases.
Using real-time data for UAT is recommended. The data should be scrambled for security and privacy reasons. Testers should be familiar with the database flow.
Business Analysts or UAT Testers need to provide a statement after testing. With this confirmation, the product is ready to proceed to Production. Deliverables for UAT are the Test Plan, UAT scenarios and test cases, results, and defect log.
Exploratory testing involves evaluating a product by learning about it through exploration and experimentation, including:
Questioning;
Study;
Modeling;
Observation;
Inference;
Often described as simultaneous learning, test design, and execution, it focuses on discovery and relies on the individual tester's guidance to uncover potential defects not easily covered within the scope of other tests.
Most software quality tests use a structured approach, with test cases defined based on metrics such as user history and software engineering parameters, ensuring adequate coverage from a technical perspective.
What's lacking is coverage for extreme cases, which are checked during UAT and tested based on user personas. Exploratory Testing, on the other hand, is random, or unstructured by nature, and can reveal bugs that wouldn't be discovered in structured testing modes.
Test execution is implemented without creating formal steps, making it a precursor to automation.
It helps formalize discoveries and automate documentation. With the aid of visual feedback and collaborative testing tools, the entire team can participate in exploratory testing, enabling quick adaptation to changes and promoting an agile workflow.
Moreover, testers can convert exploratory test sequences into functional test scripts, automating the process.
Hence, exploratory testing speeds up documentation, facilitates unit tests, and helps create an instant feedback loop.
It is suitable for specific scenarios, such as when someone needs to learn about a product or application quickly and provide rapid feedback. Exploratory testing helps assess quality from the user's perspective.
In many software cycles, an initial iteration is necessary when teams don't have much time to structure tests; exploratory tests are quite useful in this scenario.
Exploratory testing ensures no critical failure case goes unnoticed, guaranteeing quality. It also assists in the unit testing process, with testers documenting steps and using this information to test more broadly in subsequent sprints.
It is especially useful when finding new test scenarios to enhance coverage.
Organizations should be able to strike a balance between exploratory and scripted testing. Exploratory tests alone cannot offer sufficient coverage; they are thus complementary to scripted tests in some cases.
Especially in regulated or compliance-based testing, which requires scripted testing. In these cases, specific checklists and mandates need to be followed for legal reasons, making scripted testing preferable.
An example is accessibility tests that follow legal protocols with defined standards needing approval.
// CI/CD: Continuous Integration/Continuous Delivery, a method to deliver applications frequently to customers. //
Exploratory tests open testing to everyone, not just trained testers, making review faster and more efficient and allowing people beyond the traditional tester to participate.
Exploratory tests complement QA team testing strategies, including a series of undocumented test sessions to find yet-to-be-discovered bugs.
When combined with automated tests and other practices, they increase test coverage, discover extreme cases, and potentially add new features and improvements to the product.
Without structural rigidity, they encourage experimentation, creativity, and discovery within teams.
The almost instant nature of feedback helps bridge gaps between testers and developers, but most importantly, the results provide a user-oriented perspective and feedback for development teams.
The goal is to complement traditional tests and uncover hidden defects behind the traditional workflow.
Sanity testing is a type of testing performed after receiving a software build with minor changes in the code or functionality, to ensure that bugs have been fixed and no new issues have been introduced.
The goal is to ensure that the proposed functionality works rudimentarily as expected.
If it fails, the build is rejected to avoid the expenditure of time and resources involved in more rigorous testing.
Sanity testing is a subset of regression testing and is applied to ensure that changes in the code work appropriately. It is a step to check whether the build can proceed to further testing or not.
The focus of the team during sanity testing is to validate the application's functionality, not detailed testing.
It is usually applied to a build where the production implementation is needed immediately, such as a critical bug fix.
In an e-commerce project, the main modules are the login page, the home page, and the user profile page.
There is a defect in the login page where the password field accepts fewer than 4 alphanumeric characters, while the business rules state that this field should not be less than eight characters. Therefore, the defect is reported by QA for the developer to fix.
The developer then fixes the issue and sends it back to the testing team for approval.
QA checks whether the changes made are working or not.
It is also determined whether this has an impact on other related functionalities. Assuming there is now a feature to update the password on the user profile screen, as part of the sanity test, the login page is also validated, as well as the profile page to ensure both work well with the addition of the new function.
Regression testing is a type of testing used to confirm that recent changes in the code have not adversely affected existing features.
Regression testing is a black-box testing technique, where test cases are re-executed to verify that previous functionalities of the application are working as intended and that new additions have not introduced any bugs.
It can be applied to a new build when there is a significant change in the original functionality, as it ensures that the code still works once changes occur. Regression means "re-testing" these parts of the application that remain unchanged.
Regression Testing is also known as Verification Method; test cases are often automated since they need to be executed repeatedly during the development process.
Whenever the code is modified, such as in the following scenarios:
New Feature Added to the Application
+Example: A website has a login feature that allows login via Email. Now providing the option to log in with Facebook.
When There is a Requirement Change
+Example:
+"Remember Password" function removed from the login page.
When a Defect is Fixed
+Example:
+A bug was found and reported, once the development team has fixed it, the QA team will retest it to ensure the issue has been resolved. Simultaneously testing other related functionalities.
When There is a Fix for Performance Issues
+Example: the loading time of a home page was 5 seconds, and an update reduces it to 2 seconds.
When There is a Change in Environment
+Example: the project moves from the Testing environment to the Production environment.
If the software undergoes constant changes, regression tests will become increasingly costly, as will the time invested in this process when done manually.
In such situations, automation is the best choice.
Selenium(opens new window): an open-source tool used for automation testing in a web application. For browser-based regression tests, Selenium is utilized as well as for UI-level regressions.
# What are Regression Testing and Configuration Management?
Configuration Management in regression testing becomes imperative in Agile Methodology environments where code is continually changed.
To ensure valid regression testing, we must follow these steps:
Changes in the code are not allowed during the regression testing phase.
A regression test case should consist of unchanged development changes.
The database used for regression must be isolated, and changes are not allowed.
# What Are the Differences Between Re-Testing and Regression Testing?
Re-Testing:
Means testing the functionality again to ensure the code correction. If not fixed, defects must be re-opened; if fixed, the defect is closed.
Re-testing is applied to check if failed test cases in the final run obtain success after the defects have been fixed.
Re-tests work to detect fixes.
Defect verification is part of the process.
Priority is higher than regression tests, therefore, performed earlier.
It is a planned test.
Cannot be automated.
Regression Testing:
Means testing the application when it undergoes a change in the code to ensure the new code has not affected other existing parts of the software.
Does not include defect verification.
Based on project type and resource availability, regression testing can run parallel to re-testing.
It is a generic test.
Can be automated.
Checks for unintended side effects.
Occurs when modifications or changes become mandatory for the project.
Unit testing is a testing technique where individual units or components of software are tested.
The purpose is to validate if each unit of the code functions satisfactorily.
It is applied during the development phase (coding phase) of an application by developers. This practice isolates a section of code and checks its integrity, which can be an individual function, method, procedure, module, or object.
To execute this technique, developers write a section of code to test a specific function in the application, which can also be isolated for more rigorous testing that reveals unnecessary dependencies between the function under test and other units, allowing them to be eliminated.
This type of testing is commonly done automatically, but it can still be performed manually. Neither has a bias, although automation is preferable.
Regarding the automated approach:
The developer writes a section of code in the application solely to test the function.
The developer might also isolate the function for more rigorous testing, helping to identify unnecessary dependencies between the code under test and other units in the product.
A coder generates automation criteria to validate that the code works. During the test case execution, the framework logs all failures, with some tools automatically reporting them and, depending on severity, halting any further tests.
Unit testing relies on creating mock objects to test sections of code that are not yet part of a complete application. Mocks fill in the missing parts in the program.
For instance, you may have a function that depends on variables or objects that have not been created yet. In unit testing, these will be replaced by mocks created only for the test to be conducted on the specific section.
Developers seeking to learn what functionality is provided from a unit and how to use it can look at unit tests again and gain a basic understanding of the API;
Unit Testing allows programmers to refactor the code at a later stage, ensuring that the module still works correctly (Regression Testing). The procedure is to write test cases for all functions and methods to ensure that new changes do not fail, which can be quickly identified and corrected;
Due to the modular nature of unit testing, we can test parts of the project without waiting for others to be completed (mocks);
Unit tests should be independent. In case of any improvements or changes in business rules, the tests should remain unchanged;
Test only one piece of code at a time;
Follow clear and consistent naming guidelines for test units;
In case of code changes or any module, ensure there is a corresponding unit test case, and the module passes the tests before altering the implementation;
Bugs identified in this technique should be fixed before proceeding to other phases of the Development Cycle;
Adopt a "test while you code" stance. The more code is written without tests, the more paths need to be checked.
A technique that verifies whether the deployed version of the software is stable or not.
It consists of a minimal set of tests applied to each software build to verify its functionalities.
Also known as "Build Verification Testing" or "Confidence Testing."
+
In simple terms, smoke testing validates if vital features are working and if there are no showstoppers in the build under test.
It is a quick and small regression test only to test the core functionalities, determining if the build is so faulty that it renders further tests a waste of time and resources.
Applied whenever new features are developed and integrated with an existing build, which is then deployed in the QA environment, ensuring all functionalities are working perfectly or not.
If the build is positively verified by the QA team in Smoke Testing, the team proceeds with functional testing.
This technique is generally done manually, although achieving the same effect through automation is also possible and varies from company to company.
Manual Testing:
+Performed to ensure that critical paths' navigation is operating as expected and not hindering functionality.
+Once the build is handed over to QA, high-priority test cases should be taken to locate major defects in the system.
+If the build passes, we proceed to functional testing. If the test fails, the build is rejected and sent back to the development team, restarting the cycle.
Automated Testing:
+Automation is used for regression testing; however, we can also apply it to these test cases, streamlining the verification process of new builds.
+Instead of the inefficient process of repeating all tests whenever a new build is implemented, we can automate the necessary steps, saving time and resources.
It is a type of testing where software modules are logically integrated and tested as a group.
A typical software project consists of multiple modules, coded by different programmers; the purpose of this level of testing is to expose defects in the interaction between these integrated modules. This technique focuses on validating the data communication between these modules, also known as I & T (Integration and Testing), String Testing, and sometimes Thread Testing.
Even though each module is unit-based, defects still exist for various reasons:
A module is generally designed by an individual developer, who may have a different understanding and logic than other programmers;
During module development, there is a high chance of changes in business rules from clients. These new requirements might not be thoroughly unit-tested, necessitating integration testing of the system;
The interface between modules and the database might be erroneous;
External hardware interfaces, if any, could be erroneous;
Integration testing cases differ from other testing modalities in that they primarily focus on the interfaces and data flow/information between modules.
The focus here is on integration links rather than the unit functions already tested.
#Integration Testing Cases Samples for the Following Scenario:
Application has 3 modules
Login Page;
Mailbox;
Delete Emails;
All integrated logically.
Here, we don't concentrate on testing the Login Page since tests for this feature have already been conducted in Unit Testing. Instead, we check its integration with the Mailbox.
Similarly, we check the integration between the Mailbox and the Delete Emails module.
Test Cases:
+
Case 1
+
Objective: Verify the interface link between Login and Mailbox;
Test Case Description: Enter login credentials and click the Login button;
Expected Result: Redirected to Mailbox;
Case 2
+
Objective: Check the interface link between Mailbox and Delete Emails;
Test Case Description: From Mailbox, select the email and click a delete button;
Expected Result: Selected email appears in the deleted/trash folder;
It is an integration testing approach where all components or modules are integrated together all at once and tested as a unit.
This combined set of components is considered as one entity during testing; if any of the components in the unit are incomplete, integration will not be executed.
Pros:
+
Convenient for small systems
Cons:
+
Difficult to locate faults;
Given the number of interfaces needing to be tested in this method, some interface connections might easily be overlooked;
Since integration testing can only start after "all" modules have been architected, the testing team will have less time for execution in the testing phase;
Given that all modules are tested at once, critical high-risk modules are not isolated and tested as a priority. Peripheral modules handling fewer user interfaces are not isolated for priority testing.
