Disclosure of Invention
A primary object of the present disclosure is to provide a method, an apparatus, a storage medium and an electronic device for generating a video, so as to solve the problems in the prior art.
In order to achieve the above object, according to a first aspect of embodiments of the present disclosure, there is provided a method of generating a video, the method including:
inputting the three primary color images of the source view into a depth and semantic network to obtain a depth image and a semantic image output by the depth and semantic network;
inputting the semantic graph and the three primary color images into a feature encoder network to obtain a feature graph output by the feature encoder network;
for each pose transformation matrix in a plurality of continuous pose transformation matrices of the source view, respectively transforming the semantic graph and the feature graph according to the pose transformation matrix and the depth map to obtain a target semantic graph and a target feature graph corresponding to each pose transformation matrix, wherein the plurality of continuous pose transformation matrices are respective pose transformation matrices of the source view relative to a plurality of continuous image frames;
respectively generating image frames according to a target semantic graph and a target characteristic graph corresponding to each pose transformation matrix to obtain a plurality of continuous image frames, wherein each image frame and the source view are images of the same object from different visual angles;
and synthesizing the plurality of continuous image frames into a video.
Optionally, the transforming, for each pose transformation matrix of a plurality of consecutive pose transformation matrices of the source view, the semantic map and the feature map according to the pose transformation matrix and the depth map respectively includes:
calculating the coordinate of each pixel in the first image frame by the following formula respectively aiming at each pixel in the feature map and the semantic map:
[pt]=dK[R|t]K-1[ps]
[R|t]=[Rs|ts]-1[Rt|tt]
where d represents the depth value at the pixel in the depth map, K represents the camera's internal parameters, [ R | t [ ]]A pose transformation matrix representing the source view relative to the first image frame, R representing rotation, t representing translation, [ R ] Rs|ts]、[Rt|tt]Respectively representing the poses of the camera under the source view and the first image frame in a world coordinate system, psRepresenting the coordinates of the pixel under the source view, ptRepresenting the coordinates under the first image frame.
Optionally, the generating image frames according to the target semantic map and the target feature map corresponding to each pose transformation matrix respectively includes:
performing optimization processing according to the target semantic graph and the target characteristic graph corresponding to each pose transformation matrix, wherein the optimization processing comprises the following steps: hole filling and distortion correction;
and respectively generating the image frames according to the optimized target semantic graph and the optimized target characteristic graph corresponding to each pose transformation matrix.
Optionally, the generating image frames according to the target semantic map and the target feature map corresponding to each pose transformation matrix respectively to obtain a plurality of continuous image frames includes:
and aiming at the target semantic graph and the target characteristic graph corresponding to each pose transformation matrix, inputting the target semantic graph and the target characteristic graph into a generator network in a generation countermeasure network to obtain the image frame corresponding to the pose transformation matrix.
Optionally, the generating a loss function for the countermeasure network is:
wherein λ is
FFor overriding, for controlling feature matching loss
Of importance, λ
WThe method is a super-ginseng method,
representing image loss in an image discriminator network, the loss function of the image discriminator network being:
representing image loss in a video discriminator network, the loss function of the video discriminator network being:
and, the function of the feature matching penalty is:
wherein G represents a generator network, D represents a discriminator network, D
kRepresenting a multi-scale network of discriminators, k representing the number of said multi-scale network of discriminators, D
1,D
2The multi-scale discriminator networks representing two different scales respectively,
representing a kth of the multi-scale discriminator networks in the image discriminator network,
representing the kth multi-scale discriminator network in the video discriminator network, s representing a source view, x representing a target view, N representing the number of layers of a perceptron, N representing the number of layers of a perceptron
iRepresents the number of elements of each layer,
multi-scale discriminator network D corresponding to characteristic extractor of representative i-th layer
k,|| ||
1Representing a 1 norm, GAN representing the generation of a countermeasure network;
represents the optical flow loss, the function of which is:
where T represents the number of image sequences, w
t、
Respectively representing the real and predicted optical flows, x, between the t-th and t + 1-th frames of the image sequence
t+1An image representing a t +1 frame,
representing combined optical flow information, x
tFrame image mapping to x
t+1An image corresponding to the frame;
the training to generate the countermeasure network is an alternating training that maximizes and minimizes the loss function by:
according to a second aspect of the embodiments of the present disclosure, there is provided an apparatus for generating a video, the apparatus comprising:
the first acquisition module is used for inputting the three primary color images of the source view into a depth and semantic network to obtain a depth image and a semantic image output by the depth and semantic network;
the second acquisition module is used for inputting the semantic graph and the three primary color images into a feature encoder network to obtain a feature graph output by the feature encoder network;
a transformation module, configured to transform, for each pose transformation matrix of multiple consecutive pose transformation matrices of the source view, the semantic graph and the feature graph according to the pose transformation matrix and the depth map, so as to obtain a target semantic graph and a target feature graph corresponding to each pose transformation matrix, where the multiple consecutive pose transformation matrices are respective pose transformation matrices of the source view with respect to multiple consecutive image frames;
the generating module is used for respectively generating image frames according to the target semantic graph and the target characteristic graph corresponding to each pose transformation matrix to obtain a plurality of continuous image frames, wherein each image frame and the source view are images of the same object from different visual angles;
and the synthesis module is used for synthesizing the plurality of continuous image frames into a video.
