Disclosure of Invention
It is an object of embodiments of the present invention to address at least the above problems and/or disadvantages and to provide at least the advantages described hereinafter.
The embodiment of the invention provides a thermodynamic diagram generation method and device based on track data, electronic equipment and a storage medium, and the thermodynamic diagram generation method and device based on track data can improve the efficiency of thermodynamic diagram visualization.
In a first aspect, a thermodynamic diagram generation method based on trajectory data is provided, including:
acquiring track data and map data;
storing the track data in a Hadoop platform distributed file system in an original format;
clustering the track data to obtain clustered data;
storing the map data and the cluster data in an HBase distributed database;
obtaining map data and clustering data corresponding to the thermodynamic diagram to be generated from the HBase distributed database;
and generating a thermodynamic diagram according to the acquired map data and the cluster data.
Optionally, the storing the trajectory data in the Hadoop platform distributed file system in the original format includes:
dividing the track data into a plurality of time slices, wherein each time slice comprises all track data in a preset time range;
in the Hadoop platform distributed file system, the track data contained in the same time slice is stored in a concentrated mode in an original format, and the time slices are stored adjacently according to a time sequence.
Optionally, the map data has a plurality of zoom levels;
the clustering the track data to obtain clustered data includes:
determining a plurality of groups of clustering parameters according to the plurality of zoom levels;
clustering is carried out on the track data contained in each time slice according to the multiple groups of clustering parameters to obtain multiple groups of clustering data corresponding to the multiple zooming levels for each time slice;
the acquiring of the map data and the cluster data corresponding to the thermodynamic diagram to be generated from the HBase distributed database comprises the following steps:
determining the zoom level of the map data corresponding to the thermodynamic diagram to be generated according to the zoom level of the thermodynamic diagram to be generated;
determining a time slice to which clustering data corresponding to the thermodynamic diagram to be generated belong according to the time range of the thermodynamic diagram to be generated;
and acquiring the map data under the corresponding zoom level and the cluster data under the corresponding zoom level under the corresponding time slice from the HBase distributed database.
Optionally, the map data has a plurality of zoom levels;
the clustering the track data to obtain clustered data includes:
determining a plurality of groups of clustering parameters according to the plurality of zoom levels;
clustering the track data according to the multiple groups of clustering parameters to obtain multiple groups of clustering data corresponding to the multiple zooming levels;
the acquiring of the map data and the cluster data corresponding to the thermodynamic diagram to be generated from the HBase distributed database comprises the following steps:
determining the zoom level of the map data corresponding to the thermodynamic diagram to be generated according to the zoom level of the thermodynamic diagram to be generated;
and obtaining the map data and the cluster data under the corresponding zoom level from the HBase distributed database.
Optionally, the sets of clustering parameters include a scan radius;
determining a plurality of groups of clustering parameters according to the plurality of zoom levels comprises:
determining a scanning radius corresponding to each zooming level according to the zooming levels; wherein the scan radius corresponding to each zoom level decreases as the respective zoom level decreases.
Optionally, each set of clustering parameters includes a minimum contained point number;
the determining multiple groups of clustering parameters according to the multiple zoom levels further comprises:
and determining the minimum contained points corresponding to each zooming level according to the zooming levels, wherein the minimum contained points corresponding to each zooming level are reduced along with the reduction of the corresponding zooming level.
Optionally, the sets of cluster data include center coordinates and influence values of a plurality of cluster clusters and coordinates and influence values of a plurality of noise points.
Optionally, the clustering is implemented based on DBScan algorithm.
Optionally, the storing the cluster data in an HBase distributed database includes:
and respectively constructing each clustering data table aiming at each group of clustering data of each time slice corresponding to each zoom level.
Optionally, the map data has a plurality of zoom levels;
the storing the map data in an HBase distributed database comprises:
and constructing each map data table aiming at the map data at each zoom level, and storing 4 tiles which are contained in the map data at each zoom level and are adjacent to each other in a display state into the same row in the corresponding map data table.
Optionally, the constructing each map data table for the map data at each zoom level, and storing 4 tiles, which are included in the map data at each zoom level and are adjacent to each other in the display state, in the same row in the corresponding map data table includes:
calculating the total order m of the map data at each zoom level according to the number n of tiles contained in each row of the map data at each zoom level, wherein,
when n-2m is 1, dividing the map data at each zoom level into m × m square sub-grids and n edge sub-grids, wherein the square sub-grids are composed of 4 tiles, 2m edge sub-grids adjacent to the square sub-grids are composed of 2 tiles, and 1 edge sub-grid not adjacent to the square sub-grids is composed of 1 tile;
filling the m-by-m square sub-grids based on a Z-shaped filling curve, filling the 2m edge sub-grids based on a linear type filling curve, connecting the m-by-m square sub-grids and the filling curves of the 2m edge sub-grids into a whole, and extending the filling curves of the m-by-m square sub-grids and the 2m edge sub-grids to 1 edge sub-grid which is not adjacent to the square sub-grids;
encoding the n tiles according to their filling order;
and constructing each map data table aiming at the map data under each zoom level, and sequentially storing the n tiles in the corresponding map data table based on the codes of the n tiles, wherein 4 tiles belonging to the same square sub-grid are stored in the same row in the corresponding map data table, and the tiles belonging to the same edge sub-grid are stored in the same row in the corresponding map data table.
Optionally, the constructing each map data table for the map data at each zoom level, and storing 4 tiles, which are included in the map data at each zoom level and are adjacent to each other in the display state, in the same row in the corresponding map data table includes:
calculating the total order m of the map data at each zoom level according to the number n of tiles contained in each row of the map data at each zoom level, wherein,
when n is 2m, dividing the map data of each zoom level into m square sub-grids, wherein the square sub-grids are composed of 4 tiles;
filling the m by m square sub-grids based on a Z-shaped filling curve;
encoding the n tiles according to their filling order;
and constructing each map data table aiming at the map data under each zoom level, and sequentially storing the n tiles in the corresponding map data table based on the codes of the n tiles, wherein 4 tiles belonging to the same square sub-grid are stored in the same row in the corresponding map data table.
In a second aspect, a thermodynamic diagram generation apparatus based on trajectory data is provided, including:
the first acquisition module is used for acquiring track data and map data;
the first storage module is used for storing the track data in a Hadoop platform distributed file system in an original format;
the clustering module is used for clustering the track data to obtain clustering data;
the second storage module is used for storing the map data and the cluster data in an HBase distributed database;
the second acquisition module is used for acquiring map data and cluster data corresponding to the thermodynamic diagram to be generated from the HBase distributed database;
and the generating module is used for generating the thermodynamic diagram according to the acquired map data and the cluster data.
Optionally, the first storage module is specifically configured to:
dividing the track data into a plurality of time slices, wherein each time slice comprises all track data in a preset time range;
in the Hadoop platform distributed file system, the track data contained in the same time slice is stored in a concentrated mode in an original format, and the time slices are stored adjacently according to a time sequence.