In this approach, testing is done by integrating two or more logically related modules, then tested for proper functioning of the application.
Then, other related modules are incrementally integrated, and the process continues until all logically related modules have been successfully tested.
Stubs and Drivers:
+These are dummy programs used to facilitate testing activities. These programs act as substitutes for missing modules in testing. They don't implement the entire logic of the module but simulate data communication with the calling module during testing.
+ - Stub: is called by the sub-test modules.
+ - Driver: calls the module to be tested.
+
It is the strategy where the lowest-level modules are tested first.
These already tested modules are then used to facilitate testing of higher-level modules. The process continues until all the top-level modules have been verified.
Once low-level modules have been tested and integrated, the next level of modules is formed.
Pros:
+
Fault localization is easier;
No time is wasted waiting for all modules to be developed as in the Big Bang approach.
Cons:
+
Critical modules (at the top level of the software architecture) controlling the application flow are tested last and may be prone to defects;
A method where testing starts from the top and moves down following the software system's control flow.
Higher levels are tested first, followed by lower levels, which are integrated to check software functionality. Stubs are used to test if some modules are not ready.
Pros:
+
Fault localization is easier;
The possibility of getting a prototype;
Critical modules are tested as a priority; significant design flaws can be identified and corrected first.
Here, the highest-level modules are tested together with the lowest-level ones. Simultaneously, the lower ones are integrated with the higher ones and tested as a system.
It combines both Top-Down and Bottom-Up approaches, so it's called Hybrid Integration Testing.
Consider the following best practices for integration testing:
First, determine the integration testing strategies that can be adopted, and then prepare test cases and data accordingly.
Study the application architecture and identify critical modules for priority testing;
Obtain the interface design from the Architecture team, create test cases to verify all interfaces in detail. Interface for database/external hardware/software applications must be thoroughly tested;
After test cases, test data plays a crucial role;
Always have the mock data prepared before executing. Do not select test data during test case execution;
Non-functional testing is a type of technique to test non-functional parameters such as reliability, load testing, performance, and software responsiveness.
The primary purpose is to test the system's read speed under non-functional parameters.
These parameters are never tested before functional tests.
It is essential to confirm that the reliability and functionality, the software's requirement specifications serve as the basis for this testing method, enabling QA teams to check if the system complies with user requirements.
Increasing the usability, effectiveness, maintainability, and portability of the product are the goals of non-functional testing. This helps decrease manufacturing risks associated with non-functional components of the product.
Load testing is a type of performance test for a system or software product under real-life load conditions.
Here, we determine the system's behavior when multiple users use the application simultaneously. It is the system's response measured under varying load conditions.
Determine if the latest infrastructure can handle the application or not;
Determine the application's sustainability under extreme user loads;
Discover the total number of users that can access the application simultaneously;
Determine the application's scalability;
Allow more users to access the application.
Test Environment Setup: First, create a dedicated environment to conduct the load test; this ensures it is done appropriately.
Load Test Scenario: Here, scenarios are created, and then, load test transactions are determined for the application, and data is prepared for each transaction.
Execution of Test Scenarios: Different measurements and metrics are collected to gather information.
Results Analysis;
Re-Tests: If a test fails, it is conducted again to obtain the correct result.
Metrics are used to understand the performance of load tests under different circumstances. This tells us how accurate the test is in each different scenario.
There are many metrics, such as:
Average Response Time: Measures the time it takes for a response from a request generated by the client or user. It also shows the application's speed depending on how long the response takes for all requests made.
Error Rate: Mentioned in terms of percentage and denotes the number of errors occurring during requests to the total requests. These errors usually occur when the application can no longer support the requests in the given time or due to other technical issues. This makes the application less efficient as the error rate rises.
Throughput: Used to measure the amount of bandwidth consumed during load scripts or tests. It is also used to determine the amount of data used to check the requests flowing between the user's server and the main application server. It is measured in kilobytes per second.
Requests per Second: Tells us how many requests are generated to the application server per second. Requests can be anything from requests for images, documents, web pages, articles, or anything else.
Concurrent Users: This metric is used to determine how many users are actively present at a specific or any given time. It merely keeps track of the count of those who visit the application at any time, without raising any requests within the application. From this, we can easily identify peak times.
Peak Response Time: Measures the time taken to handle the request. It also helps find the duration of the peak period (the longest time) in which the request/response cycle is taking more time.
Features and functionalities supported by a software are not the only concerns. API performance, including response time, reliability, resource usage, and scalability, is also crucial.
The goal is not to find bugs but to eliminate performance bottlenecks.
Performance testing is applied to provide investors with insights about their applications regarding performance factors. More importantly, it reveals what needs improvement before the product goes to market.
Without this testing, software would likely suffer from issues such as poor performance under stress, inconsistencies across different operating systems, and low usability.
The test determines if the software meets performance parameters under predicted workloads. Applications released to the market with low performance metrics due to non-existent or inadequate testing will likely gain a bad reputation and fail to meet sales objectives.
Moreover, critical applications such as space launch programs and medical equipment must undergo performance testing to ensure full functionality.
Load Testing: Checks the application's ability to perform under predictable user loads to identify bottlenecks before the application is deployed.
Stress Testing: Involves testing the application under extreme loads to assess how the system handles traffic and data processing. The goal is to identify the breaking point of the application.
Spike Testing: Tests the software's reaction to a sudden spike in user-generated load.
Endurance Testing: Ensures that the software can handle the expected load over a long period of time.
Volume Testing: Large amounts of data are inserted into the database, and the overall system behavior is monitored. The goal is to check performance at different database volume levels.
Scalability Testing: Determines the effectiveness of the software under increasing loads to accommodate a growing number of users. This helps plan capacity improvements for the system.
Most performance problems revolve around speed, response time, load time, and poor scalability. Speed is one of the most crucial attributes; a slow application will lose potential users. Performance testing ensures that an application runs fast enough to maintain a user's attention and interest. In the following list, we examine how speed is a constant concern.
High Load Time: Load time is typically the period an application takes to start; it should generally be as short as possible. While some applications cannot be started in less than a minute, the loading time should ideally be under a few seconds, if possible.
Inadequate Response Time: This refers to the time taken between user input and the application's output for that input. It should generally be very fast; if the wait is too long, the user loses interest.
Poor Scalability: A software product suffers from poor scalability when it does not support the expected number of users or when it does not accommodate a satisfactory range of users.
Bottleneck: These are obstructions in a system that degrade overall performance. They occur when code or hardware errors cause a decrease in throughput under certain loads. The key to locating a bottleneck is finding the section of code causing the slowdown and fixing it. Bottlenecks are commonly resolved by fixing the lines of code or adding hardware. Some common bottlenecks include:
+
The methodologies for performance testing can vary, but the goal remains consistent.
Generic flowchart of performance testing:
Identify the Test Environment:
+Understand the physical testing environment, production, and available testing tools. Understand details of the hardware, software, and network configurations used during testing before starting it. This process promotes greater efficiency.
Identify Performance Acceptance Criteria:
+This includes throughput objectives and constraints, response times, and resource allocation. It is also necessary to identify project success criteria beyond these objectives and constraints. Testers should also be empowered to define performance criteria and goals since project specifications usually will not include a wide enough variety of benchmarks for performance. If possible, finding a similar application for comparison purposes can help in defining performance goals.
Planning and Design of Performance Tests:
+Determine how usability will vary among end users to identify key test scenarios for all possible use cases. It is necessary to simulate a variety of end users, plan data for performance testing, and limit the metrics to be collected.
Test Environment Setup:
+Prepare the testing environment before its execution; also, organize tools and other resources.
Implement Test Design:
+Create performance tests according to the original design.
Execute the Tests
Analyze, Tune, and Retest:
+Consolidate, analyze, and share test results. Then, tune specifically and retest to observe improvements or declines in performance. Since improvements generally decrease with each test, stop when the bottleneck is caused by the CPU. Then consider the option of increasing the CPU power.
CPU Usage: The amount of time a processor spends executing active threads.
Memory Usage: Physical space available in memory for processes on the computer.
Disk Time: The period during which the disk is occupied to execute a read or write request.
Private Bytes: Number of bytes a process has allocated that cannot be shared among other processes. These are used to measure memory leaks and memory usage.
Dedicated Memory: Amount of virtual memory used.
Memory Pages per Second: Number of pages written or read from the disk to resolve serious page faults. Serious faults are identified when code not currently under test group receives a call from somewhere else and is fetched from a disk.
Page Faults per Second: The overall rate at which faults are processed by the processor. Again, these occur when a process requires code from outside the group under test.
CPU Interrupts per Second: Average number of hardware interrupts a processor is receiving and processing every second.
Disk Queue Length: Average number of requests for read and writes in the queue for the selected disk during a sampling time.
Network Output Queue Length: Queue length of output packets. Anything above 2 means a delay, and the bottleneck needs to be resolved.
Total Bytes on the Network per Second: Rate at which bytes are sent and received on the interface, including framing characters.
Response Time: Time between user request and receipt of the first character of the response.
Throughput: Rate at which a computer or network receives requests per second.
Connection Pool Count: Number of user requests handled by a connection pool. The more requests handled by connections in the pool, the better the performance.
Maximum Active Sessions;
Hit Rates: Involves the number of SQL statements processed by data in the cache instead of expensive I/O operations. This is a good starting point for bottleneck solutions.
Hits per Second: The number of successful hits a web server receives during each second of a load test;
Undo Segment: Amount of data that can be rolled back at any given time;
Database Locks: Locking of tables and databases needs to be monitored and adjusted carefully;
Longest Waits: Monitored to determine which wait times can be reduced when dealing with how quickly data is fetched into memory;
Thread Count: The health of an application can be measured by the number of threads that are active and running;
Waste Collection: Refers to the return of unused memory back to the system. Waste collection needs to be monitored for efficiency.
Stress testing is a type of testing that assesses the stability and reliability of an application. Its objective is to measure the robustness and error-handling capability of a software under extreme load conditions, ensuring that the application does not crash under stress situations. Here, testing goes beyond usual operational points.
In software engineering, stress testing is also known as resistance testing or overwhelming the system for a short period to validate its working capacity.
The most prominent use of this technique is to determine the threshold beyond which software or a system breaks, also checking if the system demonstrates proper error handling under extreme conditions.
Consider the real-life scenarios below to understand the need for Stress Testing:
During an event, an online shopping site may experience a sudden spike in traffic or when it advertises a promotion.
When a blog is mentioned in a famous newspaper, it observes a sudden increase in accesses.
It is imperative that stress testing be applied to accommodate these abnormal traffic situations; failure to accommodate can result in loss of revenue and reputation.
This technique is also extremely important for the following reasons:
Verify if the system functions under abnormal conditions.
Display an appropriate error message when the system is under stress.
System failure under extreme conditions can result in significant lost profits.
It is better to be prepared for abnormal traffic situations.
Analyzing the system's behavior after a failure, for successful recovery, the system must display an error message consistent with extreme usage conditions.
To conduct stress testing, sometimes enormous sets of data can be used and lost during testing. Testers must not lose this confidential data during the process.
The primary purpose is to ensure that the system recovers after a failure, which is called recoverability.
In this mode, the test is performed through all the server's clients.
The stress server's function is to distribute a set of stress tests to all clients and track each one's status. After the client contacts the server, it will add the client's name and send test data.
Meanwhile, client machines send signals indicating they are connected to the server. If the server does not receive any signals from the machines, it needs to be checked for further debugging processes.
As shown in the image, the test can be specific to certain users or general across all connected clients.
Nightly integrations are the best option for executing these scenarios. Large server groups need a more efficient method to determine which computers had stress failures that need verification.
It applies the test to one or more transactions between two or more applications. It is used for system tuning and optimization. It is important to note that a transaction is significantly more complex than a request.
It is integrated stress testing that can be applied to multiple systems running on the same server, used to locate defects where one application generates data blocking in another.
Stress Testing Planning: Collect data, analyze the system, and define objectives.
Automation Script Creation: In this phase, automation scripts are created, and test data is generated for stress scenario.