Optionally, the transformation module comprises:
a calculating submodule, configured to calculate, for each pixel in the feature map and the semantic map, a coordinate of the pixel in the first image frame by using the following formula:
[pt]=dK[R|t]K-1[ps]
[R|t]=[Rs|ts]-1[Rt|tt]
where d represents the depth value at the pixel in the depth map, K represents the camera's internal parameters, [ R | t [ ]]A pose transformation matrix representing the source view relative to the first image frame, R representing rotation, t representing translation, [ R ] Rs|ts]、[Rt|tt]Respectively representing the poses of the camera under the source view and the first image frame in a world coordinate system, psRepresenting the coordinates of the pixel under the source view, ptRepresenting the coordinates under the first image frame.
Optionally, the generating module includes:
the optimization submodule is used for carrying out optimization processing according to the target semantic graph and the target characteristic graph corresponding to each pose transformation matrix, and the optimization processing comprises the following steps: hole filling and distortion correction;
and the first generation submodule is used for respectively generating the image frames according to the optimized target semantic graph and the optimized target characteristic graph corresponding to each pose transformation matrix.
Optionally, the generating module further includes:
and the second generation submodule is used for inputting the target semantic graph and the target characteristic graph corresponding to each pose transformation matrix into a generator network in a countermeasure network to obtain the image frame corresponding to the pose transformation matrix.
Optionally, the generating a loss function for the countermeasure network is:
wherein λ is
FFor overriding, for controlling feature matching loss
Of importance, λ
WThe method is a super-ginseng method,
representing image loss in an image discriminator network, the loss function of the image discriminator network being:
representing image loss in a video discriminator network, the loss function of the video discriminator network being:
and, the function of the feature matching penalty is:
wherein G represents a generator network, D represents a discriminator network, D
kRepresenting a multi-scale network of discriminators, k representing the number of said multi-scale network of discriminators, D
1,D
2The multi-scale discriminator networks representing two different scales respectively,
representing a kth of the multi-scale discriminator networks in the image discriminator network,
representing the kth multi-scale discriminator network in the video discriminator network, s representing a source view, x representing a target view, N representing the number of layers of a perceptron, N representing the number of layers of a perceptron
iRepresents the number of elements of each layer,
multi-scale discriminator network D corresponding to characteristic extractor of representative i-th layer
k,|| ||
1Representing a 1 norm, GAN representing the generation of a countermeasure network;
represents the optical flow loss, the function of which is:
where T represents the number of image sequences, w
t、
Respectively representing the real and predicted optical flows, x, between the t-th and t + 1-th frames of the image sequence
t+1An image representing a t +1 frame,
representing combined optical flow information, x
tFrame image mapping to x
t+1An image corresponding to the frame;
the generation of a countermeasure networkIs an alternating training that maximizes and minimizes the loss function by the following formula:
according to a third aspect of embodiments of the present disclosure, the present disclosure also provides a computer-readable storage medium having stored thereon computer program instructions which, when executed by a processor, implement the steps of the method of the first aspect of the present disclosure.
According to a fourth aspect of the embodiments of the present disclosure, there is provided an electronic apparatus including:
a memory having a computer program stored thereon;
a processor for executing the computer program in the memory to implement the steps of the method of the first aspect of the disclosure.
By adopting the technical scheme, the semantic graphs and the feature graphs of the source view are geometrically transformed through the continuous pose sequence and the depth graphs corresponding to the source view, so that a plurality of continuous target semantic graphs and a plurality of continuous target feature graphs can be respectively obtained, and then the plurality of target semantic graphs and the corresponding target feature graphs are respectively synthesized into a plurality of continuous image frames. And then these successive image frames are combined into a video. By adopting the method, the three-dimensional structure of the invisible area can be deduced by utilizing the depth map, the semantic map and the characteristic map of the source view, and the real texture of the invisible area is kept, so that the generated image frame is clearer and more vivid. Therefore, the video generated by the method is more vivid and has better stability.
Additional features and advantages of the disclosure will be set forth in the detailed description which follows.
Detailed Description
The following detailed description of specific embodiments of the present disclosure is provided in connection with the accompanying drawings. It should be understood that the detailed description and specific examples, while indicating the present disclosure, are given by way of illustration and explanation only, not limitation.
Reference will now be made in detail to the exemplary embodiments, examples of which are illustrated in the accompanying drawings. When the following description refers to the accompanying drawings, like numbers in different drawings represent the same or similar elements unless otherwise indicated. The implementations described in the exemplary embodiments below are not intended to represent all implementations consistent with the present disclosure. Rather, they are merely examples of apparatus and methods consistent with certain aspects of the present disclosure, as detailed in the appended claims.