Optionally, the map data has a plurality of zoom levels;
the clustering module comprises:
a first determining unit, configured to determine multiple groups of clustering parameters according to the multiple zoom levels;
the clustering unit is used for clustering the track data contained in each time slice according to the multiple groups of clustering parameters to obtain multiple groups of clustering data corresponding to the multiple zoom levels for each time slice;
the second obtaining module includes:
a second determining unit, configured to determine, according to a zoom level of the thermodynamic diagram to be generated, a zoom level of map data corresponding to the thermodynamic diagram to be generated;
a third determining unit, configured to determine, according to the time range of the thermodynamic diagram to be generated, a time slice to which cluster data corresponding to the thermodynamic diagram to be generated belongs;
and the acquisition unit is used for acquiring the map data at the corresponding zoom level and the cluster data at the corresponding zoom level in the corresponding time slice from the HBase distributed database.
Optionally, the map data has a plurality of zoom levels;
the clustering module comprises:
a first determining unit, configured to determine multiple groups of clustering parameters according to the multiple zoom levels;
the clustering unit is used for clustering the track data according to the multiple groups of clustering parameters to obtain multiple groups of clustering data corresponding to the multiple zooming levels;
the second obtaining module includes:
a second determining unit, configured to determine, according to a zoom level of the thermodynamic diagram to be generated, a zoom level of map data corresponding to the thermodynamic diagram to be generated;
and the acquisition unit is used for acquiring the map data and the cluster data under the corresponding zoom level from the HBase distributed database.
Optionally, the sets of clustering parameters include a scan radius;
the first determining unit is specifically configured to:
determining a scanning radius corresponding to each zooming level according to the zooming levels; wherein the scan radius corresponding to each zoom level decreases as the respective zoom level decreases.
Optionally, each set of clustering parameters includes a minimum contained point number;
the first determining unit is specifically configured to:
and determining the minimum contained points corresponding to each zooming level according to the zooming levels, wherein the minimum contained points corresponding to each zooming level are reduced along with the reduction of the corresponding zooming level.
Optionally, the sets of cluster data include center coordinates and influence values of a plurality of cluster clusters and coordinates and influence values of a plurality of noise points.
Optionally, the clustering is implemented based on DBScan algorithm.
Optionally, the second storage module includes:
and the first construction unit is used for constructing each clustering data table aiming at each group of clustering data corresponding to each zooming level of each time slice.
Optionally, the map data has a plurality of zoom levels;
the second storage module includes:
and the second construction unit is used for constructing each map data table aiming at the map data at each zoom level and storing 4 tiles which are adjacent to each other in the display state and are contained in the map data at each zoom level in the same row of the corresponding map data table.
Optionally, the second building unit is specifically configured to:
calculating the total order m of the map data at each zoom level according to the number n of tiles contained in each row of the map data at each zoom level, wherein,
when n-2m is 1, dividing the map data at each zoom level into m × m square sub-grids and n edge sub-grids, wherein the square sub-grids are composed of 4 tiles, 2m edge sub-grids adjacent to the square sub-grids are composed of 2 tiles, and 1 edge sub-grid not adjacent to the square sub-grids is composed of 1 tile;
filling the m-by-m square sub-grids based on a Z-shaped filling curve, filling the 2m edge sub-grids based on a linear filling curve, and connecting the m-by-m square sub-grids and the n edge sub-grids by using connecting lines;
encoding the n tiles according to their filling order;
and constructing each map data table aiming at the map data under each zoom level, and sequentially storing the n tiles in the corresponding map data table based on the codes of the n tiles, wherein 4 tiles belonging to the same square sub-grid are stored in the same row in the corresponding map data table, and the tiles belonging to the same edge sub-grid are stored in the same row in the corresponding map data table.
Optionally, the second building unit is specifically configured to:
calculating the total order m of the map data at each zoom level according to the number n of tiles contained in each row of the map data at each zoom level, wherein,
when n is 2m, dividing the map data of each zoom level into m square sub-grids, wherein the square sub-grids are composed of 4 tiles;
filling the m by m square sub-grids based on a Z-shaped filling curve;
encoding the n tiles according to their filling order;
and constructing each map data table aiming at the map data under each zoom level, and sequentially storing the n tiles in the corresponding map data table based on the codes of the n tiles, wherein 4 tiles belonging to the same square sub-grid are stored in the same row in the corresponding map data table.
In a third aspect, an electronic device is provided, including: at least one processor, and a memory communicatively coupled to the at least one processor, wherein the memory stores instructions executable by the at least one processor to cause the at least one processor to perform the method described above.
In a fourth aspect, a storage medium is provided, on which a computer program is stored which, when executed by a processor, implements the method described above.
The embodiment of the invention at least comprises the following beneficial effects:
according to the thermodynamic diagram generation method and device based on the track data, provided by the embodiment of the invention, the track data and the map data are firstly obtained; storing the track data in a Hadoop platform distributed file system in an original format; clustering the track data to obtain clustered data; storing the map data and the cluster data in an HBase distributed database; obtaining map data and clustering data corresponding to the thermodynamic diagram to be generated from the HBase distributed database; and generating a thermodynamic diagram according to the acquired map data and the cluster data. Based on the method and the device, the efficiency of thermodynamic diagram visualization can be improved while the position characteristics of the track data are kept, the diagram forming time is shortened, the problem of unsmooth caused by user interaction is solved, and the user experience is improved.
Additional advantages, objects, and features of embodiments of the invention will be set forth in part in the description which follows and in part will become apparent to those having ordinary skill in the art upon examination of the following or may be learned from practice of embodiments of the invention.
Detailed Description
The embodiments of the present invention will be described in further detail with reference to the accompanying drawings so that those skilled in the art can implement the embodiments of the invention with reference to the description.
At present, relational databases such as Oracle and PostgreSQL serve as a data warehouse for storing track data, and are mainly used for statically storing and expressing the state of the track data in a certain specific period, so that information storage and management in a certain period cannot be performed in real time. Specifically, the conventional database storage scheme may reach an upper limit of a processing load when the input and output data amount is large, and is not sufficient to support fast storage and query of mass data, and the conventional database has a single data type, and has poor performance in terms of capacity expansion and data backup when facing a large amount of data. The Hadoop open-source cloud storage framework has the characteristics of high expansibility, high fault tolerance, economy and the like and strong computing power, and can provide technical support for the storage of real-time mass track data. The HBase is a NoSQL database which takes Hadoop as a basic technology and comprises a heartbeat mechanism of the HDFS, data backup and other core functions. In the aspect of storage, the HBase supports various data structures, can deal with mass data of PB level, and can be used for storing the mass data due to good expansibility.
Fig. 1 is a flowchart of a method for generating a thermodynamic diagram based on trajectory data, which is executed by a system with processing capability, a server, or a thermodynamic diagram generating device based on trajectory data according to an embodiment of the present invention. As shown in fig. 1, the method includes:
step 110, track data and map data are obtained.