Script Execution and Result Storage:
Result Analysis:
Adjustments and Optimization: In this stage, final adjustments are made in the system; settings are changed, and code is optimized to achieve the desired benchmark.
Finally, reapply the adjusted cycle to verify if it has produced the desired results. For example, it is not uncommon to apply 3 or 4 cycles of stress testing to achieve the desired performance.
Security testing is a type of software testing that discovers vulnerabilities, threats, and risks in a software application, preventing intruder attacks.
The purpose of security testing is to identify all possible gaps and weaknesses in the system that may result in the loss of information, profits, and reputation in the hands of employees or outsiders of the organization.
Once identified, vulnerabilities are verified so that the system continues to function and cannot be exploited.
Vulnerability Scanning: Done through automated software to explore the system for vulnerability signatures.
Security Scanning: Involves identifying weaknesses in the network and system, providing solutions to reduce these risks. This scan can be applied manually or automatically.
Penetration Testing: Simulates malicious hacker attacks. Here, the analysis of a particular system is involved to check potential vulnerabilities to external attacks.
Risk Assessment: This technique involves analyzing security risks observed within the organization. Risks are then classified as low, medium, and high. This test recommends controls and measures to reduce risks.
Security Audit: Internal inspection of applications and Operating Systems for security flaws. An audit can also be done line by line in the code.
Ethical Hacking: The process of hacking an organization without malicious intent but rather to expose and fix system security risks.
Posture Assessment: This combines security scanning, ethical hacking, and risk assessment to demonstrate the overall security posture of an organization.
Tiger Box: This hacking method is usually done on a laptop that has a collection of operating systems and hacking tools. This test helps penetration testers conduct vulnerability assessments and attacks.
Black Box: The tester is authorized to perform tests on everything about network topology and technology.
Grey Box: Partial information is provided to the tester about the system; it is a hybrid.
Accessibility testing is defined as a type of testing applied to ensure that the current application is usable by people with conditions such as deafness, color blindness, old age, etc.
It is a subset of Usability Testing.
These people use assistants that help them operate a software product, such as:
Speech Recognition: Converts spoken language into text, which serves as input for the computer.
Screen Reader Software: Used to read the text displayed on the screen.
Screen Magnification Software: Used to enlarge the screen, making reading more comfortable for users with visual impairments.
Adapted Keyboard: Designed for users with motor problems, making it easier for them to use.
Meeting the Market Demand:
+With a significant number of users with limiting conditions, testing is applied to solve any accessibility issues, being a best practice to include this technique as a normal part of the development cycle.
Compliance with Relevant Legislation:
+Government agencies worldwide have produced legislation to determine that IT products are accessible to as many users as possible. This makes accessibility testing a fundamental part of the process, also due to legal requirements.
Avoiding Potential Lawsuits:
+In the past, Fortune 500 companies were sued for their products not being accessible to the market. It remains in the best interest of the company for its products to be accessible to avoid future lawsuits.
Accessibility testing can be manual or automated and can be challenging for testers due to their unfamiliarity with possible impairments. It is advantageous to work closely with people with disabilities so that they can expose specific needs, promoting a better understanding of their challenges.
We have different ways to test, depending on each disability, such as:
Here, Screen Reader Software is used, which narrates the content displayed to the user, such as text, links, buttons, images, videos, etc.
In summary, when starting one of these programs and accessing a website, it will narrate all the content, making navigation possible for visually impaired people.
A poorly developed website can conflict with these programs, preventing correct and complete narration, and therefore generating inaccessibility. For example, due to structural errors, the software does not announce a link as such, describing it only as text and making it impossible for the user to recognize it.
It is important to note that in this category, there are also other types of visual impairments, such as low vision or color blindness.
In color blindness, the person is not blind but cannot see specific colors. Red and blue are common cases, making access complex if the website is based on one of these colors.
The design of a website should take this into account. For example, a button in red might be more accessible if it has a black border.
In low vision, the user is not completely blind but has difficulty seeing. The best thing to do is to avoid very small texts, structure the website so that the user can zoom in without breaking the layout, promoting a better experience.
A very important point is to consider access to the site without using the mouse.
A user should be able to have complete access to links, buttons, pop-ups, drop-downs, etc., entirely from keyboard shortcuts.
The focus must be entirely visible so that when pressing tab, the user can see where the control moves, with visible focus, we make access possible for individuals with low vision or color blindness, allowing them to identify the flow on the website and promoting ease of use.
Finally, it is important to observe users with hearing impairments, such as deafness or hearing loss.
Here, the user can access the site and see its content, but encounters problems with audio and video, making alt text imperative. Alternate text is a video supplement. In other words, if the site features a video tutorial for purchasing tickets, it should also offer an alternative in text form, allowing the user to understand the video content.
Compatibility is the ability to coexist. In the context of software, compatibility testing verifies if your software can run on different hardware configurations, operating systems, applications, network environments, or mobile devices.
Hardware: Checks if the software is compatible with different hardware configurations.
Operating System: Ensures the software functions properly on different operating systems like Windows, Unix, Mac OS, etc.
Software: Validates if the application is compatible with other software. For example, MS Word should be compatible with other software like MS Outlook, MS Excel, etc.
Network: Evaluates the system's performance on a network with variable parameters such as bandwidth, operating speed, capacity, etc. It also validates the application on different networks with all the aforementioned parameters.
Browser: Checks the compatibility of the website with different browsers like Firefox, Chrome, IE, etc.
Devices: Verifies compatibility with mobile platforms like Android, iOS, etc.
Software Versions: Checks if the software application is compatible across different versions. For example, validating if Microsoft Word is compatible with Windows 7, Windows 7 SP1, Windows 7 SP2, etc.
+There are two types of version checking in Compatibility Testing:
+
Backward Compatibility Testing: Technique that validates the software's behavior and compatibility with its previous versions of hardware or software. This modality is quite predictable since all changes between versions are known.
Forward Compatibility Testing: A process that verifies the application's behavior and compatibility with new versions of hardware or software. It is a more complex process to predict since changes in new versions are unknown.
Virtual Desktops - OS Compatibility: Applied to execute the application on multiple operating systems as virtual machines, various systems can be connected, and the results can be compared.
Initial Phase: Define the group of environments or platforms that the application should work on.
Tester Knowledge: The tester must have sufficient knowledge of the platforms/software/hardware to understand the expected behavior of the application under different configurations.
Environment Setup: Configure the environment for testing with different platforms/devices/networks to check if the application functions correctly.
Bug Reporting: Report bugs, fix defects, and retest to confirm the applied corrections.
A project is a temporary undertaking with the goal of creating a unique product, service, or outcome.
The project is temporary because it has defined start and end dates, and it is unique because it involves a set of operations designed to achieve the objective.
Project management is the discipline of planning, organizing, motivating, and controlling resources to achieve the project's objectives while keeping in mind the scope, time, quality, and costs.
This facilitates the workflow of the team of collaborators.
A Test Plan is a detailed document that describes the testing strategy, objectives, schedule, estimates, deliverables, and resources required to perform testing on a software product.
The plan helps determine the effort needed to validate the quality of the application under test. This plan serves as a blueprint for conducting testing activities as a defined process, which is closely monitored and controlled by the Test Manager.
According to the ISTQB definition:
"The Test Plan is a document that describes the scope, approach, resources, and schedule of planned test activities."
+
The benefits of the Test Plan document are diverse:
It aids people outside the testing team, such as developers, business managers, and clients, in understanding the details of testing.
The plan guides reasoning and acts as a set of rules to be followed.
Important aspects such as test estimation, test scope, strategies, etc., are documented in the Plan so that they can be reviewed by the Management Team and reused for other projects.
How can you test a product without any information about it? You can't. You need a deep understanding of the product before testing it.
The product under test is the Guru99 Banking Site. Research customers, end-users, and their needs and expectations from the application.
Who will use the site?
What is its function?
How will it work?
What software/hardware does the product use?
The idea is to explore the product and review its documentation, which will help understand all the project's features and usability. If there is any lack of understanding, interviews can be conducted with customers, developers, and designers for further information.
The Test Strategy is a critical step in creating a Test Plan within software testing. The strategy is a high-level document, typically developed by the Test Manager. The document defines:
The test project's objectives and the means to achieve them.
Before starting any testing activity, the scope must be defined.
Components of the system to be tested (hardware, software, middleware, etc.) are defined according to the scope.
Components of the system that will not be tested must also be clearly defined as not within the scope.
Defining the scope of your test project is essential for all stakeholders, as it provides everyone with reliable and accurate information about the testing to be carried out. All project members will have a clear understanding of what will be tested and what will not.
A test type is a standard procedure that provides an expected outcome for tests.
Each type of testing is designed to identify a specific type of bug in the product. However, all types share the common goal of early defect identification before the client release.
Commonly used types include:
Unit Testing: Verifies the smallest verifiable software parts in the application.
API Testing: Validates the API created for the application.
Integration Testing: Individual modules are combined and tested as a group.
System Testing: Conducted on a complete and integrated system to evaluate compliance with requirements.
Installation/Uninstallation Testing: Focuses on what customers need to do to successfully install/uninstall, configure/remove new software.
Agile Testing: Evaluates the system according to agile methodology.
There are a myriad of test types for the product, and the Test Manager should define the appropriate prioritization based on the application's functions and within the defined budget.
Risks are future and uncertain events with the probability of occurrence and the potential for loss. When the risk actually occurs, it becomes an "issue."
Examples of documentation risks include:
Team member lacks required skills: Plan training sessions.
The schedule is tight, making it difficult to complete requirements on time: Determine test priority for each activity.
Test Manager lacks adequate management skills: Plan training sessions for leadership.
A lack of cooperation negatively affects team productivity: Encourage each member in their tasks and inspire them to greater efforts.
Incorrect budget estimate and additional costs: Establish scope before starting work, pay due attention to planning, and continuously measure progress.
In test logic, the Manager must answer the following questions:
Who will perform the test?
When will the test take place?
You may not know the names of each tester, but the type of tester can be defined.
To select the right member for a specific task, you must consider whether their skills qualify them for the task and estimate the available budget. Incorrect selection can cause delays or project failure.
Possessing the following skills is most ideal for testing:
Ability to understand from a customer's perspective.
Strong desire for quality.
Attention to detail.
Good cooperation.
In your project, the tester will take the reins of execution. Based on the budget, you can select outsourcing.
When will the test occur?
Test activities should be associated with development activities and should start when all necessary items exist.
This involves the overall goal and achievement of the best execution. The goal of testing is to find as many defects as possible, ensuring that the software is bug-free before release.
To set objectives, you need to:
List all features (functionality, performance, GUI, etc.) that may require testing.
Define the target or objective of the test based on the above features.
Specify critical suspension criteria for a test. If these criteria are met during testing, the active test cycle will be suspended until the criteria are resolved.
Example: If the team reports that 40% of cases have failed, you must suspend testing until the development team fixes all cases.
Exit criteria specify the guidelines that denote success in a testing phase. Exit criteria are the target results of tests required before proceeding to the next development phase.
+E.g., 95% of all critical test cases must pass.
Some methods for defining exit criteria consist of specifying execution and success rates.
Execution Rate: It is the ratio of the number of executed test cases to the total number of cases.
Success Rate: The ratio of tests that have passed to the total number of executed test cases.
These data can be collected in test metric documents.
The Execution Rate must necessarily be 100%, unless a clear reason is provided.
The Success Rate depends on the project's scope, but it is ideal for it to be as high as possible.
Resource planning is a detailed summary of all types of resources required to complete a task or project. Resources can be human, equipment, and materials needed to finish a project.
Resource planning is an important factor in test planning as it helps determine the number of resources to be employed in the project. Therefore, the Test Manager can accurately develop the schedule and estimates for the project.
Human Resources:
+
Test Manager:
+1. Manages the entire project.
+2. Defines guidelines.
+3. Acquires the necessary resources.
+4. Identifies and describes appropriate automation techniques/tools/architecture.
It consists of the software and hardware setup in which the test team develops test cases. It is characterized by a real business and user environment, as well as physical environments such as servers and front-end execution.
Assuming cooperation between the development team and the test team, ask the developers for all the necessary information to understand the application under test clearly.
