Kho lưu trữ này chứa mã nguồn để phát triển, tiền huấn luyện và tinh chỉnh một mô hình ngôn ngữ lớn (LLM) giống GPT và là kho mã chính thức cho cuốn sách [Quy trình phát triển mô hình ngôn ngữ lớn LLMs]
Trong [Quy trình phát triển mô hình ngôn ngữ lớn LLMs], bạn sẽ học và hiểu cách các mô hình ngôn ngữ lớn (LLMs) hoạt động từ bên trong bằng cách mã hóa chúng từ đầu, từng bước một. Trong cuốn sách này, tôi sẽ hướng dẫn bạn tạo ra LLM của riêng mình, giải thích từng giai đoạn với văn bản rõ ràng, sơ đồ và ví dụ.
Phương pháp được mô tả trong cuốn sách này để huấn luyện và phát triển mô hình nhỏ nhưng chức năng cho mục đích giáo dục phản ánh cách tiếp cận được sử dụng trong việc tạo ra các mô hình nền tảng quy mô lớn như những mô hình đằng sau ChatGPT. Ngoài ra, cuốn sách này còn bao gồm mã để tải trọng số của các mô hình đã được tiền huấn luyện lớn hơn để tinh chỉnh.
<<<<<<< HEAD
- Liên kết đến kho mã nguồn chính thức
Để tải bản sao của kho lưu trữ này,thực hiện lệnh sau trong terminal của bạn:
git clone --depth 1 https://github.com/aerovfx/Aero-HowtoLLMsXin lưu ý rằng tệp README.md này là tệp Markdown (.md). Nếu bạn đã tải gói mã này từ trang web của Manning và đang xem nó trên máy tính của mình, tôi khuyên bạn nên sử dụng trình soạn thảo hoặc trình xem trước Markdown để xem đúng cách. Nếu bạn chưa cài đặt trình soạn thảo Markdown, MarkText là một lựa chọn miễn phí tốt.
Tip
Nếu bạn đang tìm kiếm hướng dẫn về cài đặt Python và các gói Python cũng như thiết lập môi trường mã, tôi đề xuất đọc tệp README.md nằm trong thư mục setup.
| Tiêu đề chương | Mã chính (truy cập nhanh) | Tất cả mã + bổ sung |
|---|---|---|
| Khuyến nghị thiết lập | - | - |
| Ch 1: Hiểu về các mô hình ngôn ngữ lớn | Không có mã | - |
| Ch 2: Làm việc với dữ liệu văn bản | - ch02.ipynb - dataloader.ipynb (tóm tắt) - exercise-solutions.ipynb |
./ch02 |
| Ch 3: Mã hóa cơ chế chú ý | - ch03.ipynb - multihead-attention.ipynb (tóm tắt) - exercise-solutions.ipynb |
./ch03 |
| Ch 4: Triển khai mô hình GPT từ đầu | - ch04.ipynb - gpt.py (tóm tắt) - exercise-solutions.ipynb |
./ch04 |
| Ch 5: Tiền huấn luyện trên dữ liệu không gán nhãn | - ch05.ipynb - gpt_train.py (tóm tắt) - gpt_generate.py (tóm tắt) - exercise-solutions.ipynb |
./ch05 |
| Ch 6: Tinh chỉnh cho phân loại văn bản | - ch06.ipynb - gpt_class_finetune.py - exercise-solutions.ipynb |
./ch06 |
| Ch 7: Tinh chỉnh để làm theo hướng dẫn | - ch07.ipynb - gpt_instruction_finetuning.py (tóm tắt) - ollama_evaluate.py (tóm tắt) - exercise-solutions.ipynb |
./ch07 |
| Phụ lục A: Giới thiệu về PyTorch | - code-part1.ipynb - code-part2.ipynb - DDP-script.py - exercise-solutions.ipynb |
./appendix-A |
| Phụ lục B: Tài liệu tham khảo và đọc thêm | Không có mã | - |
| Phụ lục C: Giải pháp bài tập | Không có mã | - |
| Phụ lục D: Thêm các tính năng vào vòng lặp huấn luyện | - appendix-D.ipynb | ./appendix-D |
| Phụ lục E: Tinh chỉnh hiệu quả với LoRA | - appendix-E.ipynb | ./appendix-E |
Mô hình tinh thần dưới đây tóm tắt các nội dung được đề cập trong cuốn sách này.