It is noted that the terms "first," "second," and the like in the description and claims of the present disclosure and in the above-described drawings are used for distinguishing between similar elements and not necessarily for describing a particular sequential or chronological order.
In order to make the technical solutions provided by the embodiments of the present disclosure easier for those skilled in the art to understand, a brief description of related concepts related to the present disclosure is provided below.
Computer vision refers to the simulation of biological vision using a computer and related equipment. The main task of the method is to process the collected pictures or videos to obtain the three-dimensional information of the corresponding scene. Furthermore, the method uses a camera and a computer to replace the machine vision of human eyes for identifying, tracking and measuring the target, and further performs graphic processing, so that the computer processing becomes an image more suitable for human eyes to observe or is transmitted to an instrument to detect.
The viewing angle is an angle formed by a line of sight and a vertical direction of the display or the like. Specifically, when observing an object, the included angle formed by the light rays led out from two ends (upper, lower, left and right) of the object at the optical center of human eyes.
The variable-view image refers to an image of a three-dimensional scene mapped by different views for the same three-dimensional scene.
The three primary color image is an RGB (Red Green Blue, RGB for short) image, which is an image composed of three color channels of Red, Green, and Blue.
A depth map, also called a distance image, is an image in which the distance (depth) from an image pickup to each point in a scene is defined as a pixel value. It directly reflects the geometry of the visible surface of the scene in the scene, i.e. the depth image is a three-dimensional representation of the object.
The semantic graph refers to a machine which automatically segments and identifies the content in an image. In particular, different objects in the image are segmented from the pixel level, and the object represented by the segmented objects is classified, positioned and detected in the image.
Feature maps, data exists in three dimensions in each convolutional layer in a convolutional neural network. It can be viewed as a stack of a number of two-dimensional pictures, each of which is referred to as a feature map. That is, the description of the image from various angles in each layer of the convolutional neural network, specifically, the scrolling operation on the image with different convolutional kernels, obtains the response on different kernels (the kernels can be understood as the above description) as the features of the image. That is, the feature map is the result of the convolution kernel rolling out.
And the pose refers to the position and the posture of an object in the image in a specified coordinate system, and describes the relative position and the relative running track of the object. Images at different viewing angles have different poses.
The hole refers to an area where no value or extreme value of a pixel appears after the image is processed. For example, a pixel point set in a closed circle formed by eight connected lattices in the binary image.
The bilinear interpolation method is also called a bilinear interpolation method, and performs linear interpolation by using pixel values of 4 adjacent points and giving different weights according to the distance from the pixel values to an interpolation point. The method has an averaged low pass filtering effect, and the edges are smoothed to produce a relatively coherent output image.
Resampling refers to a process of interpolating information of one type of pixel according to information of another type of pixel. Is an image data processing method. I.e. a gray scale processing method in the process of reorganizing the image data. The image sampling is to collect the image gray value according to a certain interval, when the threshold value is not located on the value of the original function of the sampling point, the interpolation is needed by using the sampling point, which is called resampling.
Pre-training refers to a model that is pre-trained or refers to a process of pre-training a model.
Robustness refers to the characteristic that the control system maintains certain other performances under certain (structure and size) parameter perturbation.
Stability, refers to the ability of the control system to return to its original equilibrium state after the effects of the disturbance that caused it to move away from equilibrium have disappeared.
The space-time consistency has the characteristic of consistency in time and space.
The prediction of optical flow is a method that uses the change of the pixels of the images in the image sequence in the time domain and the correlation between adjacent frames to find the corresponding relationship existing between the previous frame and the current frame, thereby calculating the motion information of the object between the adjacent frames.
An embodiment of the present disclosure provides a method for generating a video, as shown in fig. 1, the method includes:
s101, inputting the three primary color images of the source view into a depth and semantic network to obtain a depth image and a semantic image output by the depth and semantic network.
And processing the source view by using the pre-trained depth and semantic network to obtain a semantic map and a depth map corresponding to the source view. Specifically, the source view is semantically segmented and depth predicted using a pre-trained semantic segmentation and depth prediction network, wherein the semantic segmentation and depth prediction network may be a depth neural network, for example, a convolutional neural network.
Illustratively, the source view is input into the depth and semantic network, the image is convolved by a 3 × 3 convolution kernel, and the convolution kernel outputs two-dimensional data of a new image. It is also worth mentioning that processing the image using different convolution kernels of the same size can extract different features of the image, such as contours, colors, textures, etc. The new two-dimensional information is then input into the next convolutional layer for processing. After the convolutional layer, data is input into the fully-connected layer, the fully-connected layer outputs a one-dimensional vector, and the one-dimensional vector represents the probability that the object in the image is the object in the object classification in the network, so that through semantic segmentation processing of the network, the object in the image can be known to represent what objects respectively according to the one-dimensional vector output by the fully-connected layer. The semantic graph can be obtained. For example, if there is a person riding a motorcycle in the input image, after semantic segmentation, the person and the motorcycle can be segmented, and the region where the person is located in the image is labeled as a person and the region where the motorcycle is located is labeled as a motorcycle. For another example, if there are two people in the input image, one of the two people rides a motorcycle, and after semantic segmentation, the region where the two people are located in the image is labeled as a person, and the region where the motorcycle is located is labeled as a motorcycle. In one possible implementation, the person riding the motorcycle may also be labeled as person 1 and the other person as person 2.