What is the maximum number of actively connected users the website can handle simultaneously?
What are the hardware/software requirements for website installation?
Does the user need any specific configurations to browse the website?
Suppose that the entire project is subdivided into smaller tasks and added to the estimate as follows:
Creation of Test Specifications:
+
Developed by the Test Designer.
170 hours of work.
Test Execution:
+
Tester, Test Administrator.
80 hours of work.
Test Report:
+
Tester.
10 hours of work.
Test Delivery:
+
20 hours of work.
Total: 280 Hours of Work.
This way, you can create a schedule to complete all the tasks.
Creating schedules is a common term in project management. By creating a solid schedule in Test Planning, the Manager can use it as a tool to monitor progress and control additional costs.
To create a project schedule, the Test Manager needs various information, such as:
Employee and Project Deadlines: Workdays, project deadlines, and available resources are factors that affect the schedule.
Project Estimation: Based on the estimation, the Manager will know how much time will be spent to complete the project, enabling the creation of an appropriate schedule.
Project Risks: Understanding the risks helps the Manager add enough extra time to the schedule to deal with risks.
Test cases that must be executed, or the consequences may be worse after the product's release. These are critical test cases, where the chances of a new feature breaking an existing one are more likely.
Priority 2:
Test cases that can be executed if there is time. These are not as critical but can be performed as a best practice to double-check before release.
Priority 3:
Test cases that are not important enough to be tested before the current release. These can be tested later, immediately after the current version of the software is released, again as a best practice. However, there is no direct dependency on them.
Priority 4:
Test cases that are never important since their impact is negligible.
In the prioritization scheme, the main guideline is to ensure that low-priority cases should not cause severe impacts on the software. This prioritization should have several objectives, such as:
Based on functionality that has already been communicated to users and is critical from a business perspective.
Assess the probability of faults by checking the fault detection rate of a test category. This helps understand if this category is critical or not.
Increase code coverage of the system under test more quickly using previously used coverage criteria.
Increase the detection rate of critical faults in a test category by locating similar faults that occurred earlier in the testing process.
Increase the probability of faults being revealed due to specific changes in the code earlier in the Regression Testing process.
Here, test cases are prioritized based on how useful they will be for subsequent versions of the product. This does not require any knowledge of modified versions, so general prioritization can be applied immediately after the release of a version outside of peak hours. Due to this, the cost of applying this prioritization category is amortized during subsequent releases.
Version-Specific Test Case Prioritization:
In this mode, we prioritize the cases so that they will be useful according to each version of the product. This requires knowledge of all the changes made to the product. It is applied before regression testing in the modified version.
# What Are the Different Techniques for Prioritization?
We can prioritize test cases using the following techniques:
Focuses on code coverage by tests according to the following techniques:
Total Statement Coverage:
Here, the total number of statements covered by a test case is used as a factor to prioritize the tests. For example, a test covering 5 statements will receive priority over one covering only 2.
+
Additional Statement Coverage:
This technique involves iteratively selecting a test case with the highest statement coverage and then selecting a case that covers what the previous one missed. The process is repeated until everything is covered.
Total Branch Coverage:
Here, branches refer to the total possibilities of output in a condition, and the highest coverage of these is the determining factor.
Additional Branch Coverage:
Similar to additional statement coverage, here, the technique picks the test with the highest branch coverage and iteratively selects the next ones according to those not covered by the previous one.
In this technique, prioritization is based on various factors that determine business rules. These factors are documented in the acceptance criteria. Test cases are designed considering the priority assigned by the customer to a rule, its complexity, and volatility.
The factors used are:
Priority Indicated by the Customer: It is a measure of the importance of business rules to a customer from a business perspective.
Business Rule Volatility: Indicates how many times the business rule has changed.
Implementation Complexity: Indicates the effort or time required to implement a business rule.
Error-Prone Nature: Indicates how error-prone a business rule was in previous versions of the software.
In this technique, prioritization is done based on the history of test cases, i.e., the results of previous executions are checked.
It is used to determine the possible chances of failure in the tests, and those in which failure is more likely receive priority. History verification is used to select which test cases should be considered for retesting in the current cycle.
It is a process followed for a software project within a company. It consists of a detailed plan that describes how to develop, maintain, change, or enhance specific parts of the software. The cycle defines a methodology to improve software quality and the overall development process.
Analysis of business rules is one of the most fundamental stages in SDLC. It is performed by senior team members with inputs from clients, sales departments, market research, and industry experts. This information is used to plan the project's basic approach and conduct product feasibility studies in economic, operational, and technical areas.
Planning for quality assurance requirements and identifying project-associated risks is also done in the planning stage. The result of feasibility studies is to define the various technical approaches that can be followed to successfully implement the project while assuming minimal risks.
Once requirements analysis is complete, the next step is to clearly define and document all business rules and acceptance criteria, obtaining approval from clients and market analysts. This is done through a Software Requirement Specification (SRS) that consists of the design of all product requirements and their development throughout the project's life cycle.
The SRS serves as a reference for product architects to develop the best possible architecture. Based on the requirements specified in the SRS, typically more than one design approach is proposed and documented in a Design Document Specification (DDS).
This DDS is reviewed by all major stakeholders, and based on various parameters such as risk analysis, product robustness, design modularity, budget, and time constraints, the best approach for the product is chosen.
A clear design approach defines all the architecture modules of the product along with their communication and data flow representation with external modules (if any). The internal design of all modules of the proposed architecture should be clearly defined with maximum detail in the DDS.
Here, the actual development begins, and the product is built. The programming code is generated according to the DDS in this stage. If the design is applied in a detailed and organized manner, the code generation can be completed without major difficulties.
Developers should be familiar with the code guidelines defined by their organization, as well as the relevant tools. The choice of programming language to be used is determined according to the software to be developed.
This stage is generally a subset of all stages in modern SDLC models. However, this stage specifically focuses on product testing, where defects are located, reported, cataloged, corrected, and validated until the product meets the highest quality standards.
Once the product has been tested and is ready to be implemented, it is formally released to the market. Sometimes, product implementation occurs in stages, according to the organization's business strategy. The product may be first released in a limited segment and tested in the actual business environment (User Acceptance Testing - UAT).
Then, based on feedback, the product may be released as is or with improvements suggested by the target market. Once released to the market, its maintenance is focused on the existing user base.
Several defined and architected models are followed during the development process. These models are also called Software Development Process Models. Each process model follows a unique set of steps to ensure success in development processes.
Quality Assurance (QA) plays a fundamental role in the process to be implemented in the development cycle.
Its primary function is to ensure that the software meets business rules, is free of bugs, and functions perfectly under different circumstances.
For the current market reality, where a product will be available in various modes, it is critical that it is developed without defects. This is where QA comes in.
QA in IT is integrated into all stages of development and is used even after the release stage.
QA experts create and implement various strategies for software quality improvement, applying various types of tests to ensure proper functionality. This stage is called Quality Control (QC).
QA Analyst: Close to the business analyst, they collect all project information, assess risks and weaknesses, and create documentation to describe future development aspects that QA Engineers need to pay attention to.
QA Lead: The team's leadership is the person who controls the entire team of experts. In addition, the lead manages tests, creates test plans, processes information received from analysts, observes all deadlines to ensure timely testing.
QA Engineer: This specialist applies tests and does everything to improve the overall quality of the software, ensuring that it complies with business rules.
The scope of QA tasks should be quite broad. The Quality Assurance team once again proves its importance in SDLC.
Test Planning: Analysts plan the testing process, with their goals to achieve and which approaches to use.
Initial Testing: QA engineers conduct initial testing to identify bugs during the first development phase to expedite it.
Test Execution: QA engineers apply manual or automated tests of different types according to the software's peculiarities.
Defect Analysis: It is necessary to analyze all defects and identify the reason for their occurrence.
Reporting: Experts use bug tracking systems and create reports for developers with descriptions of the bugs and defects to be fixed.
Collaboration: The QA team collaborates with business analysts, project managers, developers, and clients to achieve the highest possible quality for a software product.
Test Summary and Report Creation: When software is tested, QA engineers need to create reports summarizing the quality level of the software.
Quality Assurance in the software development life cycle plays a crucial role in all stages, such as:
Requirements Analysis: In IT, the QA team collaborates with business analysts to develop a feasibility study of business rules, analyze potential risks, create a test plan, and build a quality assurance approach (each project requires an individual approach due to its specificities), including which tests to use, etc.
Design: A review of the design is required, checking its stability, ensuring that its architecture meets all requirements. In addition, QA experts produce data flow diagrams in conjunction with UI/UX designers and document them. Finally, QA engineers test the design after completion to mimic end-user behavior.
Development: QA in software development can be applied once the software is developed, or according to the Test-Driven Development (TDD) approach, which defines testing during the development process after each iteration.
Post-Launch QA: Once launched, developers must maintain the product. The QA team then creates user guides and product manuals for delivery to end-users. They also create test documentation to ensure that all bugs have been identified and corrected.
Saves Resources and Preserves Reputation: The latter being one of the most important. For example, if you develop trading software and have not tested it correctly, users would lose money, and even compensating for their losses would be impossible to save the reputation of your product. Therefore, quality assurance helps detect bugs before users encounter them.
Prevents Emergencies: Imagine that you commission the development of internal use software, and your employees will use it for better communication with clients. Even a small bug can lead to severe failures such as data loss and communication breakdowns. Recovering this information without additional expenses will be more complex.
Increases Customer Loyalty: Bug-free software means that customers do not face problems when using your application. Furthermore, if you respond to customer complaints and rectify issues promptly, your clientele will see that you respect them and aspire to the highest levels of quality. As a result, your customer base is retained, leading to additional profit.
Impacts Employee Productivity: Employees can work better and more efficiently when obstacles such as software bugs do not get in their way. Employees do not waste time trying to figure out the reasons behind software failures and other challenges to continue their work.
Makes Software Safer: Finally, quality assurance contributes to a more secure application by eliminating vulnerabilities and defects, preventing malicious attacks. The cost of QA services is incomparable to potential financial losses that a business can suffer due to a lack of reliable protection.
The Agile methodology consists of practices that promote continuous development and testing iteration throughout the Software Development Life Cycle (SDLC) in a project. In the Agile methodology for software testing, both development and testing occur concurrently, unlike the waterfall model.
This methodology is one of the simplest and most efficient approaches to translate a business's needs into software solutions. Agile is a term used to describe development approaches that emphasize planning, learning, improvements, team collaboration, evolutionary development, and continuous early deliveries. This encourages flexible responses to change.
The four core values of the Agile methodology are:
Individual and team interactions over processes and tools.
Working software over comprehensive documentation.
Customer collaboration over contract negotiation.
Responding to change over following a plan.
Agile Methodology vs. Waterfall Model
Agile Methodology
Agile methodologies propose incremental and iterative approaches to software design.
The Agile process in software engineering is divided into individual models that designers work on.
The customer has frequent opportunities from the beginning to see the product and make decisions or changes to the project.
It is considered less structured compared to the waterfall model.
Small projects can be implemented quickly, while large projects may have difficulty estimating development time.
Errors can be corrected during the project.
The development process is iterative, and the project is executed in short iterations (2-4 weeks).
Documentation has lower priority than software development.
Each iteration has its own testing phase. This allows the implementation of regression tests whenever a new feature or logic is introduced.
In Agile testing, when an iteration ends, shippable product features are delivered to the customer. New features are usable right after delivery, which is useful when there is good customer contact.
Developers and testers work together.
At the end of each sprint, user acceptance is applied.
Close communication with developers is required to jointly analyze requirements and planning.
Waterfall Model
Software development flows sequentially from beginning to end.
The design process is not divided into individual models.
The customer can only see the product at the end of the project.
The waterfall model is more secure because it is plan-driven.
All types of projects can be estimated and completed.
Only at the end is the entire product tested. If errors are found or changes are made, the project starts over.
The development process occurs in stages, and each stage is much larger than an iteration. Each stage ends with a detailed description of the next.
Documentation is of high priority and can be used for training employees and improving the software with another team.
Testing only begins after the development phase because separate parts are not fully functional.
All developed features are delivered at once after a long implementation phase.