The trajectory data is a sampling sequence with position and time information, and contains the space-time dynamics of the object to be researched. Based on the analysis of the trajectory data, a spatiotemporal distribution characteristic of the object under study may be obtained.
And step 120, storing the track data in the Hadoop platform distributed file system in an original format.
The original format of the track data is txt file. When the track data is stored into the HDFS, the track data is directly stored in the txt format without any processing on the format of the track data. Based on the process, the storage and management efficiency of the massive track data is improved, and the efficiency of generating the thermodynamic diagram is improved.
In some embodiments, storing trace data in native format in a Hadoop platform distributed file system, comprises: dividing the track data into a plurality of time slices, wherein each time slice comprises all track data in a preset time range; in the Hadoop platform distributed file system, the track data contained in the same time slice is stored in a centralized manner in an original format, and a plurality of time slices are stored adjacently according to a time sequence.
The HBase distributed database stores data in the form of tables. The table consists of rows and columns, the columns being divided into several column families. HBase is similar to NoSQL database, HBase is used as the primary Key for searching records by Row Key. When the data is stored, the data is stored according to the lexicographic order of the Row Key. Each column in the table belongs to a column family, and each column is composed of the minimum storage unit called a cell (cell), and the data in the cell is of no type and is stored in a byte code form. It is therefore necessary to pre-process the raw data before storing the data.
The method comprises the following steps of preprocessing original track data, wherein the process comprises the following steps: firstly storing the cluster data into an HDFS (Hadoop distributed file system) according to the original format, and then storing the cluster data into a warehouse according to rows by using HBase. The original track data storage mode is a storage mode based on time dimension, namely a storage mode with time attribute priority. By adopting the method, the spatial point clustering can be conveniently carried out, namely, the clustering analysis can be conveniently carried out on the track data, and the mining analysis of the track data based on time and space is facilitated. Other storage methods, such as a storage method based on vehicle trajectories, a storage method based on spatial distribution, and the like, cannot guarantee effective support of query conditions required for such analysis, because trajectory data in the same time period is not continuously stored on a storage device, which may cause a large number of IO to be generated, thereby reducing data access efficiency.
The embodiment of the invention uses a storage mode based on time dimension aiming at the original track data. Specifically, the time of all the track data is sequenced, then the track data is divided into a plurality of time slices, one time slice comprises all the track data in a preset time range, then the track data belonging to the same time slice is stored in a centralized mode, and all the time slices are arranged according to the time sequence, so that the track data are guaranteed to be stored adjacently in a storage space. For example, all track data within one day can be divided into one time slice every 1 hour, all track data within one day can be divided into 12 time slices, namely, track data between 0:00 and 1:00, track data between 1:00 and 2:00, ·, track data between 23:00 and 24:00, and then the track data contained in each time slice is centrally stored, and the track data between 0:00 and 1:00 and the track data between 1:00 and 2:00 are adjacently stored, and the track data between 1:00 and 2:00 and the track data between 2:00 and 3:00 are adjacently stored, so that the adjacent storage of all the 12 time slices in the time sequence is ensured.
Fig. 2 is a schematic diagram of a track data storage mode according to an embodiment of the present invention. In the HDFS, a data table (hereinafter referred to as a trajectory data table) is constructed for each time slice. In the trajectory data table, the column family may include the following: track data ID, track data longitude LAT, track data latitude LON, DATE DATE, TIME. cndot. the record format of a piece of track data can be: ID1, LAT1, LON1, DATE1, TIME. Each row in the table is used for storing a piece of track data, and all the track data contained in the time slice are arranged in the track data table according to the time sequence. Here, the trajectory data ID is used to indicate the subject to which the trajectory data belongs, for example, when the trajectory data is taxi trajectory data, the trajectory data ID is used to indicate which taxi the trajectory data comes from. That is, in the same trajectory data table, the trajectory data of the same time slice may be from different individuals of the study object, i.e., different taxis. More specifically, when storing trajectory data into the HDFS, the trajectory data is stored based only on the temporal attributes of the trajectory data, regardless of which subject individual the trajectory data is specifically generated by.
And step 130, clustering the track data to obtain clustered data.
The clustering analysis is generally a method for selectively extracting information from raw data according to set clustering parameters and conditions, and is commonly used for classifying and simplifying data.
In the step, the track data can be clustered, so that the position characteristics of the track data are kept, the data volume is reduced, and the efficiency of generating the thermodynamic diagram is improved. In addition, the track data are subjected to clustering analysis, and the thermonuclear phenomenon of a data dense area can be optimized, so that the visualization effect of the thermodynamic diagram is improved. According to the embodiment of the invention, the thermodynamic diagram is generated not by directly utilizing the original track data stored in the HDFS, but the track data is clustered, the clustered data is stored in the HBase distributed database, and the required clustered data is directly obtained from the HBase distributed database when the thermodynamic diagram is generated. Based on this process, the generation efficiency of the thermal map can be further improved.
In some embodiments, the map data has a plurality of zoom levels; clustering the track data to obtain clustered data, including: determining a plurality of groups of clustering parameters according to a plurality of zoom levels; and clustering the track data according to the multiple groups of clustering parameters to obtain multiple groups of clustering data corresponding to multiple zooming levels.
The existing thermodynamic diagrams are low in self-adaption effect, when the zoom levels are switched, the deformation of the position characteristics of the track data displayed by the thermodynamic diagrams is large, and the color gradients of the thermodynamic diagrams at different zoom levels are the same, so that a data dense area presents a thermonuclear phenomenon. Based on this, the embodiment of the invention sets different clustering parameters for different zoom levels of map data, so as to obtain a clustering result matched with the zoom levels, and further, according to the zoom levels of the thermodynamic diagrams required to be generated, corresponding clustering data is obtained for generating an actual thermodynamic diagram, the thermonuclear phenomenon of the generated thermodynamic diagrams in the data dense area is optimized, the position feature display is more detailed, and the visualization effect is improved.
Further, clustering the trajectory data to obtain clustered data, including: determining a plurality of groups of clustering parameters according to a plurality of zoom levels; and clustering the track data contained in each time slice according to the multiple groups of clustering parameters to obtain multiple groups of clustering data corresponding to multiple zoom levels for each time slice.
In some examples, each set of clustering parameters includes a scan radius; determining a plurality of groups of clustering parameters according to a plurality of zoom levels, comprising: determining a scanning radius corresponding to each zooming level according to the zooming levels; wherein the scan radius corresponding to each zoom level decreases as the respective zoom level decreases.
Each set of clustering parameters includes a scan radius. That is, when performing cluster analysis on trajectory data included in a certain time slice, trajectory data included in each cluster formed must be distributed within the range of the scan radius.
As the zoom level of the map data decreases, the number of tiles included in the map data decreases, and the spatial range of the real geographic space corresponding to a unit area in the map data increases, thereby causing the distribution of the trajectory data corresponding to the unit area in the map data to be denser. Therefore, when the zoom level is reduced, the scanning radius is reduced, so that the number of points contained in each cluster is reduced, the density of the track data in each cluster is reduced, the thermonuclear phenomenon of a local area is improved, and the position characteristics of the track data can be more accurately reflected by each cluster.