It should be noted that the source view in step S101 may be an image frame of any one of the videos captured by the camera, or may be a single image captured by the camera.
In addition, the source view is input into the depth and semantic network, and a depth map corresponding to the image can be obtained. The depth image reflects depth information of the scene in the image. By obtaining the depth value of each pixel, the distance from each point in the scene to the camera plane can be known, and therefore, the depth map can directly reflect the geometric shape information of the visible surface of the scene in the scene. Furthermore, due to the dense image pixel points, the three-dimensional information of the object in the invisible area can be estimated according to the dense depth map information.
S102, inputting the semantic graph and the three primary color images into a feature encoder network to obtain a feature graph output by the feature encoder network.
In order to make the generated target image frame have temporal and spatial continuity with the source view, in other words, in order to make the generated image maintain the original features of all scenes in the source view, such as shape features, color features, texture features, spatial relationship features, etc., a feature encoder network may be used to extract the features in the source view. Wherein the color features describe surface properties of the scene to which the image or image region corresponds; the shape features are divided into two types, one is a contour feature, the other is a region feature, the contour feature of the image mainly aims at the outer boundary of the object, and the region feature of the image is related to the whole shape region; the spatial relationship characteristic refers to the mutual spatial position or relative direction relationship among a plurality of scenes segmented from the image, and these relationships can also be classified into a connection or adjacency relationship, an overlapping or overlapping relationship, an inclusion or inclusion relationship, and the like.
It should be noted that the features extracted by using the feature encoder may be low-dimensional vectors or high-dimensional vectors, in other words, the features may be bottom-layer features or high-layer features, which is not limited in this disclosure. Specifically, the image features of the bottom layer, i.e., the edge information represented by the low-dimensional vectors, are obtained by a feature encoder, and then feature combination is performed to obtain the image features of the upper layer, i.e., the high-layer feature information represented by the high-dimensional vectors. By means of feature extraction, the feature map can keep the real features of the source image.
Therefore, in step S102, by inputting the three primary color images of the semantic graph and the source view into the feature encoder network, a feature graph of the three primary color image can be obtained, which maintains the original feature information of each instance in the semantic graph, wherein an instance refers to an independent individual, for example, the above-mentioned person 1 and person 2 can be two instances respectively.
S103, aiming at each pose transformation matrix in a plurality of continuous pose transformation matrixes of the source view, respectively transforming the semantic graph and the feature graph according to the pose transformation matrix and the depth map to obtain a target semantic graph and a target feature graph corresponding to each pose transformation matrix.
Wherein the plurality of successive pose transformation matrices are respective pose transformation matrices of the source view relative to the plurality of successive image frames, in other words the plurality of successive pose transformation matrices are pose transformation matrices of the plurality of target views relative to the source view, and the successive pose transformation matrices may be user input. And respectively transforming the semantic graph and the characteristic graph of the source view according to each pose transformation matrix in the plurality of continuous pose transformation matrices and the depth map of the source view to obtain a target semantic graph and a target characteristic graph corresponding to each pose transformation matrix. And moreover, the plurality of corresponding target semantic graphs and the plurality of target characteristic graphs obtained according to the continuous pose transformation matrix have continuity.
Specifically, multiple continuous images of the same three-dimensional scene from different viewing angles can be acquired through multiple continuous pose transformation matrices, that is, multiple target images can be acquired through the pose transformation matrices. In one possible implementation, for example, in the case of unknown pose, the image sequence may be processed by using a Visual Odometer (VO) or a Direct Sparse Odometer (DSO) to obtain pose data [ R | t ] corresponding to each image]={[R|t]1,[R|t]2,…,[R|t]nWherein, [ R | t }]1Represents the pose of the first image, [ R | t]nRepresenting the pose of the nth image.
Optionally, for each pose transformation matrix of the plurality of consecutive pose transformation matrices of the source view, the semantic map and the feature map are transformed according to the pose transformation matrix and the depth map, respectively, and the method may further include the following steps:
calculating the coordinate of each pixel in the first image frame by the following formula respectively aiming at each pixel in the feature map and the semantic map:
[pt]=dK[R|t]K-1[ps]
[R|t]=[Rs|ts]-1[Rt|tt]
where d represents the depth value at the pixel in the depth map, K represents the camera's internal parameters, [ R | t [ ]]A pose transformation matrix representing the source view relative to the first image frame, R representing rotation, t representing translation, [ R ] Rs|ts]、[Rt|tt]Respectively representing the poses of the camera under the source view and the first image frame in a world coordinate system, psRepresenting the coordinates of the pixel under the source view, ptRepresenting the coordinates under the first image frame.