Testers work separately from developers.
User acceptance is applied at the end of the project.
Developers are not involved in business rule and planning processes. There are typically delays between testing and coding.
In software testing, Scrum is a methodology used for building complex applications. It provides straightforward solutions for executing intricate tasks. Scrum assists the development team in focusing on all aspects of software product development, such as quality, performance, usability, etc. It generates transparency, inspection, and adaptation during the Software Development Life Cycle (SDLC) to avoid complexity.
Scrum testing is performed to validate business rules and involves checking non-functional parameters. There is no active role for testers in the process, so it is usually developed by developers using Unit Testing. Dedicated testing teams may be required depending on the nature and complexity of the project.
Scrum has short schedules for release cycles with adjustable scopes known as sprints. Each release may have multiple sprints, and each Scrum project may have multiple release cycles.
A repetitive sequence of meetings, events, and milestones.
The practice of testing and implementing new business rules, known as user stories, to ensure that parts of the work are released shortly after each sprint.
User Stories: Short explanations of system features under test. An example for an insurance agency is, "Premium can be paid using the online system."
Product Backlog: A collection of user stories captured for a Scrum project. The Product Owner prepares and maintains this backlog. It is prioritized by the Product Owner, and anyone can add items with their approval.
Release Backlog: A release is a time span in which a number of iterations are completed. The Product Owner coordinates with the Scrum Master to decide which user stories should be prioritized in a release. User stories in the release backlog are prioritized for completion in a release.
Sprints: A defined time frame for completing user stories, decided by the Product Owner and the development team, typically 2-4 weeks.
Sprint Backlog: A group of user stories to be completed in a sprint. During the sprint backlog, work is never assigned, and the team self-assigns tasks. It is owned and managed by the team, while remaining estimated work is updated daily. It is the list of tasks to be developed in a sprint.
Blockers List: A list of blocks and decisions not yet made, owned by the Scrum Master and updated daily.
Burndown Chart: Represents the overall progress between work in progress and work completed throughout the entire process. It graphically shows unfinished user stories and features.
Sprint Planning: A sprint begins with the team importing user stories from the Release Backlog into the Sprint Backlog. Testers estimate the effort to validate the various user stories in the Sprint Backlog.
Daily Scrum: Facilitated by the Scrum Master, it lasts about 15 minutes. During the Daily Scrum, team members discuss the work completed the previous day, planned work for the next day, and challenges encountered during a sprint. The team's progress is tracked during the daily meeting.
Sprint Review/Retrospective: Also facilitated by the Scrum Master, it lasts 2-4 hours and discusses what the team developed in the last sprint and what lessons were learned.
There is no active role for testers in the Scrum process.
Usually, tests are developed by a developer with Unit Testing. The Product Owner is often involved in the testing process in each sprint. Some Scrum projects have dedicated testing teams depending on the nature and complexity of the project.
Here, the tester should choose a user story from the product backlog for testing.
As a tester, they must decide how many hours (Effort Estimation) it will take to complete testing for each selected user story.
They should know the sprint's objectives.
Contribute to the prioritization process.
Sprints:
Support developers in unit testing.
With user story tests complete, the testing execution is done in a lab where the developer and tester work together. Defects are logged in the Defect Management tool, which is checked daily. Defects can be reviewed and discussed during a Scrum meeting. Any bugs are retested as soon as they are fixed and implemented for testing.
As a tester, attend all daily meetings to provide input.
Bring any backlog items not completed in the current sprint for inclusion in the next sprint.
The tester is responsible for developing automation scripts. They schedule automated tests with the Continuous Integration (CI) system. Test automation is given importance due to short delivery times. Test automation can be achieved using various paid or open-source tools available. This proves its efficiency in ensuring that everything that needs to be tested is covered. Satisfactory test coverage can be achieved with close communication with the team.
Review automation results in the CI and send reports to stakeholders.
Execute non-functional tests for approved user stories.
Coordinate with the client and Product Owner to define acceptance criteria for Acceptance Testing.
At the end of the sprint, the tester may also perform User Acceptance Testing (UAT) in some cases and confirm the completion of testing for the current sprint.
Sprint Retrospective:
As a tester, establish what went wrong and what was successful in the current sprint.
Scrum testing metrics provide transparency and visibility for stakeholders about the project. The reported metrics allow a team to analyze their progress and plan future strategies for product improvement.
There are two metrics commonly used for reporting:
Daily, the Scrum Master records the estimated remaining work for the current sprint, which is nothing but the Burn Down, updated daily.
This chart provides a quick overall view of project progress, showing information such as the total volume of work in the project that needs to be completed, work completed in each sprint, and more.
Kanban is a popular framework used to implement Agile and DevOps software development, requiring real-time communication of capacity and work transparency.
Work items are visually represented on a Kanban board, allowing team members to see the state of each project sector at any given time.
It is an Agile project management tool that aids in clear project visualization, maximizing efficiency (or flow).
This aids both Agile and DevOps teams in their day-to-day work. Kanban boards use cards, columns, and continuous improvement to help service and technology teams engage in the right amount of work.
One of the first noticeable elements on the board is visual cards (stickers, tickets, etc.). Kanban teams write all their projects and work items on cards, usually one per card. Once on the board, these visual signals help team members and stakeholders quickly understand what the team is focusing on.
The maximum number of cards that can be in a column at any time. A column with a WIP limit of three cannot contain more than three cards.
When the column reaches its maximum, the team must focus on these cards to move them forward, making room for new cards to enter this stage of the workflow.
These WIP limits are critical for exposing production bottlenecks and maximizing flow. WIP limits provide advance warnings that you have taken on too much work.
Kanban teams usually have a backlog on their boards. This is where customers and team partners enter project ideas that the team can take on when ready. The commitment point is when an idea is taken on by the team, and work begins on the project.
For most teams, the delivery point is when the product or service is in the hands of the customer. The team's goal is to take the cards from commitment to delivery as quickly as possible. The time between these two points can be called Lead Time, and Kanban teams continuously strive to improve and minimize this time.
Jim Benson says that Kanban has only two rules:
"Limit WIP and visualize your work. If you start with just these two rules and apply them to your work, your Kanban board will be quite different from the one described above. And that's okay!"
The simplest Kanban boards are physical boards divided into columns. Teams mark the board with Post-its, which move through the workflow, showing progress.
An advantage of physical boards is that "it's always on." You can't open a new tab on a huge whiteboard right next to your desk.
It is simple and easy to set up, but sometimes the physical screen is not ideal for remote teams.
While the Kanban system gained popularity with software and engineering teams, it has suffered.
Digital boards allow teams that do not share physical spaces to use Kanban boards remotely and asynchronously.
The Trello platform provides a quick and easy way to create virtual Kanban boards.
The advantages of a virtual Kanban board include setup speed, ease of sharing, and the asynchronous nature of the countless conversations and comments throughout the project. No matter where or when project members check the board, they will see the most up-to-date status. In addition, you can use a Trello built-in workflow for your personal tasks.
The differences between Kanban and Scrum are quite subtle. In most interpretations, Scrum teams use a Kanban board but with Scrum processes, artifacts, and roles within it. However, there are key differences:
Scrum sprints have start and end dates, while Kanban is a continuous process.
Team roles are clearly defined in Scrum (Product Owner, developers, Scrum Master), while Kanban has no formal roles. Both teams are well-organized.
A Kanban board is used throughout the project lifecycle, while a Scrum board is cleared and recycled after each sprint.
Scrum boards have a fixed number of tasks and set delivery dates.
Kanban boards are more flexible regarding tasks and time limits. Tasks can be reprioritized, reassigned, or updated as needed.
Both Kanban and Scrum are popular Agile frameworks among software developers.
Kanban is a "start with what you know" method. This means you don't have to figure out what to do next to start Kanban. The method assumes three things:
You understand the current processes as they are applied and respect the current roles, responsibilities, and hierarchies.
You agree to pursue continuous improvement through evolutionary change.
You encourage acts of leadership at all levels, from team members to senior managers.
It is a sequential framework that divides software development into predefined phases. Each one must be completed before the next one can begin, with no overlap between phases.
Each stage is structured to carry out a specific activity during the SDLC phase.
Business Requirement Gathering Phase: Gathering as much information as possible about the details and specifications of the software desired by the client.
Design Phase: Planning the programming language to be used, the database, etc. It should fit the project, as well as high-level functions and architecture.
Construction Phase: After the Design, we proceed to actually build the software code.
Testing Phase: Afterward, we test the software to verify that it has been created according to the specifications provided by the client.
Implementation Phase: It implements the application in the designated environment.
Maintenance Phase: Once the system is ready for use, it may be necessary to change the code later depending on user requests.
It is a highly disciplined SDLC framework that has a parallel testing phase for each development step.
The V-Model is an extension of the Waterfall model where development and testing are performed sequentially. It is also known as the Validation or Verification model.
Business Requirement Gathering Phase: Gathering as much information as possible about the details and specifications of the software desired by the client.
Design Phase: Planning the programming language to be used, the database, etc. It should fit the project, as well as high-level functions and architecture.
Construction Phase: After the Design, we proceed to actually build the software code.
Testing Phase: Afterward, we test the software to verify that it has been created according to the specifications provided by the client.
Implementation Phase: It implements the application in the designated environment.
Maintenance Phase: Once the system is ready for use, it may be necessary to change the code later depending on user requests.
All these steps constitute the WATERFALL development model.
As you can see, testing is only performed after the implementation is completed. However, when working on a large project where systems are complex, it's easy to overlook key details in the initial phase. In such cases, a completely incorrect product will be delivered to the client, and there is the possibility of starting the entire project over.
In this way, the costs of correcting defects increase as we progress in the SDLC. The earlier they are detected, the cheaper they will be to fix.
To address these conflicts, the V-Model was developed so that each development phase has a corresponding testing phase.
In addition to the V-Model, there are other categories of iterative development where each phase adds functionality to the project in stages. Each stage comprises an independent group of cycles for testing and development.
Examples of these iterative methods are Agile Development and Rapid Application Development.
Preparing a report is a task that requires a lot of attention and care, as it is a document that should be clear and concise, containing relevant information for the reader.
A bug is the consequence or result of a fault in the code. A fault in the code can be caused by a programming error or a design error. Code errors usually occur due to a lack of knowledge on the part of the programmer or due to inattention.
It is expected that the developed software will contain a reasonable number of bugs because it is impossible to predict all possible application usage scenarios. However, the later bugs are found, the more time it will take to fix them, and the more time will be spent on testing the application.
A defect is a variation or deviation in the software application from the original business rules or requirements.
A software defect consists of an error in the coding process, which leads to incorrect or unexpected results in the program, not meeting the established requirements. Testers may encounter such defects when applying test cases.
These two terms have a subtle difference, and in the industry, both are failures that need to be corrected and are used interchangeably by some teams.
A bug report is a detailed document about bugs found in the application, containing every detail such as description, date of discovery, the name of the tester who found it, the name of the developer who fixed it, etc. These reports help identify similar bugs in the future to avoid them.
When reporting bugs to the developer, your report should contain the following information:
Defect_ID: A unique identification number for the defect.
Defect Description: Detailed description, including information about the module in which the defect was found.
Version: In which version of the application the defect was located.
Date of Occurrence: Date when the defect occurred.
Reference: Where references to documentation such as requirements, design, architecture, or even error screenshots are provided to help with understanding.
Detected by: Name/ID of the tester who identified the defect.
Status: The defect's situation.
Fixed by: Name/ID of the developer who fixed it.
Closure Date: Date when the defect was closed.
Severity: Describes the impact of the defect on the application.
Priority: Related to the urgency of defect correction. Priority can be high/medium/low based on how urgently the defect needs to be fixed.
Other necessary elements for the report include:
When does the bug occur? How can it be reproduced?
What is the incorrect behavior, and what was expected?
What is the user's impact? How critical is its correction?
Does this occur only with specific test data?
Which build was used for testing (ideally including the Git commit)?
If the bug occurs in the mobile version, what is the model, viewport size, and operating system?
If the bug occurs in a browser, what type of browser, resolution, and version?
If the bug occurs in an API, which specific API/workflow is affected, what are the request and response parameters?