Specifically, the scanning radius corresponding to each zoom level may be determined according to a spatial range actually covered by a single pixel point in the map data at each zoom level in the real geographic space. In the map data of different zoom levels, the sizes of the individual pixel points are different. The lower the zoom level is, the smaller the size of a single pixel point is, the smaller the spatial range actually covered by the single pixel point in the real geographic space is, and conversely, the larger the size of the single pixel point is, the larger the spatial range actually covered by the single pixel point in the real geographic space is. For example, in a certain map data at a lower zoom level, the spatial range actually covered by a single pixel point in the real geographic space is only 300m, while in a map data at a higher zoom level, the spatial range actually covered by a single pixel point in the real geographic space is 1000 m. The spatial range actually covered by a single pixel point in the map data under each zoom level in the real geographic space can be directly used as the scanning radius corresponding to each zoom level. The spatial range actually covered by a single pixel point in the map data under each zoom level in the real geographic space can be adjusted to a certain extent as required, and the scanning radius corresponding to each zoom level is set. The embodiment of the present invention is not particularly limited to this.
In some examples, the sets of clustering parameters include a minimum contained point number; determining a plurality of groups of clustering parameters according to a plurality of zoom levels, further comprising: and determining the minimum contained points corresponding to each zooming level according to a plurality of zooming levels, wherein the minimum contained points corresponding to each zooming level are reduced along with the reduction of the corresponding zooming level.
Each set of clustering parameters includes a minimum contained point number. That is, when performing cluster analysis on trajectory data included in a certain time slice, the amount of trajectory data included in each cluster formed must be within the range of the minimum number of points included. It should be understood that when the scanning radius and the minimum inclusion point are used as the clustering parameters, the limitation of the scanning radius and the minimum inclusion point must be followed simultaneously in the clustering process.
As the zoom level of the map data decreases, the number of tiles included in the map data decreases, and the spatial range in the real geographic space corresponding to a unit area in the map data increases, thereby causing the distribution of the trajectory data corresponding to the unit area in the map data to be denser. Therefore, when the zoom level is reduced, the minimum number of points included is reduced, which is also beneficial to reducing the number of points included in each cluster, and reducing the density of the track data in each cluster, thereby improving the thermonuclear phenomenon of the local area, and enabling each cluster to reflect the position characteristics of the track data more accurately. The minimum number of points included corresponding to each zoom level may be set according to needs, which is not specifically limited in the embodiment of the present invention.
For any time slice, clustering the track data contained in the time slice based on the multiple groups of clustering parameters corresponding to the multiple zoom levels to obtain multiple groups of clustering data. In some embodiments, each set of cluster data includes a center coordinate and an influence value of a plurality of cluster clusters and a coordinate and an influence value of a plurality of noise points. Here, a noise point may be understood as a discrete point, i.e. individual trajectory data that is not included in any cluster. The noise points may also reflect the position distribution of the trajectory data, and therefore the noise points are taken into account when drawing the thermodynamic diagram.
In some examples, clustering of trajectory data is implemented based on DBScan algorithm. Common clustering algorithms include DBScan algorithm, K-means algorithm, etc. Through the comparison of different clustering algorithms, the DBScan algorithm has the following advantages: firstly, the requirement on the shape of a data set is low; abnormal points in the data can be found; and thirdly, the number of clusters after clustering does not need to be set. Therefore, based on the characteristic that the DBScan algorithm is suitable for a dense data set with any shape, the embodiment of the present invention selects the DBScan algorithm to cluster the trajectory data.
Specifically, for all trajectory data, the following process is adopted to realize clustering analysis:
(1) firstly, preprocessing all track data and eliminating abnormal points.
(2) And determining multiple groups of clustering parameters according to the multiple zooming levels, wherein the clustering parameters comprise scanning radius and minimum contained points.
(3) And clustering the track data contained in each time slice based on the DBScan algorithm. For any time slice, for multiple zoom levels, multiple sets of clustered data may be obtained. It is assumed that the cluster data corresponding to any one zoom level includes n cluster clusters and m noise points.
(4) For any one cluster, the coordinates (x, y) of the center point of the cluster and the value of influence count are calculated using the trajectory data contained in the cluster (see formula (1)). Since the noise points are all single coordinate points, the influence thereof can be directly assigned to 1.
Where n is the number of trace points in a cluster, xi、yiThe longitude and latitude of the ith trace point in the cluster.
And step 140, storing the map data and the cluster data in an HBase distributed database.
In some embodiments, storing the clustered data in an HBase distributed database includes: and respectively constructing each clustering data table aiming at each group of clustering data of each time slice corresponding to each zoom level. Based on this, when a thermodynamic diagram needs to be generated, the time range and the scaling level of the thermodynamic diagram can be determined, and then the clustering data table where the clustering data of the corresponding time slice corresponding to the scaling level is located is directly inquired from the HBase distributed database, so as to obtain the corresponding clustering data. Namely, the embodiment of the invention can improve the efficiency of acquiring the related clustering data from the HBase distributed database, thereby improving the efficiency of generating the thermodynamic diagram.
The storage pattern of the cluster data is shown in table 1. The table mainly stores information including the center coordinates of the clustered clusters after clustering, the influence values, and the coordinates and the influence values of the noise points. The Row Key is an integer arranged in sequence, the column family comprises 4 columns which are LAT, LNG, COUNT and procedure, the first three columns respectively store longitude and latitude and influence values, and the procedure column is used as an information supplement column to store other explanatory or auxiliary information.
TABLE 1 clustered data storage schema
The map data is generally raster data having a plurality of zoom levels, the map data at each zoom level is composed of a plurality of tiles, and the number of tiles is gradually increased as the zoom level is increased. In order to store and query the map data of each zoom level, the tiles in the map data of each zoom level need to be encoded according to a certain rule. In some embodiments, the tiles may be encoded in an order in which the tiles are naturally arranged in the display state of the map data. Fig. 3 is a schematic diagram of map data provided by an embodiment of the present invention in a display state. As shown in fig. 3, the map data is composed of 12 tiles coded 1-12, the tiles being coded sequentially from top to bottom and from left to right. According to the above coding, 12 tiles included in the map data are sequentially stored in the storage space, that is, the physical storage locations of the tiles having adjacent codes are adjacent to each other, and the physical storage locations of the tiles having non-adjacent codes are not adjacent. However, this encoding method affects the efficiency of reading the map data. As shown in fig. 3, the tiles in the screen display area (the area defined by the dashed box) are coded as 7, 8, 11 and 12, and the 4 tiles are adjacent in the screen display area but spaced at intervals in the physical storage location, in which case the time for querying and reading the data is increased, thereby affecting the efficiency of the thermodynamic diagram generation.