By adopting the calculation method, each pixel point in the feature map and the semantic map of the source view can be mapped into the first image frame through the pose transformation matrix. The first image frame may be any one of the above target feature maps and target semantic maps. Therefore, under the condition that the pose sequence of the image is known, the image in another arbitrary pose can be obtained according to the image corresponding to any pose.
In a possible implementation manner, two adjacent poses can be further divided into N equal parts according to requirements, for example, the pose [ R | t |)]1And pose [ R | t]2The pose change between the positions is divided into N equal parts to obtain N-1 new pose data. And then selecting any pose data in the segmented pose data as the pose of the target view. Then, through the above calculation method, the language of any target view is calculated according to the semantic graph and the feature graph of the source viewSense graph and feature graph. This method may be used to insert more image frames between two adjacent image frames.
In addition, the coordinate p obtained by the position and orientation transformation matrix transformationtIt is not an integer, so the values in 4 neighboring regions can also be resampled using bilinear interpolation to make the transformed image smoother.
And S104, respectively generating image frames according to the target semantic graph and the target characteristic graph corresponding to each pose transformation matrix to obtain a plurality of continuous image frames.
Wherein each of the image frames and the source view are images of the same object from different perspectives. That is, each of the image frames and the source view are images at different poses for the same three-dimensional scene.
In step S104, an image frame may be generated according to the target semantic graph and the target feature graph corresponding to one source view, or according to the target semantic graphs and the target feature graphs corresponding to multiple source views. For example, the above calculation method used in the embodiment of step S103 may be used to insert more image frames between two adjacent image frames. Then, that is to say, when two image frames are known and more images are inserted between the two image frames, images in the same pose can be acquired according to the two known image frames. And then synthesizing the two images in the same pose into one image in the pose, namely the target image frame. Therefore, more characteristic information of the image in the same pose can be acquired through the two pose images. Therefore, the obtained image under the target pose can be more real. Thereby making the generated image frame more realistic.
And S105, synthesizing the plurality of continuous image frames into a video.
By adopting the method, the semantic graphs and the feature graphs of the source view are geometrically transformed through the continuous pose sequence and the depth graphs corresponding to the source view, so that a plurality of continuous target semantic graphs and a plurality of continuous target feature graphs can be respectively obtained, and then the plurality of target semantic graphs and the corresponding target feature graphs are respectively synthesized into a plurality of continuous image frames. These successive image frames are then combined into a video. By adopting the method, the three-dimensional structure of the invisible area can be deduced by utilizing the depth map, the semantic map and the characteristic map of the source view, and the real texture of the invisible area is kept, so that the generated image frame is clearer and more vivid. Therefore, the video synthesized by using the image frame is more vivid, and the stability of the video is improved. In addition, with this method, since a plurality of consecutive image frames are generated after the image of the source view, this method can also be used to insert more image frames between two consecutive image frames. For example, more image frames are inserted into the first and second frames of the video. Therefore, the video can contain more image frames, the frame rate of the video is improved, and the frame rate of the camera is indirectly improved, so that the video can be smoother, and the continuity of the video is improved.
Optionally, the image frames are respectively generated according to the object semantic graph and the object feature graph corresponding to each pose transformation matrix, and the method may further include the following steps:
and performing optimization processing according to the target semantic graph and the target characteristic graph corresponding to each pose transformation matrix, wherein the optimization processing comprises the following steps: hole filling and distortion correction;
and respectively generating the image frames according to the optimized target semantic graph and the optimized target characteristic graph corresponding to each pose transformation matrix.
In the process of obtaining the target semantic graph and the target characteristic graph through pose transformation matrix transformation, as an invisible area exists in an image, namely the invisible area is formed by shielding of a foreground object under the current view angle, the invisible area may be visible under the view angle of a target view under the view angle of a source view, and then a pixel missing part, namely a hole, may exist in the target semantic graph and the target characteristic graph obtained through transformation. To solve this problem, in the method of the present disclosure, the hole filling may be performed on the target semantic graph and the target feature graph through an optimization network. In addition, when calculating the coordinates of each pixel point in the target semantic graph and the target characteristic graph, the coordinates of each pixel point in the target semantic graph and the target characteristic graph can be calculatedErrors can occur, and the coordinates of pixel points have errors, so that scenery in the image is distorted. Therefore, in the method of the present disclosure, the distorted image can be corrected by the optimization process. Specifically, an optimization network may be adopted to perform optimization processing on the image, where a loss function of the optimization network is:
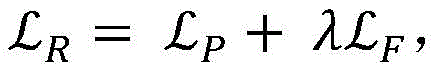
wherein,
representing the overall penalty of optimizing the network,
representing the loss of the pixel L1,
representing a loss of perception, and λ represents a hyper-parameter.
For the
The features of the generated image and the real image can be extracted using a deep convolutional network (VGG network for large-scale image recognition), and the L1 loss between the two, i.e., the average absolute error, can be calculated as the loss
The numerical value of (c).