Screenshot with relevant areas marked.
Video demonstrating the steps taken to encounter the bug.
Application/server logs.
Any specific selection/configuration feature, if involved when the bug occurred.
In this phase, teams must discover as many defects as possible before the end-users do. A defect is declared found and its status is changed to "Accepted" once recognized and accepted by developers.
The resolution of defects in software testing is a process that corrects deviations step by step, starting with the assignment of defects to developers, who, in turn, insert defects into a schedule based on their priority.
Once the correction is complete, developers send a report to the Test Manager, which helps in the defect correction and registration process.
Assignment: A developer or another professional receives the correction to be made and changes the status to "Responding."
Schedule Fix: The developer takes some control in this phase, creating a schedule to fix the defects based on their priority.
Defect Correction: While the development team fixes the defects, the Test Manager records the process.
Resolution Report: The report on the defect correction is sent by the developers.
This is a process where Test Managers prepare and send defect reports for management teams to provide feedback on the defect management process and the status of these defects.
The management team checks the report and may provide feedback or additional support if necessary. The defect report helps to better communicate, record, and explain defects in detail.
The management board has the right to know the status of defects, as they need to understand the management process to assist in the project. Therefore, the current situation of defects must be reported to them, considering their feedback.
# How to Measure and Evaluate Test Execution Quality
Defect Rejection Rate: (Number of rejected defects/Total number of defects)*100
Defect Leakage Rate: (Number of undetected defects/Total software defects)*100
In software testing, verification is a process of checking documents, design, code, and program to validate whether the software has been built according to the business rules.
The main goal is to ensure the quality of the application, design, architecture, etc. This process involves activities such as reviews, step-by-step checks, and inspections.
It is a dynamic mechanism that tests and validates whether the software actually meets the exact needs of the customer or not. The process helps ensure that the product meets the desired use in an appropriate environment. The Validation process involves activities such as Unit Testing, Integration Testing, System Testing, and User Acceptance Testing (UAT).
It is a process that evaluates whether a software product meets the exact requirements of end-users or investors. The purpose is to test the software product after development to ensure it meets business rules in a user environment.
Validation concerns demonstrating the consistency and completeness of the design regarding user needs. This is the stage where a version of the product is built and validated against business rules.
The goal is to provide objective evidence that the product meets user needs, where objective evidence is nothing more than physical proof of the output, such as an image, text, or an audio file that indicates the procedure's success.
This process involves testing, inspection, analysis, and more.
It is a method that confirms whether the output of a designated software product meets input specifications by examining and providing evidence. The purpose of the verification process is to ensure that the design is identical to what was specified.
Design input includes any physical and performance requirements used as a basis for design purposes. The output is the result of each design phase at the end of all development efforts. The final output is the basis for the device's master record.
During the specification development stage, identification and verification activities are carried out in parallel. This allows the designer to ensure that the specifications are verifiable. A test engineer can then initiate detailed test plans and procedures. Any changes to the specification must be communicated.
Identify the best approach for conducting verification, define measurement methods, required resources, tools, and facilities.
The complete verification plan will be reviewed by the design team to identify any issues before finalization.
Planning:
Verification planning is a concurrent activity between core and development teams. This occurs throughout the project's lifecycle and is updated when any changes are made to the inputs.
During this phase, the system or software under test must be documented within scope.
Preliminary test plans and their refinement are conducted at this stage. The plan captures critical milestones to reduce project risks.
Tools, testing environment, development strategy, and requirements identification through inspection or analysis are included.
Development:
Test case development coincides with the SLDC methodology implemented by a team. Various methods are identified during this stage.
Design inputs will be developed to include straightforward, unambiguous, and verifiable checks.
Verification time should be reduced when similar concepts are conducted in sequence. Even the output of one test can be used as input for subsequent tests.
Traceability links are created between test cases and corresponding design inputs to ensure that all requirements are tested and that the design output meets the inputs.
Execution:
The test procedures created during the development phase are executed in accordance with the verification plan, which must be strictly followed for verification activities.
If any invalid results occur, or if any procedures require modifications, it is important to document the changes and obtain relevant approvals.
At this stage, any issues are identified and cataloged as defects.
A traceability matrix is created to ensure that all identified design inputs in the verification test plan have been tested and to determine the success rate.
Reporting:
This activity is carried out at the end of each verification phase.
The design verification report provides a detailed summary of the verification results, including configuration management, test results for each modality, and issues found during verification.
The design verification traceability report is created between requirements and corresponding test results to verify that all business rules have been tested and provided with appropriate results.
Any discrepancies will be documented and appropriately addressed.
Reviews are conducted upon the completion of design verification and are approved accordingly.
Some designs can be validated by comparing them with similar equipment performing similar activities. This method is particularly relevant for validating configuration changes to existing infrastructure or standard designs to be incorporated into a new system or application.
Demonstrations and/or inspections can be used to validate business rules and other project functionalities.
Product analysis can be performed, such as mathematical modeling or simulation recreating the necessary functionality.
Tests are carried out on the final design to validate the system's ability to operate according to established guidelines.
Test plans, execution, and results must be documented and kept as part of the design records. Therefore, Validation is a collection of the results of all validation actions.
When equivalent products are used in final design validation, the manufacturer must document the similarity and any differences from the original production.
Example:
Let's take a simple product as an example, a waterproof watch.
Business rules may state that "the watch must be waterproof during swimming."
The design specification may specify that "the watch must function even if the user swims for an extended period."
Test results must confirm that the watch meets these rules, or redesign iterations are made until the requirements are satisfied.
# Advantages of Design Validation and Verification
We can continuously monitor designs, allowing us to meet user-defined requirements at each stage.
Validating the design will highlight the difference between how the functionality operates and how it should operate.
Documenting validation procedures will help easily understand the functionality at any stage in the future in case of changes or improvements.
Development time will be consistently reduced, improving productivity, enabling product delivery as expected.
This process includes the breadth and scope of each validation method that should be applied.
Any discrepancies between the results and user needs must be documented.
Changes in design validation lead to revalidations.
It is important to document all activities that occur during validation, adequately proving that the design meets user requirements.
To perform tests, it's essential to have an understanding of how the software functions. This may require the software to be in an advanced stage of development or have very consistent requirements.
There are two ways in which tests can be executed: manually or automatically. Manual execution is more common because it allows tests to be performed quickly and easily. However, it's more prone to errors since the test can be executed incorrectly. On the other hand, automated execution is slower as it requires the creation of a script responsible for running the test.
Due to these differences, manual execution is more recommended for simple tests, while automated execution is more recommended for complex tests.
The complexity of tests is relative to their scope; the larger the scope of the test, the more complex it becomes. For example, a test that checks if a button is working correctly is a simple test because it has a small scope. On the other hand, a test that verifies if an entire system is functioning correctly is a complex test because it has a large scope.
Moreover, the complexity of a test can also be measured by the number of steps required to execute it. For example, a test with only one step is a simple test, while a test with multiple steps is a complex test.
Test cases consist of a group of actions performed to verify a feature or functionality of a software application. A test case contains test steps, test data, preconditions, and postconditions developed for a specific test scenario to validate any necessary requirements.
The test case includes specific variables and conditions through which a test engineer can compare the expected results with the actual results to determine if a software product is working in accordance with the specified business rules.
Let's create a test case for the scenario: "Check Login Functionality"
Step 1) A simple test case to explain the scenario would be:
Test Case #1
Case Description:
+Verify the response when valid email and password information is entered.
Step 2) Testing the Information
In order to execute test cases, the test information needs to be added as follows:
Test Case #1
Case Description:
+Verify the response when valid email and password information is entered.
Test Data:
+Email: guru99@email.com
+Password: lNf9^Oti7^2h
Identifying test data can take time and sometimes requires the creation of new data, which is why it needs to be documented.
Step 3) Performing Actions
To execute a test case, the tester must develop a series of actions in the UAT, documented as follows:
Test Case #1
Case Description:
+Verify the response when valid email and password information is entered.
Test Steps:
+
Enter the email address.
Enter the password.
Click on Sign In.
Test Data:
+Email: guru99@email.com;
+Password: lNf9^Oti7^2h;
Often, test steps are not as simple, requiring detailed documentation. Additionally, the test case author may leave the organization, go on vacation, fall ill, or encounter other situations. A new hire may be assigned to execute the test case, and documented steps will facilitate their role and enable reviews by other stakeholders.
Step 4) Verify the Behavior of the AUT (Application Under Test)
The purpose of test cases in software testing is to verify the behavior of the UAT by comparing it to the expected result. It should be documented as follows:
Test Case #1
Case Description: Verify the response when valid email and password information is entered.
Test Steps:
+
Enter the email address.
Enter the password.
Click on Sign In.
Test Data:
+Email: guru99@email.com;
+Password: lNf9^Oti7^2h;
Expected Results:
+Successful login.
During the test execution period, the professional will compare expected results with actual results, assigning a status of Pass or Fail.
Test Case #1
Case Description: Verify the response when valid email and password information is entered.
Test Steps:
+
Enter the email address.
Enter the password.
Click on Sign In.
Test Data:
+Email: guru99@email.com;
+Password: lNf9^Oti7^2h;
Expected Results: Successful login.
Success/Failure: Success.
Step 5) The test case may have a precondition specifying elements required before the start of testing.
For our test case, a precondition would be to have a browser installed to gain access to the validation website. A test case may also include postconditions that specify any actions that apply after the completion of the test.
In this example, the postcondition would be that the login date and time are documented in the database.
The primary goal of any software project is to create test cases that meet the client's business rules and are easy to operate. A tester should create test cases with the end user in mind.
Ensure that test cases cover all software requirements mentioned in the specification documentation. Use traceability matrices to ensure that no function/condition is overlooked.
It is not possible to test all possible conditions in a software application. Testing techniques help select test cases with the highest likelihood of finding defects.
Boundary Value Analysis (BVA): This technique tests the boundaries of a specific range of values, as the name suggests.
Equivalence Partitioning (EP): This technique divides the range into equal parts/groups that tend to behave the same way.
State Transition Technique: This method is used when the behavior of software changes from one state to another following a particular action.
Error Guessing Technique: This technique guesses/anticipates errors that may arise during manual test execution. It is not a formal method and relies on the tester's experience with the application.
Test cases should return the Testing Environment to its pre-test state, without rendering the test environment unusable. This is especially relevant for configuration tests.
After creating test cases, have them reviewed by your colleagues. Your peers may find defects in the case design.
Include the following information when developing a test case:
The description of the requirement being tested.
Explanation of how the system will be validated.
Test setup, such as a version of the application under verification, software, data files, operating system, security access, logical or physical data, time of day, prerequisites like other tests, and any other setup information relevant to the requirements being tested.
Inputs, outputs, actions, and their expected results.
Any evidence or attachments.
Use active language with proper capitalization.
Test cases should not have more than 15 steps.
An automated test script is commented with inputs, purpose, and expected results.
The setup provides an alternative for required pre-tests.
If there are other tests, it should be ordered correctly in the business scenario.
Test case management tools are automation elements that help coordinate and maintain test cases. The main functionalities of such a tool are:
Document Test Cases: With tools, test case creation can be accelerated using templates.
Execute Test Cases and Document Results: Test cases can be executed through the tools, and results can be collected for easy record-keeping.
Automate Defect Tracking: Tests that fail are automatically linked to the bug tracker, which can then be assigned to developers via email notification.
Traceability: Requirements, test cases, and their executions are linked through the tools, and each test case can be traced back to others to validate coverage.
Protect Test Cases: Test cases should be reusable and protected from loss or corruption due to poor version control.
This testing technique involves manually executed test cases by a professional without any assistance from automated tools. The purpose of Manual Testing is to identify bugs, issues, and defects in the application. Manual software testing is the most primitive technique among all approaches and helps in identifying critical API bugs.
Any new application needs to be manually tested before it is automated. This technique requires more effort but is necessary to assess the automation feasibility.
The concept of manual testing does not require any knowledge of testing tools. One of the fundamentals of Software Testing is "100% automation is not possible," which makes the manual approach imperative.
The key concept of manual testing is to ensure that the application is bug-free and works in compliance with functional business rules.