In order to reduce the query time, the physical storage locations of the tiles adjacent to each other in the display state need to be as close as possible, thereby reducing the data reading time and improving the efficiency. The map data adopted by the embodiment of the invention is the map tile data based on the quadtree model. Since the HBase distributed database adopts a column-oriented storage mode, 4 tiles adjacent to each other in a display state are stored in the same row. Specifically, the map data is stored in an HBase distributed database, which includes: and constructing each map data table aiming at the map data at each zoom level, and storing 4 tiles which are contained in the map data at each zoom level and are adjacent to each other in a display state into the same row in the corresponding map data table. Here, "adjacent to each other in the display state" means that 4 tiles are in an abutting relationship with each other, and it can also be considered that 4 tiles constitute a square area. For 4 tiles arranged in the same row in the lateral direction or 4 tiles arranged in the same column in the longitudinal direction in the map data, since these two cases are actually adjacent two by two, there is also a case where 2 tiles are spaced apart by other tiles, and therefore it does not belong to the case of "adjacent to each other in the display state".
In order to realize the ordered storage and the fast query of the map data, and to enable 4 tiles adjacent to each other in the display state to be stored in the same row in the corresponding map data table, the tiles included in the map data need to be encoded. In some examples, the process of encoding the tiles contained in the map data for each zoom level is as follows:
(1) calculating the total order m of the map data at each zoom level according to the number n of tiles contained in each row of the map data at each zoom level, wherein,
the right angle brackets indicate rounding up.
(2) And judging the relation between the number n of the tiles and the total order m. When n is 2m, the map data for each zoom level is divided into m square subgrids, where a square subgrid is made up of 4 tiles.
(3) And filling the m by m square sub-grids based on the Z-shaped filling curve. Here, each square subgrid may be filled based on the Z-shaped filling curves, and then the filling curves in each square subgrid are connected by using the connecting lines, so as to fill all the subgrids.
(4) The n tiles are encoded according to the filling order of the n tiles.
(5) And constructing each map data table aiming at the map data under each zoom level, and sequentially storing n tiles in the corresponding map data table based on the codes of the n tiles, wherein 4 tiles belonging to the same square sub-grid are stored in the same row in the corresponding map data table.
Fig. 4(a) is a schematic diagram illustrating an encoding method of time map data when n is 2 according to an embodiment of the present invention; fig. 4(b) is a schematic diagram of an encoding method of time chart data when n is 4 according to an embodiment of the present invention. As shown in fig. 4(a), when n is 2, m is 1, the map data is filled by a 1 st order Z-type filling curve, and the tiles are encoded according to the filling order. As shown in fig. 4(b), when n is 4, m is 2, the map data is filled by a 2-step Z-type filling curve, and the tiles are encoded according to the filling order.
Because the number of tiles in the screen display area may not meet the number required by the Z-shaped fill curve due to the limitation of the screen display area, the present embodiment provides an encoding method in the case that the number of tiles does not support the Z-shaped fill curve encoding. In some examples, the process of encoding the tiles contained in the map data for each zoom level is as follows:
(1) calculating the total order m of the map data at each zoom level according to the number n of tiles contained in each row of the map data at each zoom level, wherein,
the right angle brackets indicate rounding up.
(2) And judging the relation between the number n of the tiles and the total order m. When n-2m is 1, the map data at each zoom level is divided into m × m square subgrids and n edge subgrids, where a square subgrid is composed of 4 tiles, 2m edge subgrids adjacent to a square subgrid are composed of 2 tiles, and 1 edge subgrid not adjacent to a square subgrid is composed of 1 tile.
(3) Filling the m square sub-grids based on the Z-shaped filling curve, filling the 2m edge sub-grids based on the linear filling curve, connecting the m square sub-grids and the filling curves of the 2m edge sub-grids into a whole, and extending the filling curves of the m square sub-grids and the 2m edge sub-grids to 1 edge sub-grid which is not adjacent to the square sub-grids.
(4) The n tiles are encoded according to their filling order.
(5) And constructing each map data table aiming at the map data under each zoom level, and sequentially storing n tiles in the corresponding map data table based on the codes of the n tiles, wherein 4 tiles belonging to the same square sub-grid are stored in the same row in the corresponding map data table, and the tiles belonging to the same edge sub-grid are stored in the same row in the corresponding map data table.
Fig. 4(c) is a schematic diagram of an encoding flow of time map data when n is 3 according to an embodiment of the present invention. When n is 3, m is 1, that is, 1 sub-mesh of the map data may be filled by a 1-order Z-type filling curve, and other sub-meshes need to be filled in other manners. As shown in fig. 4(c), map data is first divided into 1 square subgrid and 3 edge subgrids, where 2 edge subgrids adjacent to the square subgrid (i.e., subgrids numbered 2 and 3) are composed of 2 tiles, and an edge subgrid not adjacent to the square subgrid (i.e., subgrid numbered 4) is composed of 1 tile; then, the square sub-grids are filled based on the Z-shaped filling curves, the sub-grids numbered 2 and 3 are filled based on the linear curves, then the square sub-grids and the filling curves of the 2 edge sub-grids are connected into a whole, and the square sub-grids and the filling curves of the 2 edge sub-grids continue to extend to the sub-grids numbered 4, so that all the sub-grids are filled; the tiles are encoded according to the filling order. Fig. 4(d) is a schematic diagram of an encoding method of time chart data when n is 3 according to an embodiment of the present invention. The encoding of the 9 tiles contained by the map data is shown in fig. 4 (d).
The storage mode of the map data provided by the embodiment of the invention is shown in table 2. In table 2, the master Key Row Key corresponds to the number of the sub-grids, and the number of the sub-grids is determined by the filling order of the sub-grids. The column family comprises at least four columns for storing tiles belonging to the same sub-grid and the storage order of the tiles is identical to the coding order of the tiles. Column names are named with tile numbers, and a query for a particular tile can be implemented according to the XY number of the tile. If any, the notes or other information are stored in the notes column of each table. Regarding the map data corresponding to fig. 4(c) and 4(d), the map data includes 4 sub-grids numbered 1, 2, 3, and 4, the master Key Row Key can be determined according to the numbers of the 4 sub-grids, and the tiles included in each sub-grid are respectively stored in the corresponding rows, wherein for the sub-grid numbered 1, 4 tiles encoded as 1, 2, 3, and 4 are sequentially stored in the same Row, for the sub-grid numbered 2, only 2 tiles encoded as 5 and 6 are included, then the 2 tiles are sequentially stored in the next Row, and for the sub-grid numbered 4, only 1 tile encoded as 9 is included, then the 1 tile is stored in a single Row.
TABLE 2 map data storage mode
It should be understood that, since the number of tiles included in the map data at different zoom levels may vary, the map data at each zoom level needs to be encoded separately, and finally, the map data at each zoom level is stored in its respective map data table according to the encoding. In this way, when the thermodynamic diagram is generated, the map data table of the map data at the corresponding zoom level is queried from the HBase distributed data, so that the map data at the corresponding zoom level can be obtained.