By adopting the method, the hole filling and distortion correction are carried out on the target semantic graph and the target characteristic graph, so that the optimized image is more vivid.
In addition, it should be noted that the target image frame may be optimized by using various estimation methods. The multiple kinds of estimation refer to a method for performing pose transformation according to a plurality of source views at different poses to estimate a plurality of target views at the same pose. The reason is that the information of the same three-dimensional scene seen through different viewing angles, namely different poses, is different, and specifically, when the same three-dimensional scene is seen through different viewing angles, the invisible area caused by the shielding of a foreground object is different due to the different viewing angles, so that the target image can be subjected to multiple kinds of conjectures through the image frames before and after the target image frame, and thus, the multiple kinds of information from the images under different poses can be integrated, and the information of the invisible area in the source view can be more accurately conjectured, so that the generated target image sequence is more vivid, and the generated video is more vivid and smooth.
Optionally, when the image frames are respectively generated according to the target semantic graph and the target feature graph corresponding to each pose transformation matrix to obtain a plurality of continuous image frames, the method may further include the following steps:
and aiming at the target semantic graph and the target characteristic graph corresponding to each pose transformation matrix, inputting the target semantic graph and the target characteristic graph into a generator network in a generation countermeasure network to obtain an image frame corresponding to the pose transformation matrix.
It will be appreciated by those skilled in the art that high resolution and texture-realistic images can be synthesized by generating a competing network. Specifically, the generation countermeasure network includes a generator network and an arbiter network. The purpose of generating the countermeasure network is to generate spurious samples even if the samples generated by the generator network are authentic, so that the ability of the discriminator network is insufficient to discriminate between authentic samples and generated false samples. Wherein, in the present disclosure, this sample refers to an image.
Optionally, the loss function that generates the countermeasure network is:
wherein λ is
FFor overriding, for controlling feature matching loss
Of importance, λ
WThe method is a super-ginseng method,
representing image loss in an image discriminator network, the loss function of the image discriminator network being:
representing image loss in a video discriminator network, the loss function of the video discriminator network being:
and, the function of the feature matching penalty is:
wherein G represents a generator network, D represents a discriminator network, D
kRepresenting a multi-scale network of discriminators, k representing the number of said multi-scale network of discriminators, D
1,D
2The multi-scale discriminator networks representing two different scales respectively,
representing a kth of the multi-scale discriminator networks in the image discriminator network,
representing the kth multi-scale discriminator network in the video discriminator network, s representing a source view, x representing a target view, N representing the number of layers of a perceptron, N representing the number of layers of a perceptron
iRepresenting the number of elements per layer, i represents the layer number,
multi-scale discriminator network D corresponding to characteristic extractor of representative i-th layer
k,|| ||
1Representing a 1 norm, GAN representing the generation of a countermeasure network;
represents the optical flow loss, the function of which is:
where T represents the number of image sequences, w
t、
Respectively representing the real and predicted optical flows, x, between the t-th and t + 1-th frames of the image sequence
t+1An image representing a t +1 frame,
representing combined optical flow information, x
tFrame image mapping to x
t+1An image corresponding to the frame;
the training to generate the countermeasure network is an alternating training that maximizes and minimizes the loss function by:
it is worth to say that in the present solution a multi-scale discriminator is used, in particular a multi-scale image discriminator DIAnd multi-scale video discriminationDevice DVThe use of a multi-scale discriminator facilitates convergence of the network and speeds up training, and may reduce repetitive blocky regions on the generated target image.
In addition, in order to maintain the space-time consistency of the generated image frame, the source view image is sent to a generation countermeasure network, the optical flow is predicted, and the loss between the predicted optical flow and the real optical flow is compared. Those skilled in the art will appreciate that Optical Flow can be learned using a Convolutional network (called "Flow net" for short).
In this way, true information of the three-dimensional scene may be preserved with image frames generated by the generation countermeasure network, and prediction using optical flow may also enhance the spatiotemporal continuity between the generated image frames and preceding and following image frames.
In summary, with the method of the present disclosure, the three primary color images of the source view are used as input, and an image with any pose is generated according to the depth map, the feature map, the semantic map of the source view and the pose transformation matrix of the target view. And the generated image is optimized, and the spatial consistency of the generated image and the source view can be kept by combining the prediction of the optical flow. The three-dimensional structure of the invisible area can be deduced by utilizing the depth map, the semantic map and the characteristic map of the source view, and the real texture of the invisible area is kept, so that the generated image frame is clearer and more vivid. Therefore, the video generated by the method is more vivid and has better stability. In addition, it should be noted that the method of the present disclosure may be applied to vSLAM mapping, VO positioning, 3D reconstruction, and the like, and the present disclosure does not limit this. For example, if the frame rate of images acquired by the camera is too low, initialization of the vSLAM may be affected, so that the vSLAM mapping is interrupted, and the mapping effect is poor; for another example, the VO determines the position and posture of each frame of data shot by the camera by analyzing and processing the related image sequence, and if the frame rate of the camera is increased, the positioning accuracy and stability of the VO are improved; for another example, in the visual 3D reconstruction, image data of an object in a scene is mainly acquired by a camera, and the image is analyzed and processed, and a three-dimensional model of the object is reconstructed by combining computer vision and graphics technologies. If the frame rate of the collected images is increased, the difference between two adjacent frames of images can be small, and thus, the accuracy of the model can be improved. Therefore, by adopting the method, the filling of data between image frames can be realized, and the frame rate of the camera is indirectly improved, so that the continuity and stability of the video are improved, and the accuracy and robustness of vSLAM, VO and 3D reconstruction are further improved.