Test suites and test cases are developed during the testing phase and should have 100% coverage, ensuring that reported defects are fixed by developers and retesting is performed by testers on the fixed defects.
Basically, this technique checks the system's quality and delivers a bug-free product to the customer.
Automated testing is the application of software tools to automate a manual process of reviewing and validating software products. Modern Agile and DevOps projects include this technique.
This approach places ownership responsibilities in the hands of the engineering team. Test plans are developed in parallel with the standard development script and are executed automatically by continuous integration tools. This promotes an efficient QA team and allows the development team to focus on more critical features.
Continuous Delivery (CD) refers to delivering new code releases to customers as quickly as possible, and test automation plays a critical role in achieving this goal. There is no way to automate user delivery if there is a manual and time-consuming process within the delivery process.
Continuous delivery is part of a larger deployment pipeline and is both a successor and dependent on continuous integration (CI). CI is entirely responsible for running automated tests on any code changes, ensuring that these changes do not break established features or introduce new bugs.
Continuous deployment comes into play once the continuous integration step passes the automated test plan.
This relationship between automated testing, CI, and CD yields many benefits for a highly efficient team. Automation ensures quality throughout development by checking that new commits do not introduce bugs, making the software ready for deployment at any time.
Arguably one of the most valuable tests to implement, this technique simulates a user-level experience throughout the entire software product. End-to-end test plans typically cover user-level stories such as "the user can log in," "the user can make a deposit," "the user can change email settings."
Implementing these tests is highly valuable as they provide assurance that real users will have a smooth, bug-free experience even when new commits are applied.
As the name suggests, unit tests cover individual parts of the code, best measured in function definitions.
A unit test will validate an individual function by checking that the expected input to a function matches the expected output. Code that involves sensitive calculations (such as finances, healthcare, or aerospace) is best covered by this testing technique.
Unit tests are characterized by their low cost and implementation speed, providing a high return on investment.
Often, a unit of code will make an external call to a third-party service, but the primary codebase under test will not have access to the code of this third-party utility.
Integration tests will handle the mocking of these third-party dependencies to verify that the code that interfaces behaves as expected.
This technique is similar to unit testing in how they are written and their tools. They are a cheaper alternative to end-to-end tests, but the return on investment is debatable when a combination of unit and end-to-end tests is already established.
When used in the context of software development, 'performance' refers to the speed and responsiveness with which a software project responds. Some examples of performance metrics include:
Page load time
Initial rendering time
Search result response time
These types of tests create metrics and assurances for these cases.
In their automated version, performance tests will run test cases through the metrics and alert the team if regressions or speed losses occur.
# What types of tests should be executed manually?
It is debatable whether all tests that can be automated should be. Automation represents a significant gain in productivity and cost of labor hours, but there are situations in which the Return on Investment (ROI) for developing a battery of automated tests is lower compared to manual test execution.
Automated tests are, by definition, scripted and follow a sequence of steps to validate a behavior. Exploratory testing is more random and applies non-scripted sequences to find bugs or unexpected behaviors.
While there are tools to establish a battery of exploratory tests, they have not been refined enough and have not been widely adopted by companies. It can be much more efficient to assign a manual tester and use human creativity to explore how to break a software product.
Visual regression occurs when a visual design flaw is introduced in the product's UI, which may consist of improperly positioned elements, wrong fonts or colors, and more.
Just as in exploratory testing, there are tools for developing automated tests to detect these regressions. The tools take screenshots from different product states, apply Optical Character Recognition (OCR) to compare them to expected results. These tests have a high development cost, and the tools have not been widely adopted, making the human and manual option more efficient in some cases.
# 3. Building Automation Frameworks for DevOps Teams
There is no one-size-fits-all solution for test automation. When developing an automation plan, some key points should be considered:
Release Frequency:
+Software products released at fixed intervals, such as monthly or weekly, may be better suited to manual testing. Products with faster releases greatly benefit from automated tests, as CI and CD depend on automated testing.
Available Tools and Ecosystem:
+Each programming language has its ecosystem of complementary tools and utilities. Each type of automated testing standard has its own set of tools that may or may not be available in certain language ecosystems. Successfully implementing an automated testing standard will require an intersection of language and tooling support.
Product Market Fit and Codebase Maturity:
+If the team is building a new product that has not been validated by a target audience and business model, it may not make sense to invest in automated testing. Considering the team works at high speed, it can be frustratingly expensive to update and maintain automated tests when the code changes dramatically and quickly.
This framework can help both developers and QA teams create high-quality software, reduce the time developers spend figuring out if an introduced change breaks the code, and contribute to a more reliable battery of tests.
Essentially, the testing pyramid, also known as the automation pyramid, establishes the types of tests to be included in an automated battery and defines the sequence and frequency of these tests.
The main goal is to provide immediate feedback, ensuring that changes in the code do not negatively affect existing features.
Unit tests form the base of the pyramid, validating individual components and functionalities to ensure they work correctly under isolated conditions. Therefore, it's essential to run various scenarios in unit tests.
As the most significant subgroup, the unit test suite should be written to execute as quickly as possible.
Remember that the number of unit tests will increase as new features are added.
This suite should be run whenever a new feature is implemented.
Consequently, developers receive immediate feedback on whether individual features work in their current form.
An efficient, fast-running unit test suite encourages developers to apply it frequently.
The application of Test-Driven Development (TDD) contributes to creating a robust suite, as the technique requires writing tests before any code is established, making it more straightforward, transparent, and bug-free.
While unit tests verify small pieces of code, integration tests should be run to check how different parts of the software interact with each other. Essentially, these are tests that validate how a piece of code interacts with external components, ranging from databases to external services (APIs).
Integration tests constitute the second layer of the pyramid, meaning they should not be run as frequently as unit tests.
Fundamentally, they test how a feature communicates with external dependencies.
Whether it's a database query or a web service call, the software should communicate efficiently and fetch the right information to function as expected.
It's important to note that this technique involves interaction with external services, so its execution will be slower than unit tests. Moreover, they require a pre-production environment to be applied.
The highest level of the pyramid ensures that the entire application works as it should by testing it from start to finish.
This technique is at the top of the pyramid because it takes longer to run.
When developing these tests, it's essential to think from a user's perspective.
How would a user use this application? How can tests be written to replicate these interactions?
They can also be fragile as they need to test various usage scenarios.
Like integration tests, they may require the application to communicate with external elements, which can potentially contribute to bottlenecks in completion.
A helpful tutorial on the strategy behind end-to-end tests can be found here(opens new window).
#Why Agile Teams Should Use the Automation Pyramid
Agile processes prioritize speed and efficiency, elements offered by the pyramid by organizing the testing process in a logical and clear progression, promoting efficient work completion.
Since the structure is designed to run more accessible tests first, testers can better manage their time, achieving better results and improving the work of everyone involved by providing the right priorities to the testing team.
If test scripts are written with a greater focus on the UI, chances are that the core business logic and backend functionality have not been thoroughly verified. This affects product quality and leads to an increase in team workload.
Additionally, the response time of UI tests is high, resulting in lower overall test coverage. By implementing the automation pyramid, these situations are completely addressed.
In test automation, tools and frameworks like Selenium execute scripted tests on software applications or components to ensure they work as expected. Their sole aim is to reduce human effort and error, but for the machine to provide the correct results, it must be appropriately directed.
The automation pyramid seeks to meet this need by organizing and structuring the testing cycle, streamlining the entire process and providing efficient time management, enabling testers to use validated patterns to shape their projects.
Commonly developed for database verification, the Back-End test is a process that verifies server parameters for a smooth transition. It is one of the most essential testing activities, occurring in all programs.
Data storage typically occurs in the backend, which is validated by the testing process to eliminate any threats in the database.
Different types of databases are available in the market, ranging from SQL, Oracle, DB2, MYSQL, etc. Data organization into specific tables is one of the important factors to consider. It helps provide the correct output on the front end.
Some of the most sensitive problems and complications, such as data corruption and loss, are solved through database testing.
It is not mandatory to view backend testing through user graphical interfaces; therefore, the tests occur only in functionalities and source codes. Browser parameters are commonly checked depending on the program or project.
Back-end testing is usually completed in a few steps, so it's essential to understand the purpose of the process before starting.
The initial steps examine the database and server before progressing to functions; the subsequent steps are built based on specifications and programming.
Testers prefer to conduct backend tests in the early stages for various reasons. The technique helps identify some of the basic problems with the database and also resolves server-related issues.
Modern tools easily identify backend issues, saving significant amounts of time without compromising quality.
The nature of testing depends a lot on how we interact or not with the system under test. Given these factors, we can classify tests into three distinct approaches.
In this second chapter we will discuss these different testing approaches, how they are performed and what are their advantages and disadvantages.
There are numerous types of tests, each with its purpose and characteristics. If you are starting in the testing area, it is important that you understand the difference between each of them, as this will help you to choose the type of test that you will perform in each situation.
In the following chapter we will describe in detail each of the existing types of tests, their characteristics and how to apply them.
Project administration is a crucial topic in the field of testing because it ensures that the project is being developed correctly and that there are no issues that could hinder development. However, managing a project is not an easy task. There are various ways to administer a project, each with its advantages and disadvantages.
Tests can be executed in two distinct ways: manually or automatically. The choice of which method to use depends on the type of project being developed and the type of test being conducted.
A natureza dos testes depende muito de como interagimos ou não com o sistema sob teste. Dados esses fatores, podemos classificar os testes em três abordagens distintas.
Nesse segundo capítulo iremos discutir sobre essas diferentes abordagens de testes, como elas são realizadas e quais são as suas vantagens e desvantagens.
Existem inúmeros tipos de testes, cada um com sua finalidade e características. Caso você esteja iniciando na área de testes, é importante que você entenda a diferença entre cada um deles, pois isso irá te ajudar a escolher o tipo de teste que você irá executar em cada situação.
Nesse capítulo iremos descrever em detalhes cada um dos tipos existentes de testes, suas características e como aplicá-los.
Administração de projeto é um tópico muito importante para a área de testes, pois é através dela que podemos garantir que o projeto está sendo desenvolvido da maneira correta, e que não há nenhum tipo de problema que possa prejudicar o desenvolvimento. Porém, administrar um projeto não é uma tarefa fácil. Existem diversas maneiras que podem ser utilizadas para administrar um projeto, cada uma com suas vantagens e desvantagens.
Os testes podem ser executados de duas formas distintas: manualmente ou automaticamente. A escolha de qual método utilizar depende do tipo de projeto que está sendo desenvolvido, e também do tipo de teste que está sendo executado.
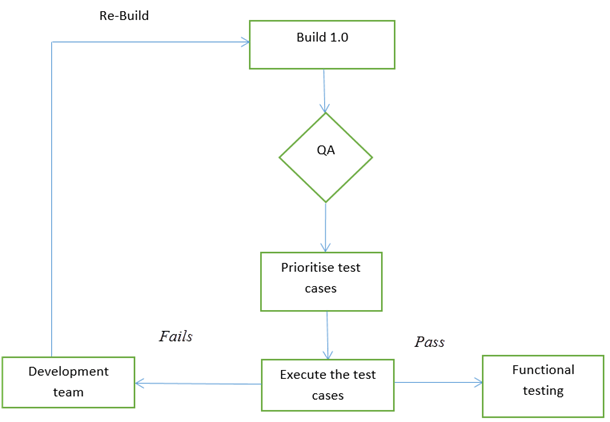 diff --git a/docs/02-tipos/08-integracao.md b/docs/02-tipos/08-integracao.md
deleted file mode 100644
index 2fd88dc..0000000
--- a/docs/02-tipos/08-integracao.md
+++ /dev/null
@@ -1,168 +0,0 @@
-# Teste de Integração
-
-É um tipo de teste onde os módulos de software são logicamente integrados e testados como um grupo.
-
-Um projeto de software típico consiste de múltiplos módulos, codificados por programadores diferentes, o propósito deste nível de teste é expor defeitos na interação entre estes módulos uma vez integrados.
-Esta técnica foca na validação da comunicação de dados entre estes módulos, também conhecido como *I & T (Integration and Testing)*, *String Testing*, e, por vezes *Thread Testing*.