And 150, acquiring map data and cluster data corresponding to the thermodynamic diagram to be generated from the HBase distributed database.
In some embodiments, obtaining map data and cluster data corresponding to the thermodynamic diagram to be generated from the HBase distributed database includes: determining the zoom level of the map data corresponding to the thermodynamic diagram to be generated according to the zoom level of the thermodynamic diagram to be generated; and obtaining the map data and the cluster data under the corresponding zoom level from the HBase distributed database. Based on the method, the obtained clustering data is matched with the zoom level of the map data, so that the problem of large deformation of the position characteristics of the track data of the thermodynamic diagram under different zoom levels can be solved, and the thermonuclear phenomenon of the data dense area is optimized.
In some embodiments, obtaining map data and cluster data corresponding to the thermodynamic diagram to be generated from the HBase distributed database includes: determining the zoom level of the map data corresponding to the thermodynamic diagram to be generated according to the zoom level of the thermodynamic diagram to be generated; determining a time slice to which clustering data corresponding to the thermodynamic diagram to be generated belong according to the time range of the thermodynamic diagram to be generated; and obtaining the map data under the corresponding zoom level and the cluster data under the corresponding zoom level under the corresponding time slice from the HBase distributed database.
When the trajectory data included in each time slice is clustered, clustered data for the trajectory data included in each time slice can be obtained. When the thermodynamic diagram is drawn, besides the zoom level of the thermodynamic diagram, the time range of the thermodynamic diagram needs to be determined, and the time slice to which the clustering data belongs is determined based on the time range of the thermodynamic diagram.
And 160, generating a thermodynamic diagram according to the acquired map data and the cluster data.
In some embodiments, the cluster data includes a center coordinate and an influence value of the cluster and a coordinate and an influence value of the noise point. According to the influence values of the cluster and the noise points, the gray values of the areas covered by the cluster and the noise points can be calculated, and then the thermodynamic diagram can be generated on the map data by combining the central coordinates of the cluster and the noise points. Here, the gray value is determined based on the center coordinates and the influence value of the cluster and the coordinates and the influence value of the noise point, and the process of generating the thermodynamic diagram by combining the map data is realized by a conventional method in the field of thermodynamic diagram generation.
In summary, the embodiment of the present invention provides a thermodynamic diagram generation method based on trajectory data, which includes first acquiring trajectory data and map data; storing the track data in a Hadoop platform distributed file system in an original format; clustering the track data to obtain clustered data; storing the map data and the cluster data in an HBase distributed database; obtaining map data and clustering data corresponding to the thermodynamic diagram to be generated from the HBase distributed database; and generating a thermodynamic diagram according to the acquired map data and the cluster data. Based on the method and the device, the efficiency of thermodynamic diagram visualization can be improved while the position characteristics of the track data are kept, the diagram forming time is shortened, the problem of unsmooth caused by user interaction is solved, and the user experience is improved.
A specific implementation scenario is provided below to further illustrate the method for generating a thermodynamic diagram based on trajectory data according to an embodiment of the present invention.
Fig. 5 is a schematic diagram of a storage frame of track data and map data according to an embodiment of the present invention. As shown in fig. 5, the track data and map data storage frame constructed based on the HBase distributed database is composed of 5 parts in total. From bottom to top in sequence: 1) a Hadoop storage frame built by PC clusters; 2) an HBase cloud data storage layer depending on HDFS; 3) a data operation layer for querying data; 4) the Web service layer is used for receiving requests and calling data; 5) a Web browser based presentation layer. The system comprises an HBase cloud data storage layer, an HBase distributed database, an HDFS (Hadoop distributed file system) and a Hadoop storage frame, wherein the HBase cloud data storage layer is the HBase distributed database, the HBase distributed database is used for storing map data and clustering data, and the HDFS is constructed on the Hadoop storage frame and used for storing track data. The data operation layer is used for realizing the operation on the track data, the map data and the cluster data, and can comprise a map data processing module and a track data processing module, wherein the map data processing module comprises a map code conversion module and a map data interface, and the track data module comprises an original track data interface and a cluster data interface.
Specifically, the embodiment of the invention builds a Hadoop cluster formed by 5 computers, wherein the memory of each node is 8Gb, the hard disk is 1Tb, and the CPU is an i7 processor. The software configuration is that the Hadoop version is 2.7.6, the HBase version of the distributed database is 2.1.9, the zookeeper version of the coordination service is 3.4.14, the tomcat7.0.90 used by the web server is 7.0, and the Java version is 1.8.0.
The thermodynamic diagram of the embodiment of the invention visually selects the WebGIS visualization technology based on the B/S architecture, and the WebGIS can be understood as a GIS (Geographic Information System) based on the Web environment.
Fig. 6 is a flowchart of loading map data according to an embodiment of the present invention. The loading process of the map data is explained in conjunction with the storage frame of the trajectory data and the map data shown in fig. 5 and fig. 6. Firstly, a web browser judges the number of a required tile according to a screen display area, namely, determines a query condition, and sends a request to a web map server, the web map server converts the tile number into a code required for querying an HBase cloud data storage layer through a map code conversion module, namely, a Row Key, interacts with the HBase cloud data storage layer through a map data interface, queries a corresponding map data table according to the Row Key, determines a cell where the tile is located through the tile number, and then returns the queried map data to the web map server. Accordingly, the acquisition process of the map data necessary for the thermodynamic diagram to be generated is realized.
The map data used in the embodiment of the invention is 18-level (namely 18 zoom levels) map data in the Beijing area. And selecting map data of one zoom level to perform high-pressure query test so as to investigate the loading efficiency of the map data. Fig. 7 is a comparison diagram of loading durations of map data according to an embodiment of the present invention, where two loading time curves in fig. 7 are respectively loading time curves of map data for two encoding manners, a first encoding manner is to encode the map data based on the purpose that 4 tiles adjacent to each other are stored in the same row in a corresponding map data table in the display state (e.g., the encoding manners illustrated in fig. 4(a) to 4 (d)), and a second encoding manner is to encode the tiles according to the order in which the tiles are naturally arranged in the display state of the map data (e.g., the encoding manner illustrated in fig. 3). Since the encoding method for the map data determines the storage method for the map data, the loading time comparison shown in fig. 7 is actually a comparison of the loading efficiency of the map data for the two storage methods.
As can be seen from fig. 7, when the number of requests is small, the difference between the loading times of the map data of the two encoding methods is not large, but the difference between the two encoding methods becomes more and more obvious as the number of requests is increased. The map data are encoded based on the purpose that 4 tiles adjacent to each other in the display state are stored in the same row in the corresponding map data table, the time consumed after 100 times of loading is less than 2000ms, namely, about 50 times of complete loading processes can be completed per second on average, and high concurrency scenes generated in visual interaction can be dealt with. Therefore, after the encoding processing, the whole average loading time shows a shortening trend from the time of sending the request to the HBase distributed database to the time of returning the data to the Web browser end, and the real-time loading rate is relatively stable.