The embodiment of the present disclosure further provides a device for generating a video, which is used to implement the steps of the method for generating a video provided by the foregoing method embodiment. As shown in fig. 2, the apparatus 200 includes:
the first obtaining module 210 is configured to input the three primary color images of the source view into a depth and semantic network, and obtain a depth map and a semantic map output by the depth and semantic network;
a second obtaining module 220, configured to input the semantic graph and the three primary color images into a feature encoder network to obtain a feature graph output by the feature encoder network;
a transformation module 230, configured to, for each pose transformation matrix in a plurality of consecutive pose transformation matrices of the source view, respectively transform the semantic graph and the feature graph according to the pose transformation matrix and the depth map, so as to obtain a target semantic graph and a target feature graph corresponding to each pose transformation matrix, where the plurality of consecutive pose transformation matrices are respective pose transformation matrices of the source view with respect to a plurality of consecutive image frames;
a generating module 240, configured to generate an image frame according to a target semantic map and a target feature map corresponding to each pose transformation matrix, respectively, to obtain multiple continuous image frames, where each image frame and the source view are images of the same object from different perspectives;
a synthesizing module 250, configured to synthesize the plurality of consecutive image frames into a video.
By adopting the device, the semantic graph and the feature graph of the source view are geometrically transformed through the continuous pose sequence and the depth graph corresponding to the source view, so that a plurality of continuous target semantic graphs and a plurality of continuous target feature graphs can be respectively obtained, and then the plurality of target semantic graphs and the corresponding target feature graphs are respectively synthesized into a plurality of continuous image frames. These successive image frames are then combined into a video. By adopting the device, the three-dimensional structure of the invisible area can be deduced by utilizing the depth map, the semantic map and the characteristic map of the source view, and the real texture of the invisible area is kept, so that the generated image frame is clearer and more vivid. Therefore, the video generated by the device is more vivid and has better stability. In addition, since a plurality of consecutive image frames are generated after the image frame of the source view, it is also possible to use this apparatus for inserting more image frames between two consecutive or non-consecutive image frames in the video. Therefore, the generated video can contain more image frames, the frame rate of the video is improved, and the frame rate of the camera is indirectly improved, so that the video can be smoother, and the continuity of the video is improved.
Optionally, as shown in fig. 3, the transformation module 230 further includes:
a calculating submodule 231, configured to calculate, for each pixel in the feature map and the semantic map, a coordinate of the pixel in the first image frame by using the following formula:
[pt]=dK[R|t]K-1[ps]
[R|t]=[Rs|ts]-1[Rt|tt]
where d represents the depth value at the pixel in the depth map, K represents the camera's internal parameters, [ R | t [ ]]A pose transformation matrix representing the source view relative to the first image frame, R representing rotation, t representing translation, [ R ] Rs|ts]、[Rt|tt]Respectively representing the poses of the camera under the source view and the first image frame in a world coordinate system, psRepresenting the coordinates of the pixel under the source view, ptRepresenting the coordinates under the first image frame.
Optionally, as shown in fig. 3, the generating module 240 further includes:
the optimizing submodule 241 is configured to perform optimization processing according to the target semantic graph and the target feature graph corresponding to each pose transformation matrix, where the optimization processing includes: hole filling and distortion correction;
the first generating sub-module 242 is configured to generate the image frames according to the optimized target semantic graph and the optimized target feature graph corresponding to each pose transformation matrix, respectively.
Optionally, as shown in fig. 3, the generating module 240 further includes:
the second generating sub-module 243 is configured to, for the target semantic map and the target feature map corresponding to each pose transformation matrix, input the target semantic map and the target feature map into a generator network in a generation countermeasure network, so as to obtain the image frame corresponding to the pose transformation matrix.