-
-## Por que realizar o Teste de Integração
-
-Embora cada módulo seja baseado em unidades, defeitos ainda existem por diversas razões:
-
-- Um módulo, no geral, é projetado por um dev individual, que pode possuir uma compreensão e lógica diferente de outros programadores;
-- No momento do desenvolvimento de um módulo, existes grandes chance de mudança nas regras de negócios por parte dos clientes. Estes novos requirementos podem não ser testados de forma unitário, e, portanto, o teste de integração do sistema se faz necessário;
-- A interface entre módulo e database pode ser errônea;
-- Interfaces de Hardware externo, caso existam, podem ser errõneas;
-- Administração inadequada de exceções podem causar erros;
-
-## Exemplo de caso de Teste de Integração
-
-O caso de testes de Integração difere de outras modalidades no sentido de que foca principalmente nas interface e fluxo de dados/informações entre os módulos.
-
-A prioridade aqui são os links de integração ao invés das funções unitárias que ja foram testadas.
-
-### *Casos de teste de Integração entre Amostras para o seguinte cenário:*
-
-Aplicação possuí 3 módulos
-
-- Página de Login;
-- Caixa de Correio;
-- Deletar E-Mails;
-
- Todos integrados lógicamente.
-
- Aqui, não nos concentramos no teste da Página de Login já que os testes para esta feature já foram conduzidos no Teste Unitário, mas sim, checamos sua integração com a Caixa de Correio.
-
- De forma semelhante, checamos a integração entre Caixa de Correio e o módulo Deletar E-Mails.
-
- - Casos de teste:
- - Caso 1
- - Objetivo: Verificar o link de interface entre Login e Caixa de Correio;
- - Descrição do Caso de Testes: Inserir credenciais de login e clicar no botão Login;
- - Resultado Esperado: Ser direcionado até Caixa de Correio;
- - Caso 2
- - Objetivo: Checar o link de interface entre Caixa de Correio e Deletar E-Mails;
- - Descrição do Caso: a partir de Caixa de Correio, selecione o e-mail e clique em um botão deletar;
- - Resultado Esperado: e-mail selecionado aparecer na aba de deletados/lixo;
-
-## Tipos de Teste de Integração
-
-Engenharia de software define uma míriade de estratégias para executar o teste de integração, vide:
-
-- Abordagem Big Bang
-- Abordagem Incremental: que é subdividada em duas partes
- - Abordagem de cima pra baixo (Top Down);
- - Abordagem de baixo pra cima (Bottom Up);
- - Abordagem Sanduíche (combina as duas anteriores);
-
-### Testagem Big Bang
-
- É uma abordagem no teste de integração em que todos os componentes ou módulos são integrados juntos de uma só vez e testados como uma unidade.
-
- Este conjunto combinado de componentes é considerado como uma entidade durante os tstes, se todos os componentes na unidade não estão completos, a integração não sera executada.
-
-- Vantagens:
- - Conveniente para sistemas pequenos
-
-- Desvantagens:
- - Localização de falhas é dificil;
- - Dado o número de interfaces que precisam ser testadas neste método, algumas conexões de interface podem ser esquecidas facilmente;
- - Uma vez que o teste de integração pode começar apenas depois de "todos" os modulos foram arquitetados, o time de testes terá menos tempo para execução na fase de testes;
- - Dados que todos módulos são testados de uma vez, módulos críticos de alto risco não são isolados e testados com prioridade. Módulos periféricos que lidam com menos interfaces de usuários também não são isolados para testagem prioritária;
-
-### Testagem Incremental
-
-Nesta abordagem o teste é feito integrando dois ou mais módulos que são lógicamente relacionados entre si, e então, testados para funcionamento adequado da aplicação.
-
-Então, os outros módulos relacionados são integrados incrementalmente e o processo continua até que todos os módulos lógicamente relacionados tenham sido testados com sucesso.
-
- Stubs e Drivers:
- São os programas dummy utilizados para facilitar a atividades de testes. Estes programas agem como substitutos para os modelos faltantes no teste. Eles não implementam toda a lóica de programação do módulo mas simulam a comunicação de dados com o módulo calling durante os testes.
- - Stub: é chamado pelo módulo sub testes.
- - Driver: chama o módula para ser testado.
-
-### Teste de Integração Bottom-up
-
-É a estratégia em que os módulos de mais baixo nível são testados primeiro.
-
-Estes módulos já testados são então utilizados para facilitar o teste de módulos de nível mais alto. O processo continua até que todos os de nível máximo tenham sido verificados.
-
-Uma vez que os módulos de nível baixo foram testados e integrados, o próximo nível de módulos é formado.
-
-
diff --git a/docs/02-tipos/08-integracao.md b/docs/02-tipos/08-integracao.md
deleted file mode 100644
index 2fd88dc..0000000
--- a/docs/02-tipos/08-integracao.md
+++ /dev/null
@@ -1,168 +0,0 @@
-# Teste de Integração
-
-É um tipo de teste onde os módulos de software são logicamente integrados e testados como um grupo.
-
-Um projeto de software típico consiste de múltiplos módulos, codificados por programadores diferentes, o propósito deste nível de teste é expor defeitos na interação entre estes módulos uma vez integrados.
-Esta técnica foca na validação da comunicação de dados entre estes módulos, também conhecido como *I & T (Integration and Testing)*, *String Testing*, e, por vezes *Thread Testing*.
-
-## Por que realizar o Teste de Integração
-
-Embora cada módulo seja baseado em unidades, defeitos ainda existem por diversas razões:
-
-- Um módulo, no geral, é projetado por um dev individual, que pode possuir uma compreensão e lógica diferente de outros programadores;
-- No momento do desenvolvimento de um módulo, existes grandes chance de mudança nas regras de negócios por parte dos clientes. Estes novos requirementos podem não ser testados de forma unitário, e, portanto, o teste de integração do sistema se faz necessário;
-- A interface entre módulo e database pode ser errônea;
-- Interfaces de Hardware externo, caso existam, podem ser errõneas;
-- Administração inadequada de exceções podem causar erros;
-
-## Exemplo de caso de Teste de Integração
-
-O caso de testes de Integração difere de outras modalidades no sentido de que foca principalmente nas interface e fluxo de dados/informações entre os módulos.
-
-A prioridade aqui são os links de integração ao invés das funções unitárias que ja foram testadas.
-
-### *Casos de teste de Integração entre Amostras para o seguinte cenário:*
-
-Aplicação possuí 3 módulos
-
-- Página de Login;
-- Caixa de Correio;
-- Deletar E-Mails;
-
- Todos integrados lógicamente.
-
- Aqui, não nos concentramos no teste da Página de Login já que os testes para esta feature já foram conduzidos no Teste Unitário, mas sim, checamos sua integração com a Caixa de Correio.
-
- De forma semelhante, checamos a integração entre Caixa de Correio e o módulo Deletar E-Mails.
-
- - Casos de teste:
- - Caso 1
- - Objetivo: Verificar o link de interface entre Login e Caixa de Correio;
- - Descrição do Caso de Testes: Inserir credenciais de login e clicar no botão Login;
- - Resultado Esperado: Ser direcionado até Caixa de Correio;
- - Caso 2
- - Objetivo: Checar o link de interface entre Caixa de Correio e Deletar E-Mails;
- - Descrição do Caso: a partir de Caixa de Correio, selecione o e-mail e clique em um botão deletar;
- - Resultado Esperado: e-mail selecionado aparecer na aba de deletados/lixo;
-
-## Tipos de Teste de Integração
-
-Engenharia de software define uma míriade de estratégias para executar o teste de integração, vide:
-
-- Abordagem Big Bang
-- Abordagem Incremental: que é subdividada em duas partes
- - Abordagem de cima pra baixo (Top Down);
- - Abordagem de baixo pra cima (Bottom Up);
- - Abordagem Sanduíche (combina as duas anteriores);
-
-### Testagem Big Bang
-
- É uma abordagem no teste de integração em que todos os componentes ou módulos são integrados juntos de uma só vez e testados como uma unidade.
-
- Este conjunto combinado de componentes é considerado como uma entidade durante os tstes, se todos os componentes na unidade não estão completos, a integração não sera executada.
-
-- Vantagens:
- - Conveniente para sistemas pequenos
-
-- Desvantagens:
- - Localização de falhas é dificil;
- - Dado o número de interfaces que precisam ser testadas neste método, algumas conexões de interface podem ser esquecidas facilmente;
- - Uma vez que o teste de integração pode começar apenas depois de "todos" os modulos foram arquitetados, o time de testes terá menos tempo para execução na fase de testes;
- - Dados que todos módulos são testados de uma vez, módulos críticos de alto risco não são isolados e testados com prioridade. Módulos periféricos que lidam com menos interfaces de usuários também não são isolados para testagem prioritária;
-
-### Testagem Incremental
-
-Nesta abordagem o teste é feito integrando dois ou mais módulos que são lógicamente relacionados entre si, e então, testados para funcionamento adequado da aplicação.
-
-Então, os outros módulos relacionados são integrados incrementalmente e o processo continua até que todos os módulos lógicamente relacionados tenham sido testados com sucesso.
-
- Stubs e Drivers:
- São os programas dummy utilizados para facilitar a atividades de testes. Estes programas agem como substitutos para os modelos faltantes no teste. Eles não implementam toda a lóica de programação do módulo mas simulam a comunicação de dados com o módulo calling durante os testes.
- - Stub: é chamado pelo módulo sub testes.
- - Driver: chama o módula para ser testado.
-
-### Teste de Integração Bottom-up
-
-É a estratégia em que os módulos de mais baixo nível são testados primeiro.
-
-Estes módulos já testados são então utilizados para facilitar o teste de módulos de nível mais alto. O processo continua até que todos os de nível máximo tenham sido verificados.
-
-Uma vez que os módulos de nível baixo foram testados e integrados, o próximo nível de módulos é formado.
-
-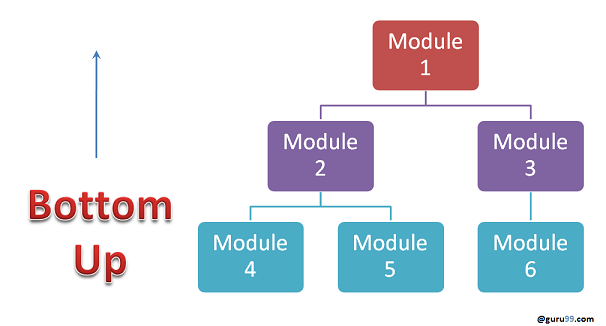 -
- 1. Vantagens:
- - Localização de erros é mais fácil;
- - Não perde-se tempo aguardando que todos os módulos sejam desenvolvidos como na abordagem Big-Bang
- 2. Desvantagens:
- - Módulos críticos (no nível máximo da arquitetura de software) que controlam o fluxo da aplicação são testados por ultimo e podem ser tendentes a defeitos;
- - Um protótipo de estágio inicial não é possível;
-
-### Teste de Integração Top-down
-
-Método em que a testagem se inicia do topo para baixo seguinto o fluxo de controle do sistema de software.
-
-Os níveis mais altos são testados primeiro, seguindo então para os de nivel mais baixos, que são integrados para checar a funcionalidade do software. Stubs são utilizados para testar caso alguns módulos não estiverem prontos.
-
-
-
- 1. Vantagens:
- - Localização de erros é mais fácil;
- - Não perde-se tempo aguardando que todos os módulos sejam desenvolvidos como na abordagem Big-Bang
- 2. Desvantagens:
- - Módulos críticos (no nível máximo da arquitetura de software) que controlam o fluxo da aplicação são testados por ultimo e podem ser tendentes a defeitos;
- - Um protótipo de estágio inicial não é possível;
-
-### Teste de Integração Top-down
-
-Método em que a testagem se inicia do topo para baixo seguinto o fluxo de controle do sistema de software.
-
-Os níveis mais altos são testados primeiro, seguindo então para os de nivel mais baixos, que são integrados para checar a funcionalidade do software. Stubs são utilizados para testar caso alguns módulos não estiverem prontos.
-
-