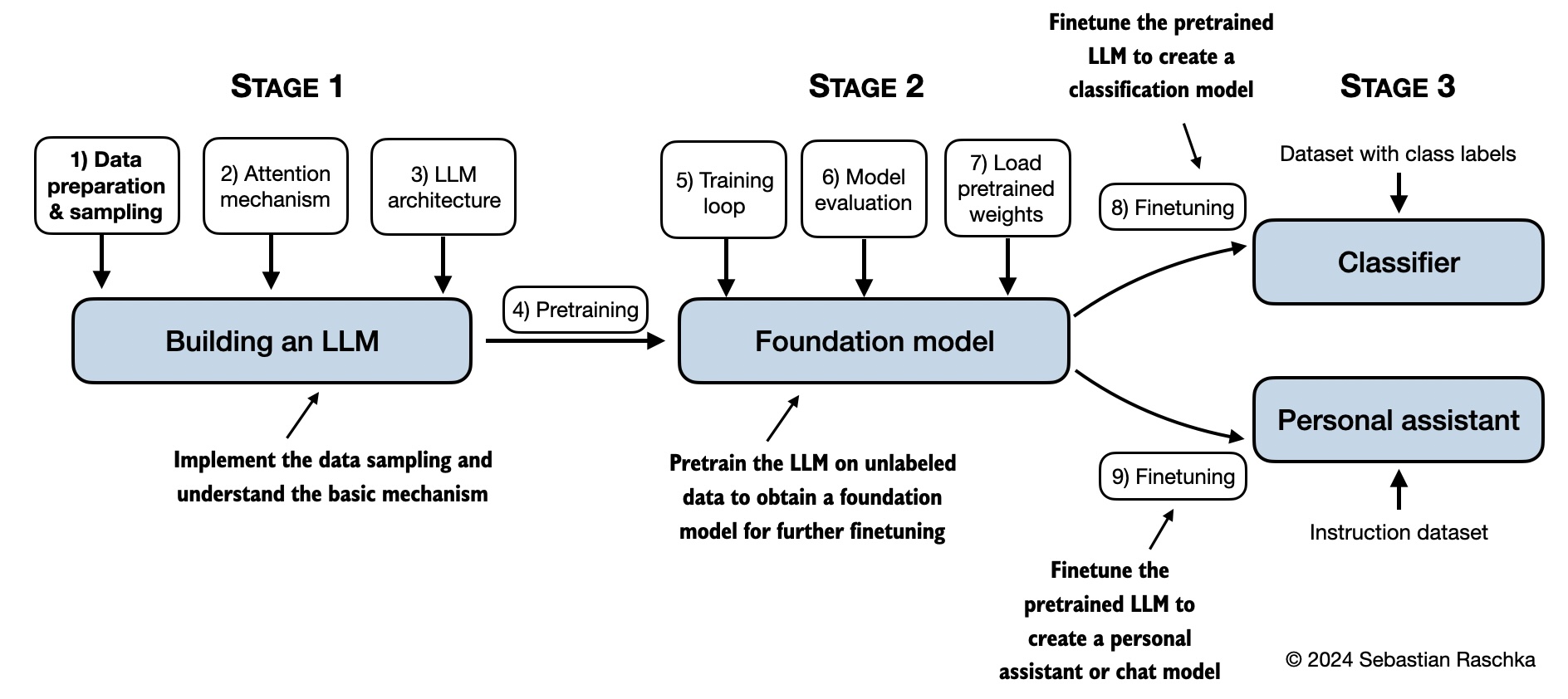
Mã trong các chương chính của cuốn sách này được thiết kế để chạy trên các máy tính xách tay thông thường trong thời gian hợp lý và không yêu cầu phần cứng chuyên dụng. Cách tiếp cận này đảm bảo rằng một lượng lớn độc giả có thể tham gia vào tài liệu. Ngoài ra, mã tự động sử dụng GPU nếu có sẵn. (Vui lòng xem tài liệu setup để biết thêm các khuyến nghị.)
Một số thư mục chứa tài liệu tùy chọn như một phần thưởng cho các độc giả quan tâm:
- Thiết lập
- Chương 2: Làm việc với dữ liệu văn bản
- Chương 3: Mã hóa cơ chế chú ý
- Chương 4: Triển khai mô hình GPT từ đầu
- Chương 5: Tiền huấn luyện trên dữ liệu không gán nhãn:
- Tải trọng số thay thế từ Hugging Face Model Hub sử dụng Transformers
- Tiền huấn luyện GPT trên tập dữ liệu Project Gutenberg
- Thêm các tính năng vào vòng lặp huấn luyện
- Tối ưu hóa siêu tham số cho tiền huấn luyện
- Xây dựng giao diện người dùng để tương tác với LLM đã tiền huấn luyện
- Chuyển đổi GPT sang Llama
- Llama 3.2 từ đầu
- Tải trọng số mô hình hiệu quả về bộ nhớ
- Mở rộng bộ mã hóa BPE Tiktoken với các token mới
- Chương 6: Tinh chỉnh cho phân loại
- Chương 7: Tinh chỉnh để làm theo hướng dẫn
- Tiện ích tập dữ liệu để tìm các bản sao gần và tạo các mục giọng bị động
- Đánh giá phản hồi hướng dẫn sử dụng API OpenAI và Ollama
- Tạo tập dữ liệu cho tinh chỉnh hướng dẫn
- Cải thiện tập dữ liệu cho tinh chỉnh hướng dẫn
- Tạo tập dữ liệu ưu tiên với Llama 3.1 70B và Ollama
- Tối ưu hóa ưu tiên trực tiếp (DPO) cho căn chỉnh LLM
- Xây dựng giao diện người dùng để tương tác với mô hình GPT tinh chỉnh hướng dẫn
======= Kết luận Việc xây dựng một mô hình ngôn ngữ lớn là một quá trình phức tạp, đòi hỏi sự kết hợp của nhiều công nghệ tiên tiến và nguồn lực tính toán lớn. Sự phát triển của LLMs mở ra nhiều cơ hội trong các lĩnh vực như trợ lý ảo, sáng tạo nội dung, dịch thuật, và nghiên cứu khoa học, nhưng cũng đặt ra nhiều thách thức về kiểm soát và đạo đức trong AI.
Overview of LLMs in Production
- Q&A Webapp
- Chatbot
- Model as an API
- Corpus Creation
- Text Pre Processing
- Prompt Engineering
- LLM Inference
- Generated Text
- GPT 3.5
- GPT 4.0
- LLaMA
- Hugging Face
- MPT
ab450f3d2e36437ab263df67da2a0772d02798e2