Optionally, the loss function that generates the countermeasure network is:
wherein λ is
FFor overriding, for controlling feature matching loss
Of importance, λ
WThe method is a super-ginseng method,
representing image loss in an image discriminator network, the loss function of the image discriminator network being:
representing image loss in a video discriminator network, the loss function of the video discriminator network being:
and, the function of the feature matching penalty is:
wherein G represents a generator network, D represents a discriminator network, D
kRepresenting a multi-scale network of discriminators, k representing the number of said multi-scale network of discriminators, D
1,D
2The multi-scale discriminator networks representing two different scales respectively,
representing a kth of the multi-scale discriminator networks in the image discriminator network,
representing the kth multi-scale discriminator network in the video discriminator network, s representing a source view, x representing a target view, N representing the number of layers of a perceptron, N representing the number of layers of a perceptron
iRepresents the number of elements of each layer,
multi-scale discriminator network D corresponding to characteristic extractor of representative i-th layer
k,|| ||
1Representing a 1 norm, GAN representing the generation of a countermeasure network;
represents the optical flow loss, the function of which is:
where T represents the number of image sequences, w
t、
Respectively representing the real and predicted optical flows, x, between the t-th and t + 1-th frames of the image sequence
t+1An image representing a t +1 frame,
representing combined optical flow information, x
tFrame image mapping to x
t+1An image corresponding to the frame;
the training to generate the countermeasure network is an alternating training that maximizes and minimizes the loss function by:
the present disclosure also provides a computer readable storage medium having stored thereon computer program instructions which, when executed by a processor, implement the steps of a method of generating video provided by the present disclosure.
Fig. 4 is a block diagram illustrating an electronic device 400 according to an example embodiment. As shown in fig. 4, the electronic device 400 may include: a processor 401 and a memory 402. The electronic device 400 may also include one or more of a multimedia component 403, an input/output (I/O) interface 404, and a communications component 405.
The processor 401 is configured to control the overall operation of the electronic device 400, so as to complete all or part of the steps in the above-mentioned method for generating a video. The memory 402 is used to store various types of data to support operation at the electronic device 400, such as instructions for any application or method operating on the electronic device 400 and application-related data, such as contact data, transmitted and received messages, pictures, audio, video, and so forth. The Memory 402 may be implemented by any type of volatile or non-volatile Memory device or combination thereof, such as Static Random Access Memory (SRAM), Electrically Erasable Programmable Read-Only Memory (EEPROM), Erasable Programmable Read-Only Memory (EPROM), Programmable Read-Only Memory (PROM), Read-Only Memory (ROM), magnetic Memory, flash Memory, magnetic disk or optical disk. The multimedia components 403 may include a screen and an audio component. Wherein the screen may be, for example, a touch screen and the audio component is used for outputting and/or inputting audio signals. For example, the audio component may include a microphone for receiving external audio signals. The received audio signal may further be stored in the memory 402 or transmitted through the communication component 405. The audio assembly also includes at least one speaker for outputting audio signals. The I/O interface 404 provides an interface between the processor 401 and other interface modules, such as a keyboard, mouse, buttons, etc. These buttons may be virtual buttons or physical buttons. The communication component 405 is used for wired or wireless communication between the electronic device 400 and other devices. Wireless Communication, such as Wi-Fi, bluetooth, Near Field Communication (NFC), 2G, 3G, 4G, NB-IOT, eMTC, or other 5G, etc., or a combination of one or more of them, which is not limited herein. The corresponding communication component 405 may therefore include: Wi-Fi module, Bluetooth module, NFC module, etc.
In an exemplary embodiment, the electronic Device 400 may be implemented by one or more Application Specific Integrated Circuits (ASICs), Digital Signal Processors (DSPs), Digital Signal Processing Devices (DSPDs), Programmable Logic Devices (PLDs), Field Programmable Gate Arrays (FPGAs), controllers, microcontrollers, microprocessors, or other electronic components for performing the steps of one of the above-described methods of generating video.
In another exemplary embodiment, a computer readable storage medium comprising program instructions which, when executed by a processor, implement the steps of a method of generating video as described above is also provided. For example, the computer readable storage medium may be the memory 402 described above comprising program instructions executable by the processor 401 of the electronic device 400 to perform a method of generating video described above.
Other embodiments of the disclosure will be apparent to those skilled in the art from consideration of the specification and practice of the disclosure. This application is intended to cover any variations, uses, or adaptations of the disclosure following, in general, the principles of the disclosure and including such departures from the present disclosure as come within known or customary practice within the art to which the disclosure pertains. It is intended that the specification and examples be considered as exemplary only, with a true scope and spirit of the disclosure being indicated by the following claims.
It will be understood that the present disclosure is not limited to the precise arrangements described above and shown in the drawings and that various modifications and changes may be made without departing from the scope thereof. The scope of the present disclosure is limited only by the appended claims.
The preferred embodiments of the present disclosure are described in detail with reference to the accompanying drawings, however, the present disclosure is not limited to the specific details of the above embodiments, and various simple modifications may be made to the technical solution of the present disclosure within the technical idea of the present disclosure, and these simple modifications all belong to the protection scope of the present disclosure.
It should be noted that, in the foregoing embodiments, various features described in the above embodiments may be combined in any suitable manner, and in order to avoid unnecessary repetition, various combinations that are possible in the present disclosure are not described again.
In addition, any combination of various embodiments of the present disclosure may be made, and the same should be considered as the disclosure of the present disclosure, as long as it does not depart from the spirit of the present disclosure.