The following provides yet another specific implementation scenario to further illustrate the method for generating a thermodynamic diagram based on trajectory data according to an embodiment of the present invention.
The embodiment of the invention builds a Hadoop cluster consisting of 5 computers, wherein the memory of each node is 8Gb, the hard disk is 1Tb, and the CPU is an i7 processor. The software configuration is that the Hadoop version is 2.7.6, the HBase version of the distributed database is 2.1.9, the zookeeper version of the coordination service is 3.4.14, the tomcat7.0.90 used by the web server is 7.0, and the Java version is 1.8.0.
The thermodynamic diagram of the embodiment of the invention visually selects the WebGIS visualization technology based on the B/S architecture, and the WebGIS can be understood as a GIS (Geographic Information System) based on the Web environment.
The map data used in the embodiment of the invention is 18-level map data (namely, 18-level zoom level) in the Beijing area. The track data is 24 hours of track data of a taxi in Beijing city, and about 1440 records are totally recorded. And randomly selecting track data of a certain time slice for visualization processing.
Fig. 8 is a flowchart of a thermodynamic diagram generation method based on trajectory data according to an embodiment of the present invention. The generation process of the thermal map will be described with reference to fig. 6 and 8, which are storage frames of the trajectory data and the map data shown in fig. 5. In which map data is first loaded based on the loading process of map data shown in fig. 6. The process is the same as the map data loading process in the previous implementation scenario, and the embodiment of the present invention is not described herein again. The loaded map data is map data which is encoded for the purpose of storing 4 tiles adjacent to each other in the display state in the same row in the corresponding map data table and stored in the HBase distributed database based on the encoding manner. Thereafter, a thermodynamic diagram is drawn in conjunction with the acquired cluster data and map data based on the visualization process shown in fig. 8. Specifically, taxi track data are stored in the HDFS, and then are clustered based on the DBSCAN algorithm. And aiming at the cluster and the noise point obtained by clustering, calculating the central coordinate and the influence value of the cluster and the influence value of the noise point in a mode of traversing all the cluster and the noise point one by one, and storing the cluster data into a warehouse after the calculation is finished. Here, each time the clustering parameter is changed, a new round of clustering is performed on the trajectory data, and a new round of traversal is performed on the newly obtained cluster and the noise point to obtain new cluster data, so that cluster data suitable for each zoom level can be obtained from a plurality of zoom levels of the map data. And when the data to be clustered is put into a warehouse, the loading process of the clustered data can be executed according to the requirement generated by the thermodynamic diagram, a data request is sent to the web browser, and the web map server inquires corresponding data from the HBase distributed database according to the inquiry condition and returns the data to the web browser. And the Web browser end calculates the gray value according to the influence value of the clustering data and draws a thermodynamic diagram. In order to distinguish from the thermodynamic diagram generation process utilizing the clustering data, the embodiment of the invention also provides a thermodynamic diagram generation process based on the original track data. Here, when generating the thermodynamic diagram based on the original trajectory data, the original trajectory data is directly acquired from the HDFS, and the thermodynamic diagram is drawn based on the original trajectory data and the loaded map data.
FIG. 9(a) is a thermodynamic diagram generated using map data at zoom level 11 and raw trajectory data without clustering provided by an embodiment of the present invention; FIG. 9(b) is a thermodynamic diagram generated using map data at zoom level 11 and cluster data provided by an embodiment of the present invention; FIG. 9(c) is a thermodynamic diagram generated using map data at zoom level 12 and raw trajectory data without clustering provided by yet another embodiment of the present invention; FIG. 9(d) is a thermodynamic diagram generated using map data at zoom level 12 and cluster data provided by an embodiment of the present invention; FIG. 9(e) is a thermodynamic diagram generated using map data at zoom level 13 and raw trajectory data without clustering provided by an embodiment of the present invention; FIG. 9(f) is a thermodynamic diagram generated using map data at zoom level 13 and cluster data provided by an embodiment of the present invention; FIG. 9(g) is a thermodynamic diagram generated using map data at zoom level 14 and raw trajectory data without clustering provided by an embodiment of the present invention; fig. 9(h) is a thermodynamic diagram generated by using map data with a zoom level of 14 and cluster data according to an embodiment of the present invention. "zoom" denoted in fig. 9(a) to 9 (h): the "typeface represents the zoom level of the thermodynamic diagram, and the time typeface represents the time it takes to generate the thermodynamic diagram. Here, for the thermodynamic diagram generation process using the cluster data, the time taken to complete the following process is taken as the time taken to generate the thermodynamic diagram: and the Web browser end sends a data request, the Web map service end queries corresponding data from the HBase distributed database according to the query conditions and returns the data to the Web browser end, and the Web browser end calculates a gray value according to the influence value of the clustered data and draws a thermodynamic diagram. For the thermodynamic diagram generation process directly using raw track data without clustering, the time taken to complete the following process is taken as the time taken to generate the thermodynamic diagram: and the Web browser sends a data request, the Web map service end inquires corresponding data in the HDFS according to the inquiry condition and returns the data to the Web browser, and the Web browser draws a thermodynamic diagram according to the acquired original track data.
Two thermodynamic diagrams with the same zoom level are compared as a group, namely, fig. 9(a) and 9(b), fig. 9(c) and 9(d), fig. 9(e) and 9(f), and fig. 9(g) and 9(h) respectively form 4 groups, and it is found from the comparison result of each group that the thermonuclear phenomenon of the thermodynamic diagram generated by using the original trajectory data without clustering is more serious, the deformation of the position feature is larger, the generation time of the thermodynamic diagram is longer, and the visualization effect is poorer, and correspondingly, the thermonuclear phenomenon of the data dense region is optimized, the display of the position feature is more detailed, and the overall visualization effect is improved by using the thermodynamic diagram generated by clustering data. Especially, when the thermodynamic diagram is generated by utilizing the cluster data, different cluster parameters are designed aiming at different zoom levels, and the obtained cluster data is adaptive to the zoom levels of the map data, so that the method is more favorable for improving the thermonuclear phenomenon of the data dense area. Fig. 10 is a comparison graph of the generation duration of the thermodynamic diagram provided by the embodiment of the invention. As can be seen from fig. 10, when the zoom level is low, such as 11 levels and 12 levels, there is a certain difference between the time length consumed by using the original trajectory data without clustering processing and the time length consumed by using the clustering data to generate the thermodynamic diagram, and in the case of a higher zoom level, the visualized loading time of the clustering data is significantly reduced.
In summary, the thermodynamic diagram generation method based on the trajectory data provided by the embodiment of the invention improves visualization efficiency, shortens mapping time, reduces the jamming influence caused by user interaction, and improves user interaction experience while preserving data position characteristics. The thermodynamic diagram generation method based on the track data provided by the embodiment of the invention can realize efficient management and storage of mass track data and obtain a better drawing effect.
In addition, the thermodynamic diagram generation method based on the track data provided by the embodiment of the invention is based on the advantages of high reliability, high expansibility, high efficiency, high fault tolerance and the like of a hadoop framework, and a track big data storage scheme based on an HBase platform is designed, so that the thermodynamic diagram generation method based on the track data has better universality in the fields of space data storage, visualization and expansion. By processing the thermodynamic diagram data, the generation efficiency of the thermodynamic diagram is improved, and key technical support is provided for track data mining and analysis based on time attributes.
Fig. 11 shows a schematic structural diagram of a thermodynamic diagram generation apparatus based on trajectory data according to an embodiment of the present invention. As shown in fig. 11, the trajectory-data-based thermodynamic diagram generation apparatus 1100 includes: a first obtaining module 1110, configured to obtain track data and map data; the first storage module 1120 is used for storing the track data in a Hadoop platform distributed file system in an original format; a clustering module 1130, configured to cluster the trajectory data to obtain clustered data; a second storage module 1140, configured to store the map data and the cluster data in an HBase distributed database; a second obtaining module 1150, configured to obtain map data and cluster data corresponding to the thermodynamic diagram to be generated from the HBase distributed database; a generating module 1160, configured to generate a thermodynamic diagram according to the acquired map data and cluster data.
In some embodiments, the first storage module is specifically configured to: dividing the track data into a plurality of time slices, wherein each time slice comprises all track data in a preset time range; in the Hadoop platform distributed file system, the track data contained in the same time slice is stored in a concentrated mode in an original format, and the time slices are stored adjacently according to a time sequence.
In some embodiments, the map data has a plurality of zoom levels; the clustering module comprises: a first determining unit, configured to determine multiple groups of clustering parameters according to the multiple zoom levels; the clustering unit is used for clustering the track data contained in each time slice according to the multiple groups of clustering parameters to obtain multiple groups of clustering data corresponding to the multiple zoom levels for each time slice; the second obtaining module includes: a second determining unit, configured to determine, according to a zoom level of the thermodynamic diagram to be generated, a zoom level of map data corresponding to the thermodynamic diagram to be generated; a third determining unit, configured to determine, according to the time range of the thermodynamic diagram to be generated, a time slice to which cluster data corresponding to the thermodynamic diagram to be generated belongs; and the acquisition unit is used for acquiring the map data at the corresponding zoom level and the cluster data at the corresponding zoom level in the corresponding time slice from the HBase distributed database.
In some embodiments, the map data has a plurality of zoom levels; the clustering module comprises: a first determining unit, configured to determine multiple groups of clustering parameters according to the multiple zoom levels; the clustering unit is used for clustering the track data according to the multiple groups of clustering parameters to obtain multiple groups of clustering data corresponding to the multiple zooming levels; the second obtaining module includes: a second determining unit, configured to determine, according to a zoom level of the thermodynamic diagram to be generated, a zoom level of map data corresponding to the thermodynamic diagram to be generated; and the acquisition unit is used for acquiring the map data and the cluster data under the corresponding zoom level from the HBase distributed database.
In some embodiments, the sets of clustering parameters include a scan radius; the first determining unit is specifically configured to: determining a scanning radius corresponding to each zooming level according to the zooming levels; wherein the scan radius corresponding to each zoom level decreases as the respective zoom level decreases.
In some embodiments, the sets of clustering parameters include a minimum inclusion point number; the first determining unit is specifically configured to: and determining the minimum contained points corresponding to each zooming level according to the zooming levels, wherein the minimum contained points corresponding to each zooming level are reduced along with the reduction of the corresponding zooming level.
In some embodiments, the sets of cluster data include center coordinates and influence values of a plurality of cluster clusters and coordinates and influence values of a plurality of noise points.
In some embodiments, the clustering is implemented based on a DBScan algorithm.
In some embodiments, the second storage module comprises: and the first construction unit is used for constructing each clustering data table aiming at each group of clustering data corresponding to each zooming level of each time slice.
In some embodiments, the map data has a plurality of zoom levels; the second storage module includes: and the second construction unit is used for constructing each map data table aiming at the map data at each zoom level and storing 4 tiles which are adjacent to each other in the display state and are contained in the map data at each zoom level in the same row of the corresponding map data table.
In some embodiments, the second building unit is specifically configured to: calculating the total order m of the map data at each zoom level according to the number n of tiles contained in each row of the map data at each zoom level, wherein,
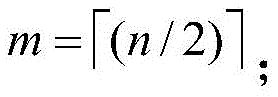
when n-2m is 1, dividing the map data at each zoom level into m × m square sub-grids and n edge sub-grids, wherein the square sub-grids are composed of 4 tiles, 2m edge sub-grids adjacent to the square sub-grids are composed of 2 tiles, and 1 edge sub-grid not adjacent to the square sub-grids is composed of 1 tile; filling the m-by-m square sub-grids based on a Z-shaped filling curve, filling the 2m edge sub-grids based on a linear filling curve, and connecting the m-by-m square sub-grids and the n edge sub-grids by using connecting lines; encoding the n tiles according to their filling order; and constructing each map data table aiming at the map data under each zoom level, and sequentially storing the n tiles in the corresponding map data table based on the codes of the n tiles, wherein 4 tiles belonging to the same square sub-grid are stored in the same row in the corresponding map data table, and the tiles belonging to the same edge sub-grid are stored in the same row in the corresponding map data table.
In some embodiments, the second building unit is specifically configured to: calculating the total order m of the map data at each zoom level according to the number n of tiles contained in each row of the map data at each zoom level, wherein,
when n is 2m, dividing the map data of each zoom level into m square sub-grids, wherein the square sub-grids are composed of 4 tiles; filling the m by m square sub-grids based on a Z-shaped filling curve; encoding the n tiles according to their filling order; and constructing each map data table aiming at the map data under each zoom level, and sequentially storing the n tiles in the corresponding map data table based on the codes of the n tiles, wherein 4 tiles belonging to the same square sub-grid are stored in the same row in the corresponding map data table.
Fig. 12 shows an electronic device of an embodiment of the invention. As shown in fig. 12, the electronic apparatus 1200 includes: at least one processor 1210, and a memory 1220 in communication with the at least one processor 1210, wherein the memory stores instructions executable by the at least one processor to cause the at least one processor to perform the method.
Specifically, the memory 1220 and the processor 1210 are connected together via the bus 1230, and can be general-purpose memory and processor, which are not limited in particular, and when the processor 1210 executes the computer program stored in the memory 520, the operations and functions described in the embodiments of the present invention in conjunction with fig. 1 to 10 can be performed.
An embodiment of the present invention further provides a storage medium, on which a computer program is stored, which, when executed by a processor, implements the method. For specific implementation, reference may be made to the method embodiment, which is not described herein again.
While embodiments of the present invention have been disclosed above, it is not limited to the applications listed in the description and the embodiments. It is fully applicable to a variety of fields in which embodiments of the present invention are suitable. Additional modifications will readily occur to those skilled in the art. Therefore, the embodiments of the invention are not to be limited to the specific details and illustrations shown and described herein, without departing from the general concept defined by the claims and their equivalents.